
Imbalanced Data 有多让你头大?Amazon大佬教你两招!
毫无争议,分类是机器学习中最常见的问题之一。处理任何分类问题的最佳方法是从分析和探索数据集开始,我们称这种方法为:探索性数据分析(Exploratory Data Analysis, 简称EDA)。这个做法的唯一目的就是从数据集中挖掘尽可能多的洞见和信息。它还像探索者一样,细致盘查,不放过数据集中可能存在的任何问题。在用于分类的数据集中有一个常见问题,就是不平衡类问题。

数据不平衡通常反映数据集中类别的不均匀分布。例如,在一个信用卡欺诈检测数据集中,绝大多数信用卡交易都不是欺诈的,只有极少数的类别是欺诈。有的数据集中,欺诈类和非欺诈类之间的比例约为1:50。在本文中,我将使用Kaggle中的信用卡欺诈交易数据集。您可以从这里下载这个数据集。
首先,让我们通过画类分布图来查看数据的不平衡。
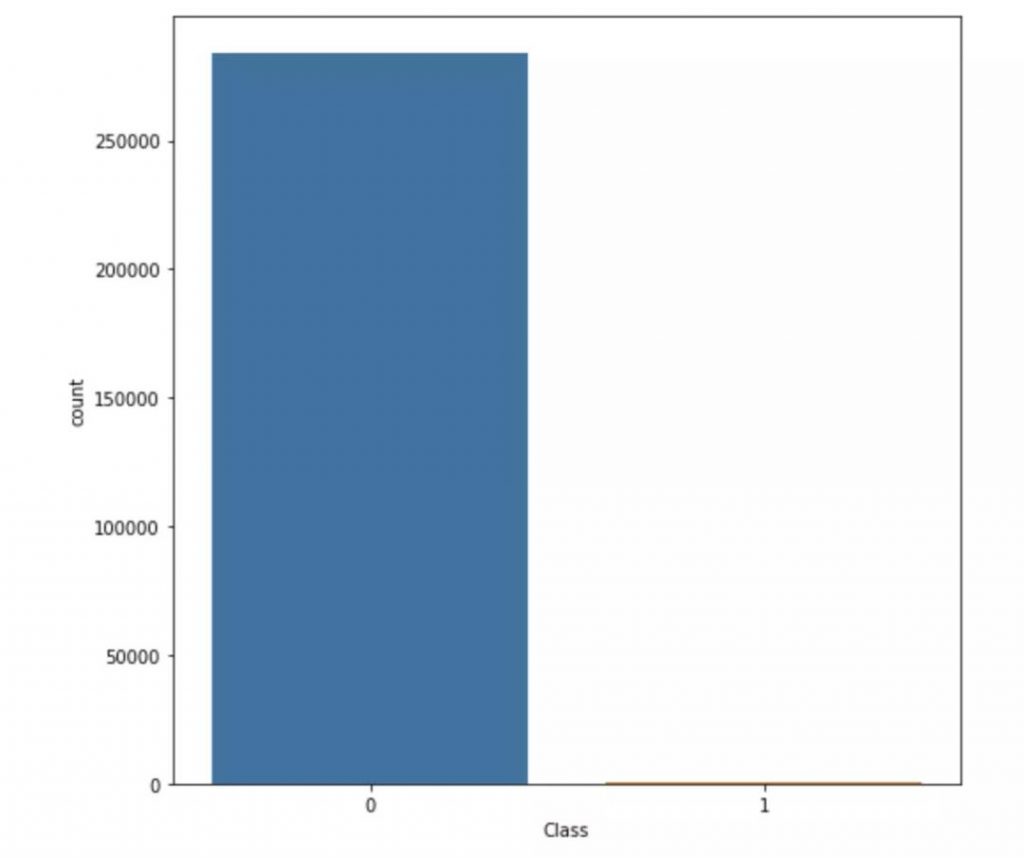
