
自2014年以来数据工程的发展历程
在本文中,我将探讨数据编排和数据建模的演变趋势,重点介绍工具的发展及其对数据工程师的核心优势。如果你想了解更多关于数据工程的相关内容,可以阅读以下这些文章:
数据工程师必看的11本书!
Meta的数据工程:内部技术栈的高级概述
2023年,你需要知道的10个数据工程工具
数据工程——Scala与Python的区别
自2014年以来,尽管Airflow一直是主要玩家,但数据工程领域已经发生了显著变化,现在能够应对更复杂的用例和需求,包括对多种编程语言的支持、集成和增强的可扩展性。我将考察当代和可能不太传统的工具,这些工具简化了我的数据工程过程,使我能够轻松创建、管理和编排稳健、耐用且可扩展的数据管道。
在过去的十年里,我们见证了各种ETL框架在数据提取、转换和编排方面的“寒武纪爆发”。不出所料,其中许多都是开源的并且基于Python。
最受欢迎的有:
- Airflow,2014
- Luigi,2014
- Prefect,2018
- Temporal,2019
- Flyte,2020
- Dagster,2020
- Mage,2021
- Orchestra,2023
ApacheAirflow,2014年
ApacheAirflow由Airbnb于2014年创建,于2016年开源,并于2018年加入Apache软件基金会。它是一个可以以编程方式创建、调度和监控工作流的平台。Airflow首次引入了DAG(有向无环图)的概念。工程师使用Python定义DAG(有向无环图)来组织和可视化任务。现在几乎每个编排工具都使用它。例如,“PrefectDAG”看起来几乎一模一样。
界面简单,可以轻松监控数据管道:
DAG很容易理解,并且用Python编写:
@dag(default_args=default_args, tags=['etl'])
def etl_pipeline():
@task()
def extract():
return json.loads(data_string)
@task(multiple_outputs=True)
def transform(order_data_dict: dict):
return {"total_count": len(order_data_dict)}
@task()
def load(total_order_value: float):
print(f"Total order value is: {total_count}")
extracted = extract()
transformed = transform(extracted)
load(transformed["total_count"])优点
- 简单且稳健的用户界面:DAGs的详细视图、重试、任务持续时间和失败情况——经过这些年,一切看起来都如此熟悉。
- 社区支持:开源项目经过这么多年,已经拥有庞大的追随者社区。它非常受欢迎,并且拥有大量适用于各种数据源和目的地的插件。再加上定期更新,它成为许多数据开发人员的不二之选。
- Python:Python意味着自定义和脚本化。这里的一切看起来都非常灵活。在我多年前的一篇文章中,我设法定制了一个机器学习连接器,而且非常容易做到。
- Jinja和参数:这个功能对许多DBT用户来说一定很熟悉,使我们能够以类似于在DBT中创建模板化模型的方式创建动态管道。
Luigi,2014
另一个用于我们ETL管道的编排工具。Luigi由Spotify开发,用于处理大量数据处理工作负载,具有命令行界面和出色的可视化功能。然而,即使是简单的ETL管道也需要一些Python编程技能。尽管如此,Luigi在许多情况下都能很好地工作。
优点
- HDFS支持:Luigi为团队提供了一个方便的任务模板工具箱,包括用于HDFS和本地文件的文件系统抽象。这有助于保持操作的原子性和数据管道的一致性,使一切顺利运行。
- 易于使用:拥有强大的追随者和贡献者社区。该项目得到维护。
- 美观的用户界面:Web用户界面允许搜索、过滤和确定DAG的优先级,这使得处理管道依赖关系变得容易。
- 强大的基础设施:Luidgi通过多种工具、A/B测试、建议和外部报告支持复杂的管道。
从我的经验来看,它非常适合严格而直接的管道,尽管实现复杂的分支逻辑可能具有挑战性。甚至Spotify自己也在2019年放弃了它。他们说它不容易维护,他们需要多种语言支持。
他们搬到了Flyte(详见下文)。
Prefect,2018
Prefect成立于2018年,旨在克服工程师在使用Airflow等其他编排工具时面临的一些挑战。Prefect采用的系统比Airflow简单得多。你可以使用Python装饰器轻松地将代码转换为“PrefectDAG”,而不是使用DAG结构。
它提供了一种混合执行模型,允许在本地或任何云平台上执行任务。
Prefect自称为“数据流自动化的新标准”
优点
- 开源:灵活性和多种部署选项。
- 轻量级:只需一个命令,我们就可以设置我们的编排开发环境。
- 动态映射:根据另一个任务的输出实现动态任务的执行。
