
数据科学不再遥不可及 —— 数据整理Data Munging
本文来自Dan Kellett 发表在analyticbridge的一篇博文。
Dan Kellett, Director of Data Science, Capital One UK
原文标题:Makingdata science accessible – Data Munging
90%的时间,数据科学家们并非花时间在建立炫酷的模型上。做任何分析,最难也最花时间的部分都在数据整理。
// 什么是数据整理
数据整理是指获取原数据,理解这些数据,清洗它们,并准备好建模的过程。这显然并不是数据科学的华彩部分,但如果这部分做好的话,比选择好的算法更有利于建立强大的模型,获得洞见。
// 一切之先
当你拿到新的数据,并希望建模来了解这些数据的特性,很容易立刻开始做回归分析或者机器学习——但这是错误的。第一步应该是认真理解数据,从单量着手,慢慢展开到多量。核心统计量比如中数,还有box-and-whisker图可以帮助你更容易地从视觉上理解数据,并且知道需要在建模之前解决的潜在问题。

// 数据类型
了解你的数据类型是什么以及它们应该是什么类型非常重要。你或许会有独特的数据编号(比如账号)。这样的数据被当作数字类读进来是很有可能的。然而,并不一定002号数据就比101号数据和001号数据更相关。相似的,一些描述性的数据最好转换成序数。比如说,在问卷调查中,“同意”、“中立”和“不同意”这三个答案就有隐藏的先后次序。最后,如果你的数据里面有时间——那么尽情享受吧!当你能够熟练地处理时间数据时,你会获得各种各样的好机会。当然,这些都取决于你对数据的真正了解以及你怎么去探索你所有的数据。
// 缺失数据
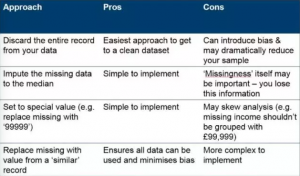
在现实世界里,拥有完整数据的可能性是极小的。数据缺失有很多原因,比如说没有这样的数据,没有提相关问题,搜集数据过程中出错,等等。处理缺失数据的第一步是明白为什么数据缺失了,只有这样你才可以做适当的处理。或许在某些情况下最好的处理缺失数据的方式就是彻底删除数据,但这样做的风险就是给你的模型带来偏差。通常用的方法是填充缺失数据,填充一个统计量(比如中数),或者为缺失数据创建一个特殊的值。
// 基数高
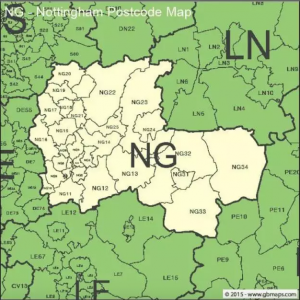
有一些分类数据基数会过高——取值太多(比如说邮政编码或者职位名称)。基数高的分类数据在建模过程中容易造成小样本过度拟合的问题。这个时候领域知识就特别重要了,因为领域知识可以帮助我们重组分类。比如说,如果你了解英国的地理分区,你就可以用比邮政编码更好的量来描述分区。下图就是例子:如果用邮政编码来分区,你会把NG20和NG23分在一起;然而地理上来看,将NG23和LN6分在一起更好。领域知识并不总是有的,在这种情况下你就要使用数据的方法来分组,比如说聚类法。
// 异常值
并非所有的数据都服从正态分布。有时候你的数据存在异常值,会潜在地让你的结果出现偏差。比如考虑收入这个数据:如果你的样本里面有亿万富翁,均值会受到极大的影响(这个时候最好看一看中数和百分位数,而不是均值)。想要建好模型,了解你的数据范围,设定最大值最小值限度是很重要的。
—
以上我提到了一些整理数据的关键点。这些并不完整,但重点是:如果你对你的数据没有透彻的了解,你如何能相信你所做出的结论呢?
If you are interested in finding out more about the company, please visit https://www.capitalone.co.uk/





