
数据科学家与数据分析师、数据工程师到底有何差别?
什么是数据科学?数据科学家的主要职责有哪些?
《哈佛商业评论》评出的 21世纪最性感的工作是……??? 没错,就是数据科学家! 神秘的数据科学家!他们的秘密是什么?性感之处在哪里?
这篇文章将定义数据科学家职业角色的方方面面,包括技能,资质,教育背景,经验,职责等。很多人认为数据科学家和数据分析师、数据工程师没什么不同,实则不然。下图显示数据科学家须具备的知识,技能,思维。
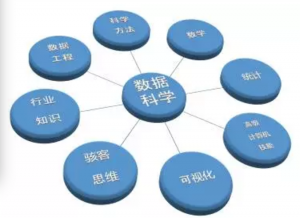
卡尔文∙安卓斯(Calvin.Andrus)
来源:维基媒体公共资源(Wikimedia Commons)
上图列出的八大法宝可进一步归为四大类:
1) 商业洞见
2) 统计概率知识
3) 计算机科学和软件编程技能
4) 文字和视觉沟通能力
能够在上述四大领域都做到出类拔萃的数据科学家实属凤毛麟角,能精通两大领域已然十分难得!
一个优秀的数据科学家应具备利用现有数据资源, 创造新的数据资源, 从新旧数据源中提取有用信息和可行性洞见(actionable insights)的能力。所谓的可行性洞见,指得是能够驱动商业决策,有助于到达商业目标的建议。
八大法宝,一个不少,才能持续不断地为团队提出出奇制胜的可行性洞见!
数据分析师
数据科学家和数据分析师的职责,技能,教育背景有不少重合之处。 两者都必须具备的核心能力包括:
1)查询不同的数据源
2)处理数据
3)总结数据
4)统计和数学技能
5)制作数据可视化图和报告
数据科学家和数据分析师的区别在于,后者不负责编程,统计建模,机器学习等。两者所使用的工具也有很大的区别。数据分析师使用的商业智能工具包括: Microsoft Excel , Tableau, SAS, SAP, Qlik 等。 就数据挖掘和数据建模而言,数据分析师大多使用BM SPSS Modeler, Rapid Miner, SAS, KNIME.;数据科学家倾向于使用R和Python。
两者与中上层管理者的交流模式也很不同。数据分析师一般会接到自上而下的指令。数据科学家大多自发地提出问题;所使用的建模技巧、可视化技术等也更加高级;使用数据讲故事的能力也更加出众。
数据工程师
在大数据时代,数据工程师的角色愈发地重要。也许,数据架构师的称谓更准确。和数据分析师不同,他们不太关注统计、分析技能、建模等。他们的工作重点在于数据架构、计算、数据存储、数据流等。 因此,数据工程师必须具备相当强的编程能力—包括编写数据查询程序的能力。也就是说,他们的能力必须达到开发运营高手的级别。
数据工程师还负责数据库设计,数据仓储,建立数据湖。 这就意味着,他们必须十分熟悉现有的数据库技术和数据管理系统,比如和大数据有关的Hadoop与HBase 等。
此外,非功能性的基础设施问题,如数据的可扩展性、可靠性、韧性、有效性,备份等也由数据工程师来负责。
数据科学文氏图
数据科学家必备的各类知识、技能、思维之间到底是什么关系?答案不一而足。大卫∙泰勒 (David Taylor)发表过一篇题为“数据科学文氏图战争”的文章,有兴趣的读者可以找来看看。
我最认同的是史蒂芬∙科拉萨的(Stephan Kolassa)文氏图(作者按:幽默版)。
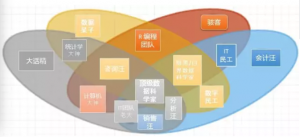
史蒂芬∙科拉萨对顶级数据科学家的定义和我的定义不谋而合。
数据科学家必须有出众的编程技能,以及统计、概率、数学方面的知识,如此才能理解数据、选择正确、实施、提升解决方案。市面上确实有不少现成的数据科学平台和应用程序界面。很多此类产品确实简单易上手。视处理的问题类型而定,这些现成的平台和程序确实能带来不错的结果。但是,依靠它们结果所有的问题的想法是不切实际的。数据科学家自身的能力和经验依然是最重要的。数据科学家不可替代的价值体现在以下方面:
1) 掌握现有的统计、编程、程序包、函数库等,并且具备甄选能力。
- 主要程序包和函数库:Scikitlearn, e1071, Pandas, Numpy, TensorFlow, Matplotlib, D3, Shiny, ggplot2
- 主要语言:R, Python, SQL, Scala, Julia, Java 等等。其中,前三项是基本;Scala 在大数据处理的应用中愈发重要
- 主要纪事和框架工具: Jupyter, iPython, Knitr, 和R markdown。
- 主要大数据框架:MySQL, PostgreSQL, Redshift, MongoDB, Redis, Hadoop, and HBase.
