
快速上手Pandas数据结构合并
在本教程中,我们将通过示例来了解合并Pandas DataFrames的不同方法。如果你想了解更多关于数据分析的相关内容,可以阅读以下这些文章:
数据分析在Supply Chain方向有哪些应用?
顺利拿到数据分析师OFFER的作品集长什么样?
Excel小能手们,如何让自己数据分析及汇报的能力再上一层楼?
一篇文章带你了解探索性数据分析
#介绍
在许多现实生活场景中,为了便于管理,我们将数据存储在不同的文件中,经常需要将它们合并成一个更大的DataFrame进行分析。Pandas为我们提供了各种方法来合并DataFrame,如concat和merge。此外,它还提供了用于比较的实用程序。
我们将通过示例来了解这两种方法的工作原理。对于本教程,我们将假设你具备Python和Pandas的基本知识。
#连接DataFrame
如果两个DataFrame格式相同,我们选择.concat()方法。它将一个DataFrame中的列或行附加到另一个DataFrame。.concat ()沿轴执行连接操作。在深入讨论其细节之前,我们快速了解一下语法及其参数。
pd.concat(objs,axis=0,join="outer",ignore_index=False,keys=None,
levels=None,names=None,verify_integrity=False,copy=True,)这里只关注主要参数:
- objs :要连接的DataFrame对象或Series的列表。
- axis :axis = 0 意味着pandas将第二个DataFrame堆叠在第一个DataFrame下方(按行连接),而axis =1意味着pandas将第二个DataFrame堆叠到第一个 DataFrame的右侧(按列连接)。默认情况下,axis = 0。
- join:默认join=outer,outer用于union,inner用于intersection。
- ignore_index:它会在连接过程中忽略索引,默认情况下,它为False。但如果索引没有意义,则忽略它们是有用的。
- verify_integrity:它检查新连接轴中的重复项,但默认情况下,它为False。
示例:
import pandas as pd
# First Dict with two 2 and 4 columns
data_one = {'A' : ['A1','A2','A3','A4'] , 'B' : ['B1','B2','B3','B4']}
# Second Dict with two 2 and 4 columns
data_two = {'C' : ['C1','C2','C3','C4'] , 'D' : ['D1','D2','D3', 'D4']}
# Converting to DataFrames
df_one=pd.DataFrame(data_one)
df_two=pd.DataFrame(data_two)
#场景 1:按列连接
假设A、B、C和D列代表不同的功能,但索引相同,则将C和D行连接到df_one 右侧更有意义。
# Joining the columns
new_df = pd.concat([df_one,df_two],axis=1)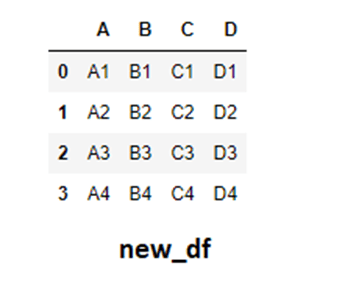
#场景 2:按行连接
如果我们继续上述假设并按行将它们连接起来,那么生成的DataFrame将包含大量NaN值缺失数据。原因很简单,假设df_two中index = 0我们不能将它直接放在A列和B列下面,因为我们认为它们是值不存在的不同的函数。因此,pandas 将自动为A、B、C和D创建一个完整的行,它们各自的列中缺少值。
# Joining the rows
new_df1 = pd.concat([df_one,df_two],axis=0)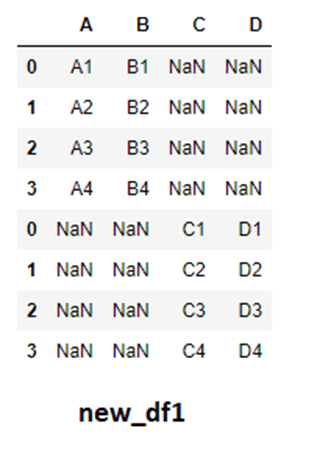