- Python-first:凭借Python-first的经验,Prefect提供了更清晰的抽象,类似于Airflow。
- 监控:使用Prefect的CloudUI监控关键操作指标和运行故障。它看起来直观又美观。
- 警报和通知:Discord、电子邮件、Slack以及更多用于我们的管道警报的渠道。
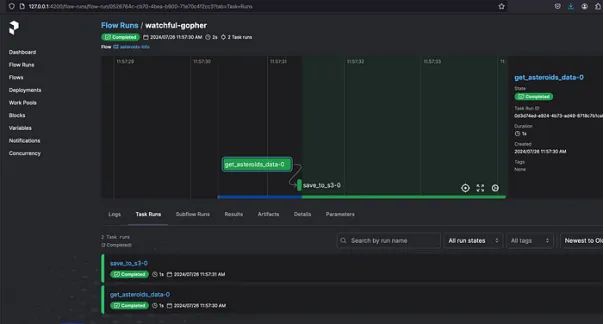
开源版本提供了我们在Airflow中通常使用的所有内容,包括调度、本机机密、重试、并发管理、扩展功能和出色的日志记录等功能。
通过PrefectCloud,我们可以获得一些额外功能,例如自动化、Webhook、事件提要以及针对我们可能需要的托管环境定制的工作区和组织。
关键组件是我们构建的任务和流程。我们可以用Prefect的@task装饰器(流程的基本单元)描述管道的每个步骤。对于每个任务,我们都可以使用参数提供设置。它可以是任何东西——标签、描述、重试、缓存设置等。请考虑以下情况@task。
@taskdef extract_data(source, pipe):...return result@taskdef load_data_to_dwh(data, database: bigquery):...return table_name@taskdef run_data_checks(dataset, row_conditions: qa_dataset):...
在下面的示例中,我们使用@flow装饰器创建了一个流程。该流程将按顺序执行所有任务,生成输入和输出并将它们从一个任务传递到另一个任务。
@task
def extract_data(source, pipe):
...
return result
@task
def load_data_to_dwh(data, database: bigquery):
...
return table_name
@task
def run_data_checks(dataset, row_conditions: qa_dataset):
...Prefect使用工作池(WorkPools)来有效地管理工作分配,并在所需的环境(测试、开发、生产)中优先处理任务,以实现最佳性能和自动化测试。我们可以在本地或在云中创建工作者(agents)。
可以使用pip安装Prefect:
pip install -U "prefect==2.17.1"
# or get the latest version from prefect
pip install -U git+https://github.com/PrefectHQ/prefect以下是从NASAAPI提取数据的简单脚本:
# ./asteroids.py
import requests
API_KEY="fsMlsu69Y7KdMNB4P2m9sqIpw5TGuF9IuYkhURzW"
ASTEROIDS_API_URL="https://api.nasa.gov/neo/rest/v1/feed"
def get_asteroids_data():
print('Fetching data from NASA Asteroids API...')
session = requests.Session()
url=ASTEROIDS_API_URL
apiKey=API_KEY
requestParams = {
'api_key': apiKey,
'start_date': '2023-04-20',
'end_date': '2023-04-21'
}
response = requests.get(url, params = requestParams)
print(response.status_code)
near_earth_objects = (response.json())['near_earth_objects']
return near_earth_objects
if __name__ == "__main__":
get_asteroids_data()我们可以把它变成这样的流程:
# my_nasa_pipeline.py
import requests # an HTTP client library and dependency of Prefect
from prefect import flow, task
API_KEY = "fsMlsu69Y7KdMNB4P2m9sqIpw5TGuF9IuYkhURzW"
ASTEROIDS_API_URL = "https://api.nasa.gov/neo/rest/v1/feed"
@task(retries=2)
def get_asteroids_data(api_key: str, url: str):
"""Get asteroids close to Earth for specific datess
- will retry twice after failing"""
print('Fetching data from NASA Asteroids API...')