正如你所见,在交易类型中,非欺诈交易的数量远远超过欺诈交易的数量。如果我们不先解决这个问题,而是直接建立一个二项分类模型(binary classification model),这个模型将会完全有偏差。它还影响着特性(features)之间的相关性,且听我娓娓道来。
现在福利来了,有一些技巧可以解决这个问题,我会一一道来。在这个笔记里可以找到完整的代码。

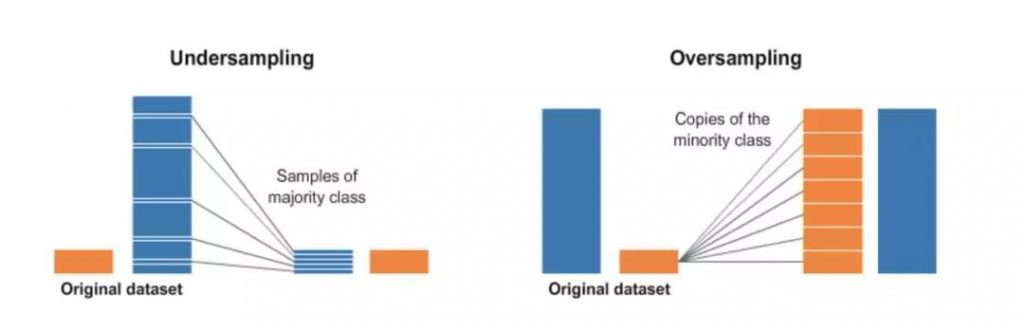
这听起来很直观。欠采样是从主体类(majority class)中随机删除一些观察值的过程。操作方法如下:
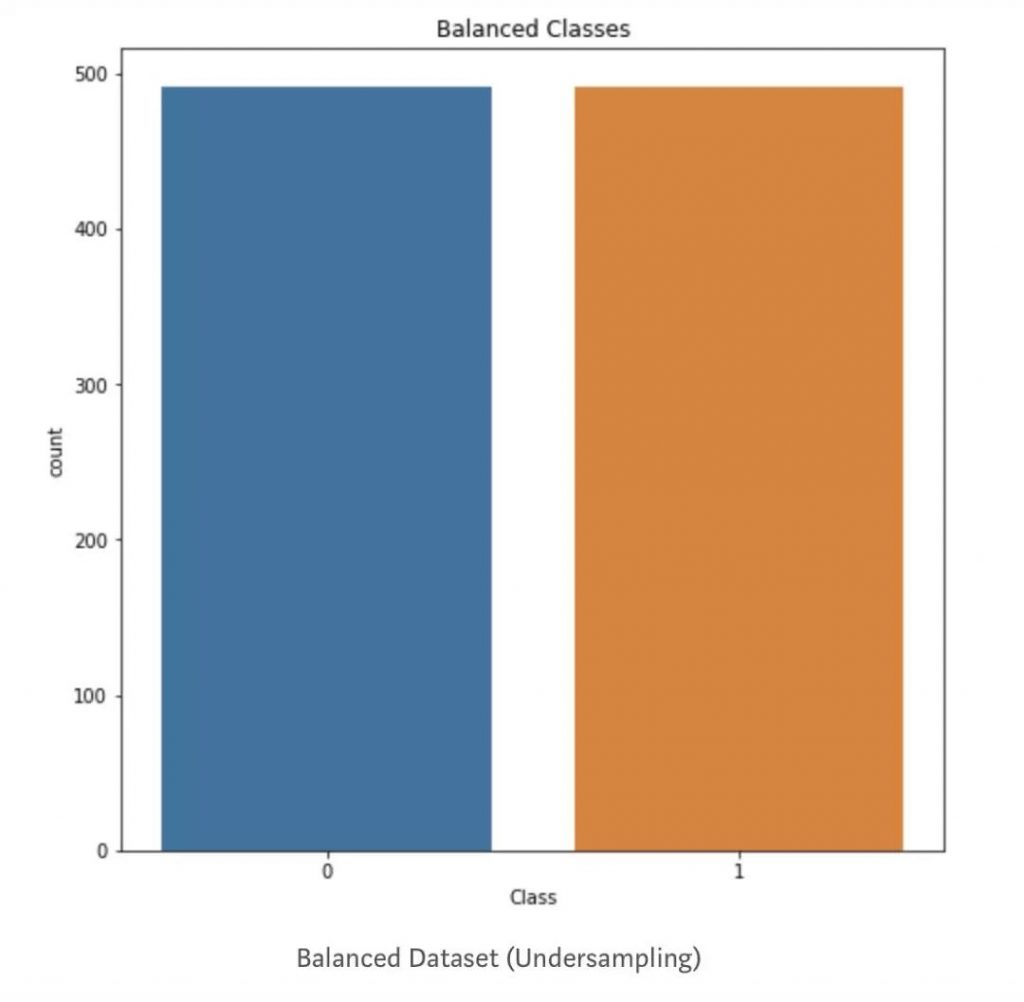
在对数据集进行欠采样后,再次绘制它,它就显示了相同数量的类:
第二种重新采样的技术称为过采样。这个过程比欠采样要复杂一些。它是试图从少数类的观测值中随机抽取样本属性,生成综合数据的过程。对于典型的分类问题,有许多方法用于对数据集进行过采样。最常用的技术是综合少数过采样技术(SMOTE)。简单地说,它查看少数类中数据点的特征空间,然后考虑它的k个最近邻点。
