
如何向面试官展示“一键清理”令人头皮发麻的原始数据?
在大数据时代,有大量可以用来处理和分析的数据固然是令人欣喜的。但是现实往往是骨感的,杂乱无章的原始数据往往让人一眼望去头皮发麻,摸不着头脑。即使情况稍微好一些,数据存储以关系数据库、Excel或者其他格式存储,行行列列错落有致,往往也不容易进行加工处理。所以,为了可以在数据基础上建模得到有价值的分析结果,特征工程昂首阔步走上了舞台。
什么是特征工程呢?
特征工程是一个将数据进行加工处理,改变它们的表现形式,提高其可用性的透明化过程。改变数据的形式,或者在已有数据基础上进行数学运算和编码,使它们适用于机器学习的模型;将处理过的数据进行可视化之后,方便其他部门的人理解(不然他们才不会care你的模型?)。但是特征工程往往是复杂的,因为针对不同的数据集,往往需要不同的处理方法。所以,特征工程往往是数据处理过程中最耗时间的部分,是数据科学的灵魂,也是AutoML技术唯一还没有攻克的底盘。
为了更好地理解特征工程,这里有一个简单的例子。如下图所示,有两个类别的数据点。假如有个仓库,它只有对一定范围内的客户服务,才能保持盈利,否则就会亏本。从人的角度来看,很容易理解,我们只需要计算一下点与点之间的距离就可以了。
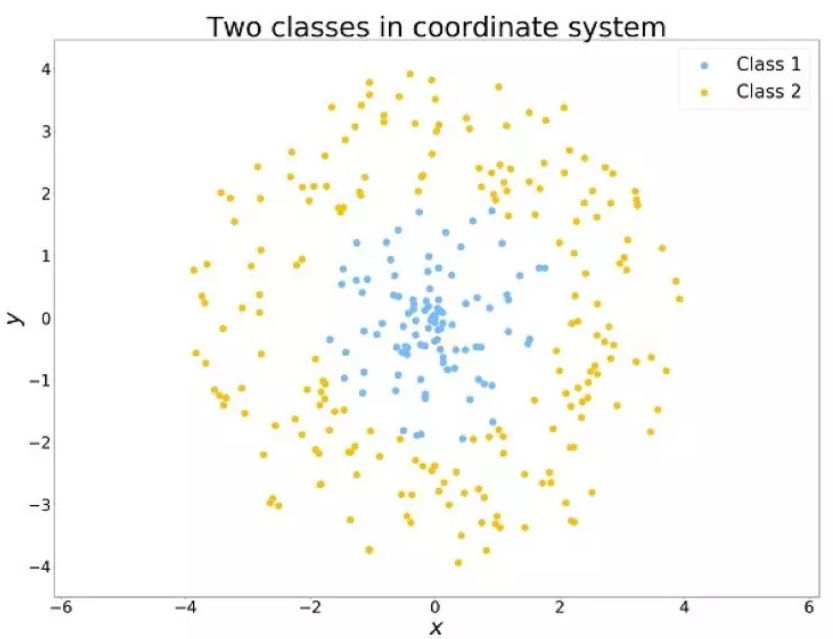
但是问题来了,算法没有这么聪明。就拿决策树的算法来说,它一次只知道考虑一个feature,然后根据这个feature的大小将数据集分成几类,依次类推··· 它还没有成熟到知道自己计算半径的程度。(嘲笑之余居然有些庆幸是怎么回事···)
不过,我们只需要做一个坐标系转换,将数据从普通的笛卡尔坐标系转换为极坐标系,两类数据就有了明显的分界,电脑也就上道了。
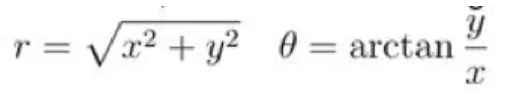
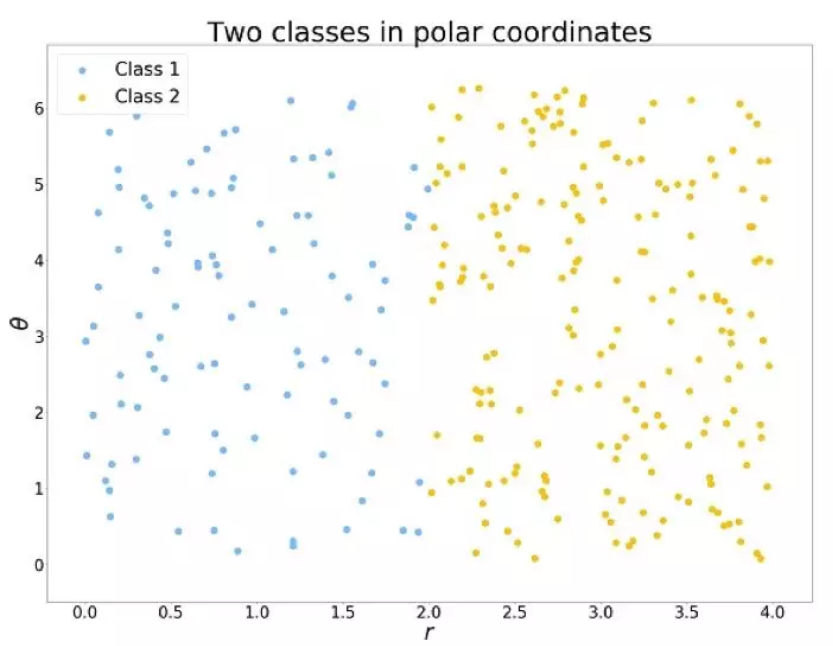
常见的数据类型和处理方法
连续性数据