请注意,我们的最终结果中有重复索引。因为默认情况下,ignore_index = False,它将DataFrame的索引保存为原始状态。这在我们的例子中可能没有用,所以我们将设置ignore_index = True。
# Joining the rows
new_df2 = pd.concat([df_one,df_two],axis=0 , ignore_index= True)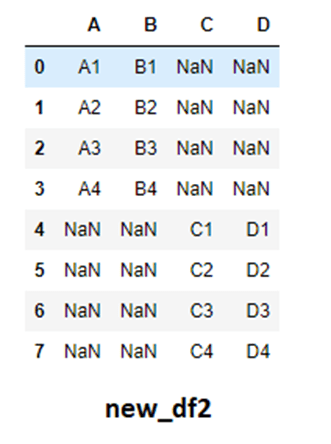
如果两个DataFrame中的列表示相同的东西,只是命名不同,那么我们可以在连接之前重命名这些列。
# Joining the rows
df_two.columns = df_one.columns
new_df3 = pd.concat([df_one,df_two],axis=0 , ignore_index= True)
#Merging Dataframes
Merge或Join Dataframes不同于Concat。Concat连接意味着只是沿着所需的轴将一个Dataframe堆叠在另一个Dataframe上。而Join的工作原理与SQL中的连接类似。我们可以根据唯一列组合Dataframe,这些方法性能明显更好。当一个 DataFrame是“查找表”时,它非常有用,其中包含我们想要连接到另一个的附加数据。我们来看看它的语法和参数:
pd.merge( left, right, how="inner", on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=True, suffixes=("_x", "_y"),
copy=True, indicator=False, validate=None)让我们看一下它的主要参数以及它们的用途:
- left:Dataframe对象
- right:Dataframe对象
- how:连接类型,即inner、outer、left、right等。默认how = “inner”
- on:DataFrame中共有的列,构成连接操作的基础。
- left_on:如果使用right_index作为要加入的列,则必须指定将用作键的列。
- right_on:left_on反之亦然
- left_index:如果设置为True,则使用左DataFrame的行标签(索引)作为连接键
- right_index:left_index 的反之亦然
- sort:通过连接键按顺序对生成的DataFrame进行排序,但不建议这样做,因为它会严重影响性能。
- suffixes:如果我们有一个重叠的列,你可以分配后缀来区分它们。默认情况下,它设置为 (‘_x’, ‘_y’)。
示例:
sports和library DataFrame的例子,假设两个DataFrame中的“name”列是唯一的,可以用作主键。
import pandas as pd
# First DataFrame
sports= pd.DataFrame({'sports_id':[1,2,3,4],'name':['Alex','David','James','Sara']})
# Second DataFrame
library= pd.DataFrame({'library_id':[1,2,3,4],'name':['David','James','Peter','Harry']})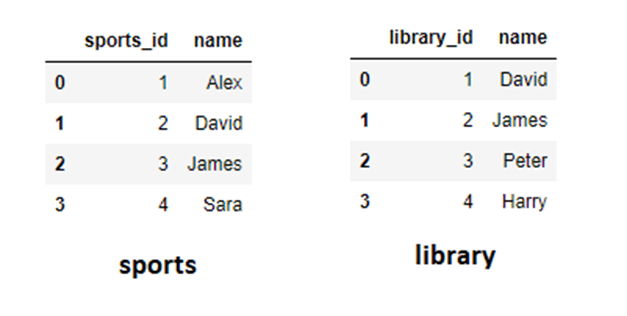
#场景一:Inner内连接和Outer外连接
对于它们两者,在. merge()方法中dataFrame的位置无关紧要,因为最终结果是相同的。如果我们将两个DataFrame视为两个集合,则内连接将引用它们的交集,而外连接将引用它们的并集。
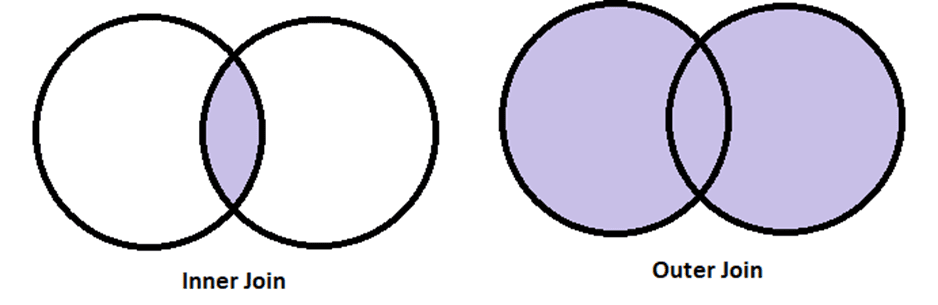
inner_join = pd.merge(sports,library,how="inner",on="name")
