
遵循10个步骤进行出色的数据分析!
分析数据就像在巨大的信息矿井中发现黄金。随着数据的不断积累,有效地管理和分析数据似乎是一项艰巨的任务。幸运的是,有一种更直接、更有效的数据分析方法。
这10个步骤不仅可以最大限度地减少错误和不一致,还可以保证达到目标时更高的准确性和效率。无论你是经验丰富的数据分析师还是刚刚入职的新手,该方法都为进行有效的数据分析提供了清晰的路径。
让我们深入研究并提高你的数据分析技能吧!如果你想了解更多关于数据分析的相关内容,可以阅读以下这些文章:
Excel中的Python:将重塑数据分析师的工作方式
如何成为数据分析顾问?
成为更好的数据分析师的5个习惯!
Noteable:自动进行数据分析的ChatGPT插件
数据集!
我们将对泰坦尼克号的数据集进行分析,我们将试图了解影响乘客生存或死亡的因素。
import pandas as pd
titanic_df = pd.read_csv('titanic.csv')
titanic_df.head()
查看前5行,我们可以大致了解列中呈现的数据。
现在,让我们从数据分析的10步模板开始:
步骤1:概述
第一步是获得数据集的概览。我们将为这些专栏检查各种统计数据,揭示乘客数量、存活率、平均年龄和票价等信息。
titanic_df.describe(include = 'all')
## 891 Passengers.
## 38% survived.
## Avg Age: 29.
## Max fare went till 512. 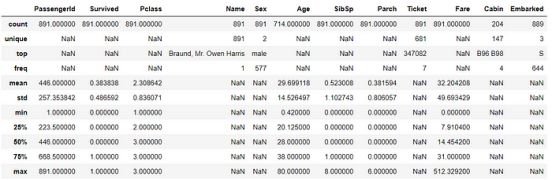
一些要点:
- 该数据集有891名乘客。
- 看看幸存一栏的平均值,我们可以看到只有38%的乘客幸存下来。
- 乘客的平均年龄约为30岁。
- 乘客支付的平均票价为32。
步骤2:数据类型
在第二步中,我们要检查列的数据类型是否正确。如果不正确,我们将进行纠正,以确保我们的分析准确。例如,我们在需要的地方将对象数据类型转换为整型。
# STEP 2: Data Types
titanic_df.dtypes
步骤3:缺失的值
接下来,我们将确定每列中缺少多少值。了解这一点有助于我们决定是否需要处理丢失的数据以及如何处理。
# STEP 3: Missing values
titanic_df.isnull().sum()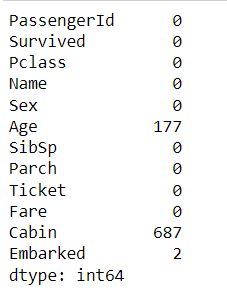
步骤4:缺失值处理
在检测到缺失值后,我们将进行处理。在我们的示例中,我们将使用列均值填充数字列的缺失值,并使用列模式填充分类列的缺失值。
## filling nulls with mean
titanic_df['Age'] = titanic_df['Age'].fillna(titanic_df['Age'].mean())
## filling nulls with mode
embarked_mode = titanic_df['Embarked'].mode()
titanic_df['Embarked'] = titanic_df['Embarked'].fillna(embarked_mode[0])
## count of nulls
titanic_df.isnull().sum()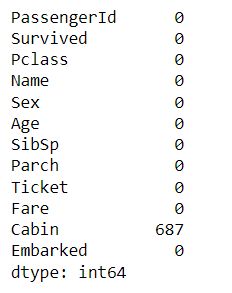
步骤5:寻找异常值
在第五步中,我们检查异常值-与其他数据点显著不同的数据点。我们将使用直方图可视化这些异常值,如下面的“票价”列所示。我们可以发现,除了票价列中有一个值在500左右外,票价列中几乎所有的值都小于300,这是一个异常值。
import matplotlib.pyplot as plt
plt.hist(titanic_df['Fare'],bins = 40)
plt.show()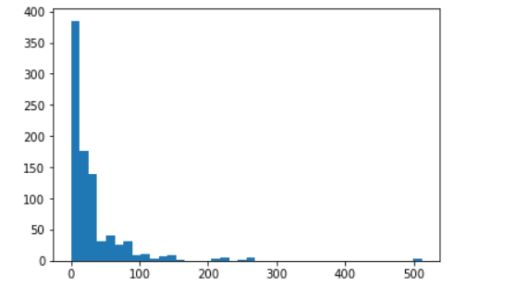
步骤6:异常值处理
一旦我们确定了异常值,我们就决定如何处理它们。例如,我们可以将变量的最小值或最大值限制为更直观的值。让我们对票价列进行异常值处理:
步骤7:谁——个人,一个成员,等等。
在这里,我们回答与人有关的问题。例如,我们可以找出谁有更大的生存机会——男性还是女性,有父母/孩子的乘客,有兄弟姐妹的乘客,等等。
## Gender
import plotly.express as px
gender_count["Survived"] = gender_count["Survived"].astype(str)
fig = px.bar(gender_count, x="Sex", y="count", color="Survived", title="Who were more probable to survive - Males or Females")
fig.show()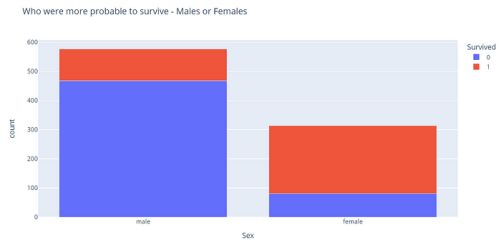
从上面的图表中,我们可以看到大多数女性存活了下来,而大多数男性死亡了。
接下来,我们可以检查兄弟姐妹/配偶的数量是否对存活率有影响。
## siblling or spouse
sibsp_count = titanic_df.groupby(['SibSp','Survived'])['PassengerId'].count().reset_index().rename(columns = {'PassengerId':'count'}).\
sort_values('count',ascending = False).head(5)
sibsp_count["Survived"] = sibsp_count["Survived"].astype(str)
fig = px.bar(sibsp_count, x="SibSp", y="count", color="Survived", title="Impact of count of siblings/spouse on the survival")
fig.show()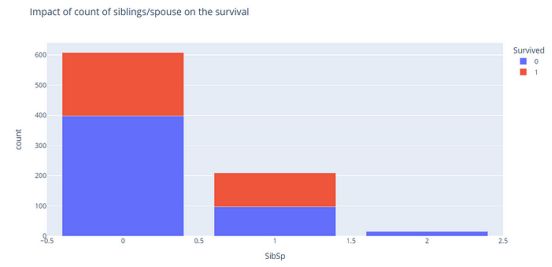
与其他群体相比,有1名兄弟姐妹/配偶同行的乘客有更大的生存机会。这可能是因为这个群体中的女性更多。
步骤8:时间相关问题!