最常见的数据就是连续性数据了,就是可能取任意值的数据,比如商品价格,工业生产中的环境温度,地图上的某个点等等。对付这些数据的操作,往往就是依据专业知识进行数学运算,比如计算两市的距离,收入减成本等等。
离散型数据
其次就是离散型数据了,对离散型数据而言,每个feature往往可以被分成少量几类,比如性别:男,女,不确定。
问题在于,离散型数据有可能是文本格式,然而没有算法可以直接处理文本数据。所以怎么办呢?既然机器只认识数字,那就把文本转换成数字咯。对每个不同的类别,把它们用数字进行编码。但是,考虑到机器学习的效率,将文本编码为1和编码为1000可能对模型的影响不同,在类别过多的时候,通常不用普通的标签编码,而是采用独热编码。所谓独热编码,就是不把该特征的值用很多不同的数字来表示,而是都用布尔值(0和1)来表示,对每个不同的类别,都有且只有一个不同的位置是1,其余全是0。在神经网络中,由于数据量很大,独热编码已经大行其道啦。
缺失值
在真实世界中,往往是不会有完美的,直接就可以处理的数据集的。而且,往往会有一些数据由于隐私原因无法获得,或者因其他原因不慎丢失?♀️。处理这些幺蛾子,就要靠数据科学家们大展身手了。
这个数据处理的过程我们通常称之为数据清理。然而,需要注意的是,在创造新的特征或者填补数据的时候,我们需要记得丢失数据的地方。原因是,有的编程语言会把缺失值的地方赋予特殊的值。虽然通常情况下是用“NaN” 来表示,但是有的时候会强制赋予其他数值。
举个例子,一列正整数中,缺失值有可能被赋值-1(哎电脑你还需要成长),这会影响我们对这一列数值进行数值的运算,比如求和,求平均等等。再有,如果缺失值被赋值0,当我们生成新的feature需要做除法的时候,都会直接生成0,也是显然错误的。❌
这一切的一切都在无声地告诉我们,一定要了解你的数据,不然,接下来就是见证你扑街的时刻?♀️。
对此,我们的解决方法通常是引入布尔值来表示一个特征中是否有缺失值,如果有缺失值,就用True来标记;如果没有缺失值,就用False来标记。这样一来,机器学习的模型就知道是应该直接信任已有数据,还是用内置的方法进行处理了。
标准化(Normalization)