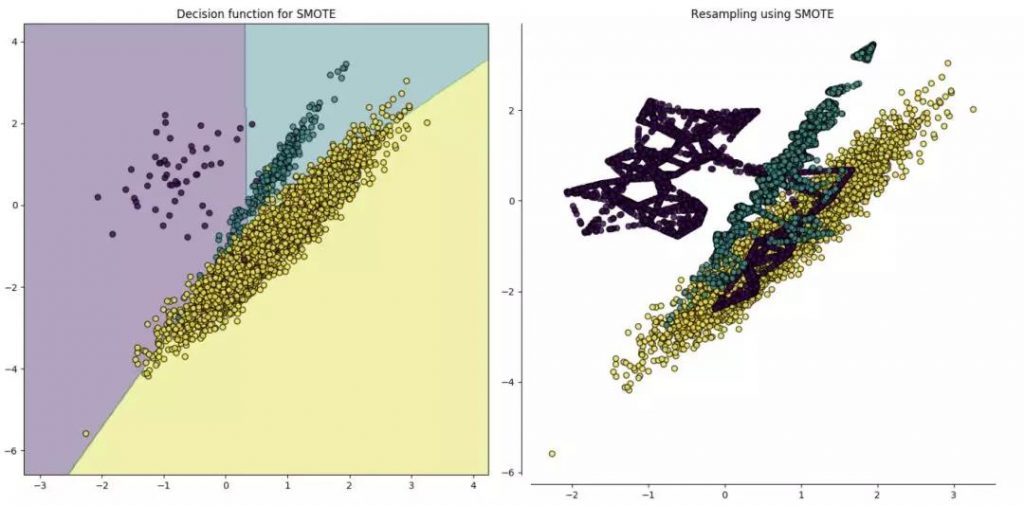
我在python中使用一个名为imbalanced-learn或imblearn的库,来编写这段代码。下面的代码展示了如何实现 SMOTE 技术。

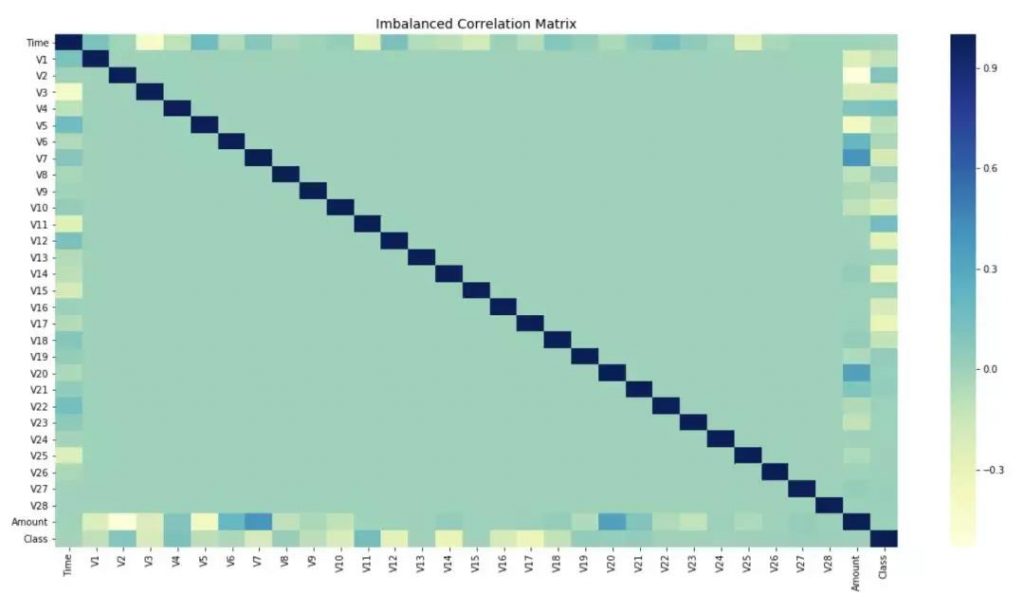
还记得我说过不平衡的数据会如何影响特征的相关性吗?让我给你们展示一下处理不平衡类前后特征之间的相关关系。
下面的代码绘制了所有特性之间的相关矩阵。

重采样前:
重采样后:

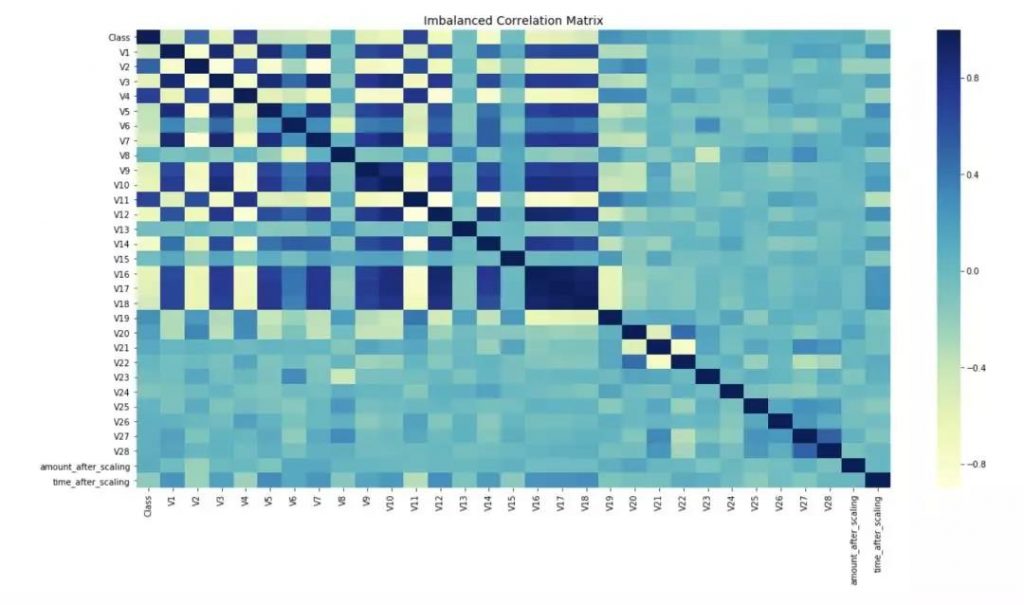
有没有发现,现在特性间的相关性更加明显。在修复数据集的不平衡问题之前,大多数特性间都没有显示出任何相关性,而这肯定会影响模型的性能。

当使用集成分类器时,bagging方法是通过对随机选择的不同数据子集构建多个估计器来实现的。在scikit-learn中,分类器被称为Bagging Classifier。但是,这个分类器不允许平衡数据集中的每个子集。因此,当对不平衡数据集进行处理时,该分类器将支持主类,并会创建一个有偏差的模型。