这一步解决了与时间相关的问题。在我们的用例中,我们没有任何与时间相关的东西。
步骤9:地点相关问题!
我们检查与地点或座位相关的问题。在我们的例子中,我们会发现从特定的地方登船或乘坐特定的船舱会增加生存的机会。
Embarked_count = titanic_df.groupby(['Embarked','Survived'])['PassengerId'].count().reset_index().rename(columns = {'PassengerId':'count'}).\
sort_values('count',ascending = False).head(5)
Embarked_count["Survived"] = Embarked_count["Survived"].astype(str)
fig = px.bar(Embarked_count, x="Embarked", y="count", color="Survived", title="Impact of embarked on the survival")
fig.show()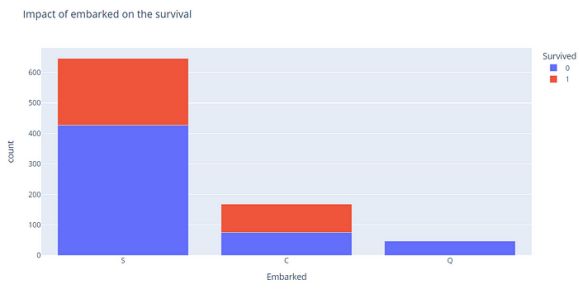
从Q港上船的乘客没有生还。其中一种假设是,从Q港出发的乘客贫困,因此没有被优先考虑生存,我们可以进一步研究他们的票价来验证这一点。
步骤10:什么/哪一个
最后,我们提出了前面步骤中没有涉及的各个方面的问题。这些都是主观的,差异很大。例如,我们可以确定哪个年龄组最有可能存活下来。
## creating age groups
titanic_df.loc[titanic_df['Age']<=15,'age_group'] = 'less than eq 15'
titanic_df.loc[titanic_df['Age']>15,'age_group'] = '15 and 30'
titanic_df.loc[titanic_df['Age']>30,'age_group'] = '30 and 40'
titanic_df.loc[titanic_df['Age']>40,'age_group'] = '40 and 50'
titanic_df.loc[titanic_df['Age']>50,'age_group'] = '>50'
## bar graph
Embarked_count = titanic_df.groupby(['age_group','Survived'])['PassengerId'].count().reset_index().rename(columns = {'PassengerId':'count'}).\
sort_values('count',ascending = False)
Embarked_count["Survived"] = Embarked_count["Survived"].astype(str)
fig = px.bar(Embarked_count, x="age_group", y="count", color="Survived", title="Impact of embarked on the survival")
fig.show()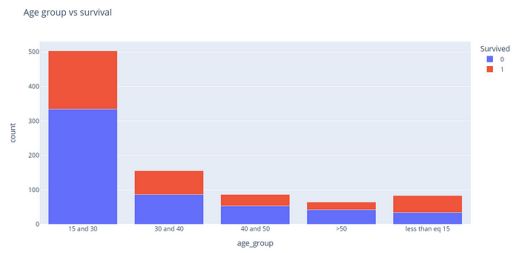
从上图中,我们可以推断出乘客更倾向于拯救15岁及以下的儿童。
在第十步结束时,你将能够探索几乎每一个潜在的问题,从而产生一些真正有用的见解。
希望你能从这篇博客中学到一些新的有用的东西。学习快乐!
结论
通过遵循这10步,无论你的经验水平如何,你都可以更有效地驾驭数据分析的复杂性。它提供了一种结构化的方式来从数据中提取有价值的见解,帮助你做出明智的决策并推动项目的成功。
感谢阅读!你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Anmol Tomar
翻译作者:Dou
美工编辑:过儿
校对审稿:Chuang
原文链接:https://python.plainenglish.io/follow-this-10-step-template-for-an-awesome-data-analysis-cb7975befa53





