
如何通俗的解释Docker是什么及其优点?
Jeff Lofvers曾在漫画里说明了在软件开发和数据科学中经常遇到的问题。 如果当你正在准备数据分析或预测模型时,如果你想分享它们,就会发现它们不适用于其他机器。 这个失败,是因为缺少库,库有错误的版本(“依赖地狱”/ ”dependency hell”),或者配置不同。 于是你便开始了耗费时间的故障排除。
解决方案并不困难:Docker以轻量级方式解决了可重复性问题,同时也提供了许多其他优势。
什么是Docker?
Docker是一款执行操作系统级虚拟化的免费软件。 Docker用于运行,被称为容器的软件包。 容器彼此隔离,并捆绑其应用程序、工具、库和配置文件。 所有容器都由单个操作系统内核运行,因此比虚拟机更轻量级。 [Docker维基百科]
Docker可以轻松创建,运行和分发应用程序。 应用程序打包了运行应用程序所需的所有内容。 该概念保证容器可以在每个docker运行环境上运行。
Docker的优势
1、再生性
使用Docker时,可以确保软件产品(应用程序,数据分析,预测模型等)在所有docker运行时环境中运行。因为容器包含运行工程所需的一切,使得货物更加强大。 它不仅分发代码,还分发环境。
2、一致性
Docker提供了一个统一且一致的运行环境,适用于各种软件产品。 它减少了系统管理的时间,更专注于核心工作。 你可能知道Anaconda的环境; Docker类似于整个软件生态系统。
3、可追溯性
a.)Docker容器代码的版本控制
Docker容器是根据脚本构建的,该脚本在必要的软件依赖和环境下是可读摘要的。 这种脚本可以受版本控制。 脚本完全可以通过这种方式跟踪。
b.)所有人工制品的统一分配环境
Docker容器可以存储在组织内的存储库中,从而以这种方式保留整个版本的历史记录。
4、可移植性
Docker容器可以轻松地从一个docker环境移植到另一个docker环境。 Docker Swarm(或Kubernetes)允许自动扩展应用程序,从而以这种方式减少系统管理和操作的成本。
但是,Docker在数据科学领域的使用示例是什么? 接下来,我将专注于数据科学OSEMN的过程。
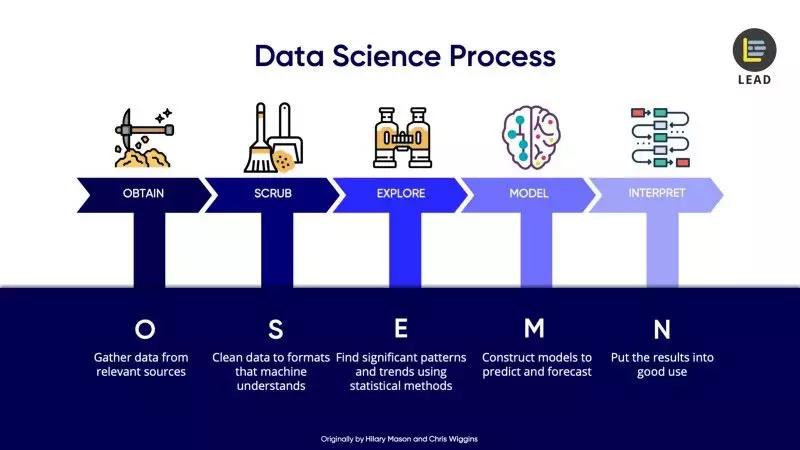
Docker在数据科学过程中的使用案例
现实是,该过程包含各种工具和编程语言。 Docker是管理这些异构技术堆栈的首选平台,因为每个容器都提供了一个程序所刚好需要的运行环境。 通过这种方式减少了技术堆栈的干扰。
1.获取:从相关来源收集数据
数据是数据科学的燃料。你检索它,例如数据来自调查,临床试验,网络抓取,科学实验,企业应用或模拟。通常,当数据工程师正在处理数据时,同时也涉及其他利益相关者,这导致了各种各样的数据库系统和编程语言。
· Web抓取:与Selenium的Chrome驱动程序和Postgres数据库具有低级依赖关系的Python应用程序,它为Docker Compose应用程序提供了多容器
· 标记图像:使用vue.js精简Web应用程序,NodeJS后端和MongoDB用于标记图像
· 调查:营销团队使用简单的HTML构建微型静态网站,并集成SurveyMonkey表单
· 企业应用:银行网站从后端在AngularJS和Java中使用Oracle,使得银行可以从客户那里获得有价值的数据
· 计算机模拟:用C ++编程的模拟将其结果存储在Amazon S3上的JSON中
· 异步数据流:Car Sensors正在将数据发送给Kafka,Kafka正在公司内部分发数据
所有这些技术堆栈都可以在Docker容器中独立运行。
2.净化:清理数据并将数据汇总到机器可以理解的格式
如果在步骤1中获得的数据是石油,那么现在它是原油。需要进行清理,处理并将其与分析和建模所需的数据相结合。