outer_join = pd.merge(library,sports,how="outer",on="name")
#场景二:左右连接
在这里,我们放置DataFrame的顺序很重要。例如,在左连接中,放置在左侧位置的DataFrame对象的所有数据将与来自右侧DataFrame对象的匹配数据一起显示。右连接与左连接的作用正好相反。从一个例子中理解这个概念。
left_join = pd.merge(sports,library,how="left",on="name")
right_join= pd.merge(library,sports,how="right",on="name")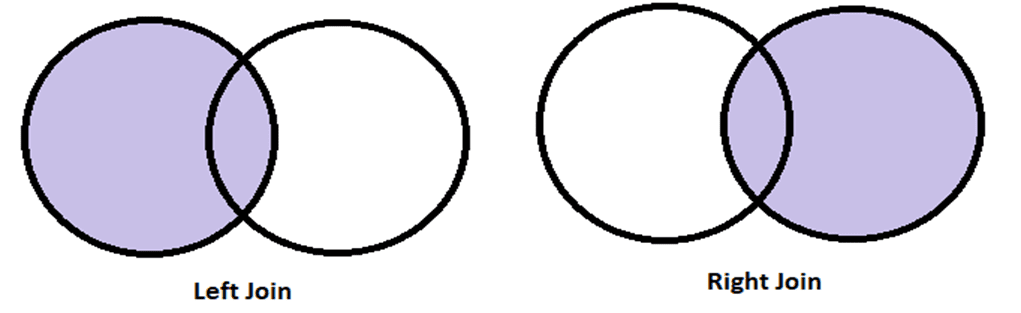
#场景三:使用索引连接
首先,使用set_index()方法修改sports表,使“name”列成为索引。
sports = sports.set_index("name")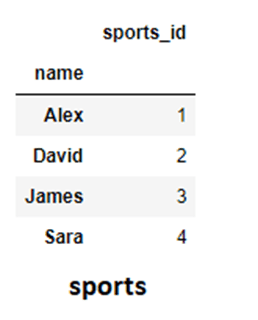
如果现在我们将sports作为我们的左DataFrame,应用inner操作并设置left_index= True。
index_join = pd.merge(sports,library,how="inner",left_index = True, right_on="name")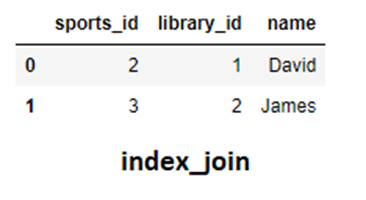
请注意,它显示的结果与我们之前内连接的结果相同。
#场景四:后缀属性
通过将sports_id和login_id更改为id对原始DataFrame进行修改。现在虽然名称相同,但我们指的是不同的id。Pandas可以识别它并添加后缀。稍后将看到如何自定义这些后缀。
# First DataFrame
sports= pd.DataFrame({'id':[1,2,3,4],'name':['Alex','David','James','Sara']})
# Second DataFrame
library= pd.DataFrame({'id':[1,2,3,4],'name':['David','James','Peter','Harry']})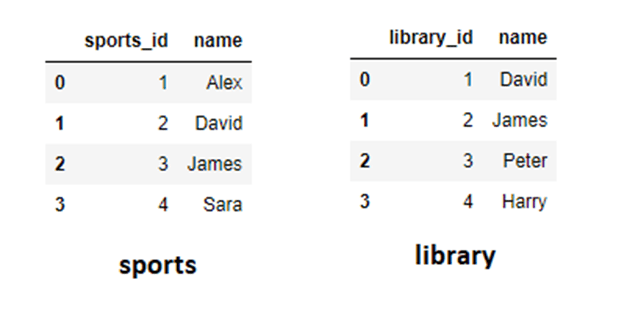
inner_join = pd.merge(sports,library,how="inner",on="name")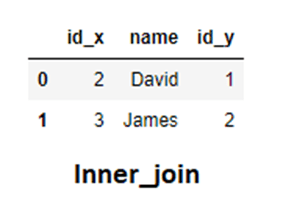
这里id_x指的是左边的DataFrame,而id_y 指的是右边的DataFrame。虽然,它完成了它的工作,但为了代码更清晰,可读性更高,我们使用suffixes属性自定义这些后缀。
suffix_ = pd.merge(sports,library,how="inner",on="name", suffixes=('_sport','_lib'))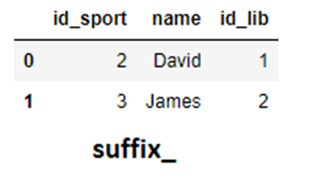
#结论
本文旨在简化Pandas中合并行的概念。当你从.csv文件中提取大规模数据时,建议你开始执行连接操作之前分析一下数据的类型和格式。Pandas在这方面也有一些很好的方法。如有任何问题,请参阅Pandas的官方文档。最后强调,一切都需要实践,你可以自行尝试不同的DataFrame,以便更好地理解,感谢阅读。你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
Kanwal Mehreen是一位有抱负的软件开发人员,她相信持续的努力和承诺。她是一位志向远大的程序员,对数据科学和机器学习领域有着浓厚的兴趣。
原文作者:Kanwal Mehreen
翻译作者:明慧
美工编辑:过儿
校对审稿:Miya
原文链接:https://www.kdnuggets.com/2022/09/combining-pandas-dataframes-made-simple.html