另一个常用的特征工程的方法是将数据转化到一个范围内。为啥要这么做呢?第一,数据在一定范围内,可以提高计算的准确性,减少计算能力的占用。第二,也是主要原因,在数据标准化之后,机器学习模型往往可以表现得更好。
这里有几种常见的标准化方法:
1. 标准正规化
在现实生活中,很多事情的规律都是呈正态分布的,这也是我们为什么这样处理数据的原因。公式如下:
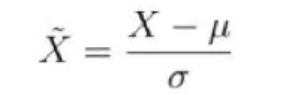
等式左边的X是我们的新feature。在原来的的数据基础上减去其平均值,然后再除以标准差,就将数据转化到了[-1,1]范围内。
2. 特征缩放
另外一种标准化的方法,是在先前数据的基础上减去最小值,然后除以数据的极差,这样可以把数据转化到[0,1]内。
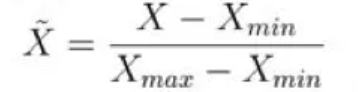
正如我们之前提到的,不同的模型需要不同的标准化来保证模型的工作效率。比如,对KNN近邻算法而言,数据的大小对权重是有影响的,值越大往往越重要,所以在对KNN的数据进行标准化时要慎重。而对神经网络算法来说,标准化过程不会影响最后的结果,但是可以加快它的运算速度。而对决策树算法而言,既不会影响计算效率,也不会对机器学习的结果有什么改变。
日期和时间
下一个常见的数据类型就是日期和时间了。让机器不开心的是,日期和时间的格式在不同国家可能是不统一的。比如,有的国家使用DD/MM/YYYY,有的国家使用MM/DD/YYYY,这些都需要我们先给机器宝宝处理好,喂给它,它吃了才能消化。
另外,时间和日期也不是数据格式,需要通过函数进行转化。这还不够,我们还可以根据国家不同的文化节日创造新的feature,因为人们在特殊的时间,往往会有不同的行为。大多数软件通常都把1970年1月1日作为系统时间的起点,对处理数据的人来说未尝不是一件好事(总有一个东西是统一的了?)。
下面是一个对时间数据进行预处理的例子:
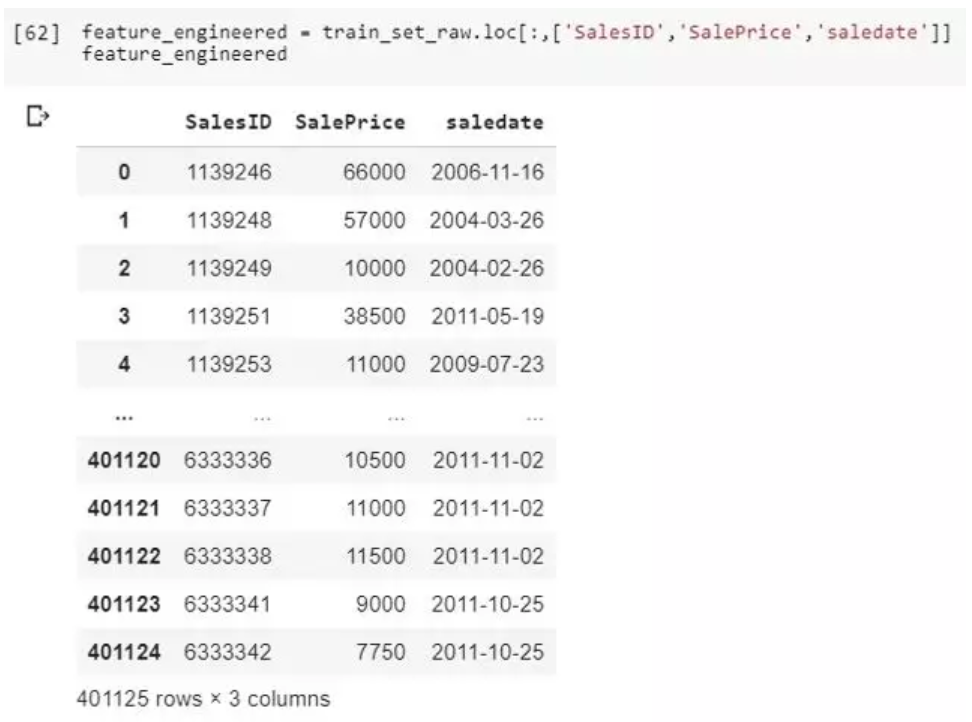