· 聚合:Java中的应用程序从Kafka流中获取数据,对低级数据进行聚合并将其存储到Oracle数据库
· 数据分析师清理和预处理公司网站应用程序中的数据,为使用RMarkdown Notebook 回答业务问题做准备,分析师们希望与管理员共享
· 机器学习工程师清理来自不同数据源的数据,并和预处理数据组合在一起,用于Jupyter Notebook中的预测模型
· 对Tableau中的高级交互式仪表板进行组合,清理,聚合和预处理以持久保存数据
其中一些例子可能已在数据检索步骤中完成,并且具有更多数据工程技术堆栈。另一些用例则可能与勘探和建模阶段重叠,涉及更典型的数据分析技术。
许多数据分析工作都是在需要发布的Notebook(Jupyter,RMarkdown)中完成的。可以向组织例举使用中央Jupyter的实例。这种方法的问题在于可能会遇到固定配置和库版本。另一种方法是使用Docker容器发布一个或多个Notebook。然后可以更灵活地使用特定设置。
3.探索:找到模式和趋势
在探索阶段,所要做的就是了解数据中的模式和值。 并将结果提供给每个感兴趣的人。
· 数据分析师正在创建Jupyter或RMarkdown的Notebook,以回答那些需要或感兴趣的人分享的问题。
· 数据分析师将公司客户聚集到新的细分市场中,这些细分市场存储在MySQL的客户细分数据库中
· 数据分析师构建交互式网页应用程序,以便为RShiny,Dash,Tableau或Kibana中的感兴趣的利益相关者探索高级数据。 这样管理者可以自己找到模式(危险区域!)。
4.模型:构建模型以进行预测和展望
清理和预处理的数据用于训练机器或深度学习算法。 可以通过这种方式创建模式,从而观察数据的数学表示形式。 它们可用于预测和量化不可言说的内容。
· 在图像中对目标检测的神经网络的完整培训过程,被隔离到在Azure,AWS或Google Cloud上运行的Docker容器
· 由于Python的性能问题,Keras模型被导入DeepLearning4J并作为Java Microservice发布要训练神经网络,需要大量的GPU能力。因为使用GPU无法以与硬件无关且与平台无关的方式完成,所以需要Nvidia Docker将训练过程隔离到Docker容器。
5.解释:充分利用结果
数据科学的见解得到沟通和可视化。 模型作为微服务分发。
· 微型网站讲述数据故事
· Python中的预测机器学习模型作为微服务发布
· Java中具有聚合数据的REST微服务被发布给付费B2B客户
· 在Python中的产品推荐程序服务已集成到公司的Web应用程序中
· 数据驱动的故事发布在公司的Tableau Server上,并共享以供内部和外部使用
· 内容管理团队中的数据故事讲述者在静态Jekyll网站上分享数据分析师的精彩见解
结论
Docker是数据科学家的强大工具,可应用于OSEMN流程的所有阶段。 可以用一致,可重复和可追溯的方式运送各种人工制品。 人工制品的技术堆栈可能非常不同,这是数据科学项目中的现实。 数据工程师使用Oracle,MySQL,MongoDB,Redis或ElasticSearch等数据库或Java,Python或C ++等编程语言。 在分析和建模团队中,人们可能会使用R,Python,Julia或Scala,而数据故事讲述者则使用JavaScript中的d3.js或使用Tableau来讲述他们的故事。 由于专家很少见,所以最好让讲述者使用熟悉的技术,而不是将他们推向未知的技术。 这样会更快地获得更好的结果。
原文作者:Jens Laufer
翻译作者:Yaling Huang
美工编辑:过儿
校对审稿:冬冬
原文链接:https://towardsdatascience.com/example-use-cases-of-docker-in-the-data-science-process-15824137eefd