session = requests.Session()
url = ASTEROIDS_API_URL
apiKey = API_KEY
requestParams = {
'api_key': apiKey,
'start_date': '2023-04-20',
'end_date': '2023-04-21'
}
response = session.get(url, params=requestParams)
print(response.status_code)
near_earth_objects = (response.json())['near_earth_objects']
return near_earth_objects
@task
def save_to_s3(data):
"""Save data to S3 storage"""
# Do some ETL here
result = print(data)
return result
@flow(log_prints=True)
def asteroids_info(date: str = "2023-04-21"):
"""
Given a date, saves data to S3 storage
"""
asteroids_data = get_asteroids_data(API_KEY, ASTEROIDS_API_URL)
print(f"Close to Eart asteroids: {asteroids_data}")
s3_location = save_to_s3(asteroids_data)
print(f"Saved to: {s3_location}")
if __name__ == "__main__":
asteroids_info("2023-04-21")运行流程:、
pythonmy_nasa_pipeline.py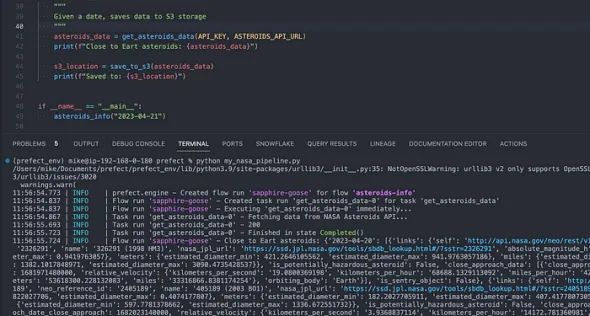
创建Prefect服务器
现在我们要创建一个部署来安排我们的流程运行:
#create_deployment.py
fromprefectimportflow
if__name__=="__main__":
flow.from_source(
#source="https://github.com/your_repo/prefect_nasa.git",
source="./",
entrypoint="my_nasa_pipeline.py:asteroids_info",
).deploy(
name="my-first-deployment",
work_pool_name="test-pool",
cron="01***",
)在命令行运行:
pythoncreate_deployment.py
#Runtheworkflowmanually
#prefectdeploymentrun'repo-info/my-first-deployment'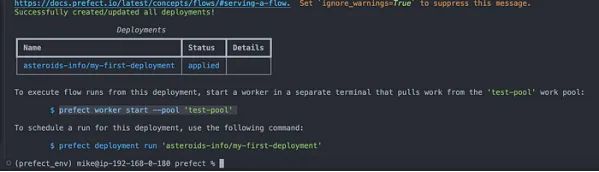
为了运行我们预定的流程,我们需要创建一个工作池:
prefectwork-poolcreatetest-pool
prefectworkerstart--pool'test-pool'
prefectserverstart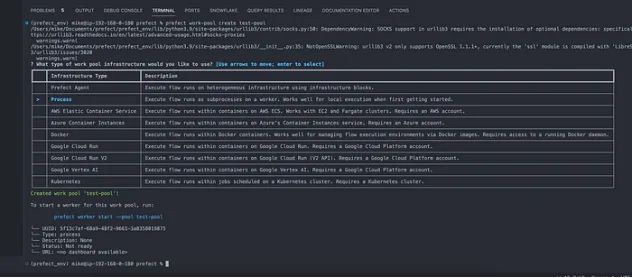
或者,我们可以使用此命令并使用提示符来创建部署:
prefectdeploy./my_nasa_pipeline.py:asteroids_info-nmy-first-deployment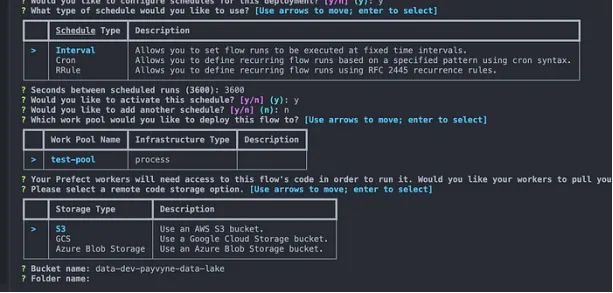
Prefect集成
Prefect凭借其强大的集成功能变得更加强大。例如,我们可以将Prefect与DBT一起使用,这使我们的数据建模更加强大。在命令行中运行:
pip install-Uprefect-dbt
#registerblockstostartusingtgheminPrefect
prefectblockregister-mprefect_dbt现在我们可以使用Prefect了dbt-core:
from prefect import flow
from prefect_dbt.cli.commands import DbtCoreOperation
@flow
def trigger_dbt_flow() -> str:
result = DbtCoreOperation(
commands=["pwd", "dbt debug", "dbt run"],
project_dir="PROJECT-DIRECTORY-PLACEHOLDER",
profiles_dir="PROFILES-DIRECTORY-PLACEHOLDER"
).run()
return result
if __name__ == "__main__":
trigger_dbt_flow(Temporal支持通过API触发工作流,并允许多个并发工作流执行。
优点
- 容错和重试:容错功能,可自动重试任何失败的任务。能够管理可能持续数天甚至数月的长期运行的工作流程。