为了解决这个问题,我们可以使用 imblearn 库中的Balanced Bagging Classifier。它允许在利用每个集成估计器之前对数据集的每个子集进行重新采样。因此,Balanced Bagging Classifier 除了拥有与 scikit-learn 中的 bagging classifier相同的参数外,还使用了另外两个控制随机采样器行为的参数:sampling_strategy和replace。下面是操作代码:
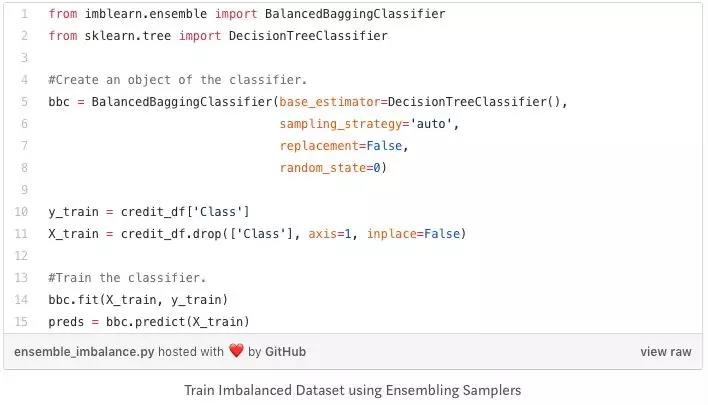
这样,您就可以训练一个分类器来处理这种不平衡数据集的问题,而不必在操作之前手动进行过采样或欠采样的操作。
总之,每个人都应该知道,在不平衡数据集上搭建的ML模型的整体性能,将受到其预测罕见点和少数点的能力的限制。识别和解决这些点之间的不平衡问题对于搭建模型的质量和性能至关重要。
原文作者:Will Badr
翻译作者:Zixin
美工编辑:过儿
校对审稿:卡里