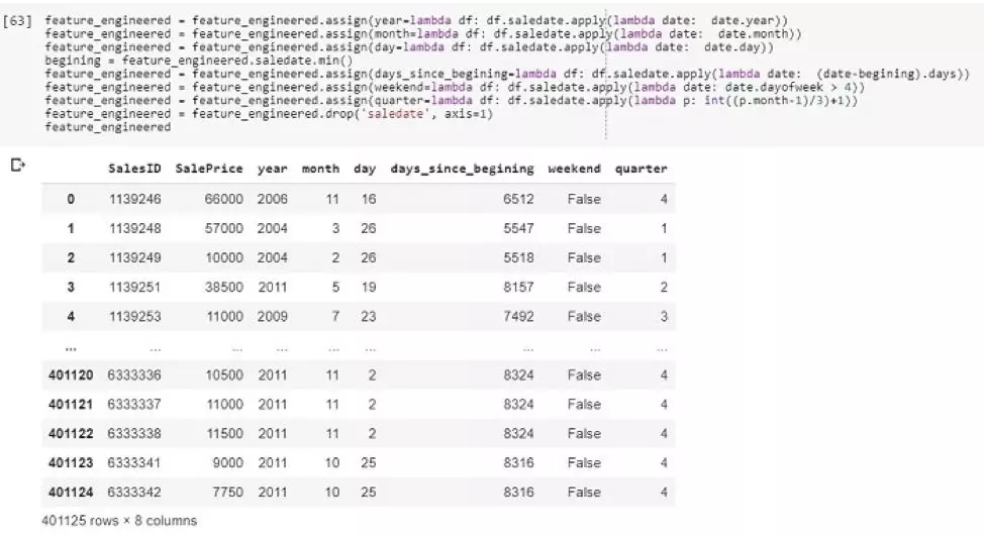
如图所示,为了解释方便,我们只引入了三列数据。SalesID用来查找每笔交易的,销售价格是我们要预测的,数据集中还有其他的很多信息,我们只看分析时间的部分。通过几行代码,我们将时间转变成了数字格式,可以用来挖掘更多潜在的信息了。
文本
文档中的文本都是用ASCII码编码的,好像听起来很容易处理?你又错了❌!在文本中提取信息,依靠的是词句之间的联系,这其实非常复杂,甚至专门有一个领域—自然语言处理。这个话题甚至都可以写出一本厚书,我们在此不过多赘述。
先抛开句子这种高级的东西不谈,我们通常先计算每个单词出现的次数。比如我们手上有一个HR部门的数据库,我们就可以得到公司员工的学历背景:Bachelor of Engineering, Master of Science 和 Doctor of Philosophy。他们可能有很多不同的学位,但是本科研究生和博士是共有的,我们可以提取出来。类似的还有,虽然名字不同,但是性别形式只有几个(Mr.,Mrs和Miss)可以提取出来。你看,就算不用自然语言处理,我们也有很多操作。
图像
可视化数据是另外一个可以写一本书的数据类型?♀️。这个问题已经困扰了数据科学家很多年,计算机可视化这个新领域也应运而生。值得一提的是,近年来,CNN算法的提出让很多对可视化没有太多了解的人,也可以使用CNN的计算框架,获得对可视化数据有效的解决方案。
正如你所看到的,这里有很多方式可以生成新的feature。但其实这只是一个开始,还有好多精妙的操作,比如将离散型数据和连续型数据混到一起进行运算,得到新feature,也可以通过NLP和CNN处理文字和图像。正是因为这些精妙的操作,特征工程也被看作是一种艺术。
原文作者:Paweł Grabiński
翻译作者:Zihuaun
美工编辑:喝豆奶的Narcia
校对审稿:卡里
原文链接:https://www.kdnuggets.com/2018/12/feature-engineering-explained.htm