- 主要数据库:MySQL, PostgreSQL, Redshift, MongoDB, Redis, Hadoop, and HBase
2) 识别和选择最优数据源和数据变量;创造新的数据源,比如完成特征工程等。
3) 查询不同的类型的数据库和数据源,比如RDBMS, NoSQL, NewSQL等等,并且有能力将查询到的数据整合到分析驱动的数据源中,包括OLAP, warehouse, data lake等。
4) 保证数据的真实度和质量;确保数据处于最优形式。
5) 针对特定的问题,制定特定的解决方案。比如,写出全新的算法,或者优化现有的算法。
6) 选定和实施最优的算法、框架、编程语言等。
7) 选定正确的性能指标。
8) 在没有上级指示的情况下,运用数据达到商业目标。
9) 高效低与公司各个部门、各种团队合作。
10) 区分理想成果与失败结果,避免风险和财政损失。
11) 制订以产品和用户为导向的解决方案。
数据科学的目的与可交付产出(Deliverables)
数据科学的常见可交付产出如下:
1) 根据投入预测回报
2) 分类(例:是否为垃圾信息?)
3) 推荐(例:亚马逊(Amazon)和奈飞(Netflix)的服务模式)
4) 模式鉴别的分类
5) 异常检测(例:欺诈侦测)
6) 面部,图像,文字,声音,录像识别
7) 可行性洞见(actionable insights)(例:通过控制界面、报告、可视化图像呈现。)
8) 自动化流程和决策(例:信用卡审批)
9) 打分和排列(例:费寇分数(FICO score)的核算)
10) 分割方案(例:基于人口统计学特征的市场营销)
11) 优化方案(例:风险管理)
12) 预测(例:营业额和销售额)
必须强调的是,优秀的数据科学家应该全面理解商业运作和数据之于实现高级目标的价值。在现实世界中,数据科学家的商业洞见十分重要。虽然那些接受过系统的商科教育,拥有MBA学位的管理层人士十分聪明,但是他们也许对数据学家的技艺不甚了了。 所以,很难指望他们针对数据科学的可交付产出和数据的商业价值的开发给出具体的指示。这就需要数据科学家自身具备相当程度的商业洞见,如此才能经常发现新机会,提出新想法,来帮助公司实现业绩目标,优化关键业绩指标。
此外,数据科学家需要经常向中高层管理者报告结果。这就需要出色的笔头表达和空开演讲技能。数据科学家须以一种简单易懂,令人信服,充满洞见的方式向听众展示成果。所使用的语言―特别是术语―必须在听众可以接受的范围之内;展示的结果须与商业目标紧密相关。
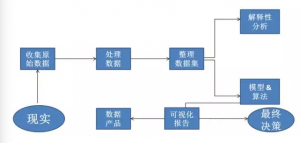
数据科学的运作流程
数据科学的具体运作流程一般视项目目标而定,没有固定的模式。一般而言,可分为以下十个步骤:
1)获得,收集,储存数据
2)发现和确定目标;提出正确的问题
3)提取和整合数据
4)处理,提纯数据
5)初步数据调查和解释性数据分析
6)选定一种或多种数学模型和算法
7)运用数据科学的方法和技术(例:机器学习,统计建模,人工智能等)
8)评估和提升成果(例:检验和微调)
9)输送,解释,展示最终成果
10)基于最终成果,做出商业决策或调整先前决策
上述过程可以浓缩在下图中:
总结
哈佛对数据科学家职业前景的预测无疑是对的。数据科学家极端稀缺,极端重要。对实现公司的财务、运营、战略目标而言,数据科学家的角色愈发重要。
现在的公司一般都会囤积大量的数据。这些数据一般都处于被忽视,或者利用不足的状态。经过信息提取,可以将其转化为关键的商业决策,为企业带来显著的正向改变。这些数据还可以用来建立品牌忠诚度,获取和保留顾客,实现业绩增长等。当然,数据科学不是万能的,有时也会带来错误的决策。这就是为什么雇到顶尖的数据科学家对企业而言愈发重要的原因。
希望你就是下一个获得高薪offer 的顶尖数据科学家!