- 可扩展性:适应高吞吐量工作负载的能力。
- 增强监控:了解工作流程执行和历史数据。
- 支持时间查询和事件驱动的工作流。
- 异构性:多种编程语言支持。
Temporal可以协调复杂的数据处理工作流程,有效管理故障,同时在整个过程中保持数据的一致性和可靠性。其跨分布式系统管理状态的能力使Temporal能够增强资源分配。
Temporal可适应持续运行的工作流,从而能够对各种实体的生命周期进行建模。Temporal工作流本质上是动态的,能够执行多步骤核心业务逻辑。它们可以发送或等待来自外部流程的信号,从而方便向人员发出通知或启动干预流程。
Flyte,2020年
Flyte是一款基于Kubernetes构建的开源编排工具,用于管理机器学习和AI工作流。由于数据对企业至关重要,因此运行大规模计算作业必不可少,但在操作上却具有挑战性。扩展、监控和管理集群会给产品团队带来负担,从而减缓创新。这些工作流还具有复杂的数据依赖性,如果没有平台抽象,协作就会变得困难。

Flyte旨在通过简化这些任务来提高机器学习和数据处理的开发速度。它确保可靠、可扩展的计算,让团队专注于业务逻辑。此外,它还促进团队之间的共享和重用,一次性解决问题,并在数据和机器学习角色合并时增强协作。
优点
- 端到端数据沿袭:这可让你在每个执行阶段监控数据和ML工作流的运行状况。轻松分析数据流以查明任何错误的来源。
- 参数和缓存:在设计时充分考虑了机器学习,它允许动态管道和使用缓存的预计算工件。例如,在超参数优化期间,你可以轻松地为每次运行应用不同的参数。如果某个任务在之前的执行中已经计算过,Flyte将有效地使用缓存的输出,从而节省时间和资源。
- 多租户和无服务器:Flyte消除了管理基础设施的需要,让你专注于业务挑战而不是机器。作为一项多租户服务,它为你的工作提供了一个独立的存储库,允许你独立部署和扩展。你的代码已进行版本控制,并与其依赖项一起容器化,并且每次执行都是可重现的。
- 可扩展:Flyte任务可能非常复杂。它可以是一个简单的ETL作业,也可以是调用远程Hive集群或分布式Spark执行。最佳解决方案可能托管在其他地方,因此任务可扩展性允许你将外部解决方案集成到Flyte和你的基础设施中。
- 异构和多语言支持:数据管道可能很复杂。每个步骤都可以用不同的语言编写并使用各种框架。一步可以使用Spark准备数据,而下一步可以训练深度学习模型。
Dagster,2020年
Dagster是一个开源数据编排器,可促进数据管道的开发、管理和监控。它支持作业监控、调试、数据资产检查和回填执行。
本质上,Dagster作为构建数据管道的框架,充当数据生态系统中的抽象层。
一切皆异构。
优点
- 异构:Dagster提供了一个全面的界面,使用户可以在一个地方构建、测试、部署、运行和优化他们的数据管道。这种统一的方法简化了数据工程师的工作流程,使管理整个数据处理的生命周期变得更加容易。
- 改进的抽象:它通过软件定义资产(SDA)采用声明式编程,从而增强了抽象并简化了管道设计。用户可从共享、可重用和可配置的组件中受益,从而促进高效的数据处理。此外,Dagster还包括声明式调度功能,允许用户实施新鲜度策略,确保数据是最新的。
- 测试功能:为了确保数据的完整性,Dagster使用定义管道输入和输出可接受值的类型进行质量检查。它还支持代码和数据的资产版本控制,以及增强性能的缓存机制。
- 出色的监控功能:Dagster配备内置可观察性仪表板,可实时监控管道性能和健康状况。其内置的可测试性功能允许用户无缝验证其管道的功能。
- 强大的集成:Dagster提供与数据生态系统中各种工具的强大集成,包括Airflow、dbt、Databricks、Snowflake、Fivetran、GreatExpectations、Spark和Pandas。
Mage,2021
Mage的创建似乎侧重于速度和可扩展性,专门针对Kubernetes等容器化环境量身定制。Mage创建于2021年,旨在满足微服务架构中日益增长的实时数据处理需求。
借助Mage,我们可以使用多种编程语言(例如R、Python和SQL)以及强大的模板功能。Mage无疑在编排领域引入了一些新事物。
优点
DRY组件和DBT支持:例如,我们专注于模块化设计,可以轻松集成不同的存储库、包和组件。轻松构建、运行和管理你的dbt模型。对于数据网格平台非常有用。
成本效益:声称优化资源配置和消耗,并具有明显的成本效益优势。
原生Kubernetes:轻松部署现代数据平台架构。
实时数据管道:与实时数据完美配合。提取和转换流数据是许多公司的真正痛点。
内置集成:支持数十种源和目标,例如AmazonS3、BigQuery、Redshift、PowerBI、Tableau、Salesforce、Snowflake等。
Mage的用户界面还提供在部署之前预览你创建的管道的功能。
此功能允许用户可视化和检查其管道的结构和功能,确保在上线之前一切设置正确。通过提供此预览选项,Mage可帮助用户识别任何潜在问题或可能需要的调整,最终实现更顺畅的部署流程并提高整体工作流程效率。
Mage的关键概念与Prefect中的非常相似:项目、块、管道、数据产品、回填、触发器和运行。
交互式笔记本用户界面允许我预览代码的输出,这是我最喜欢的功能之一。
Orchestra,2024
Orchestra由HugoLu于2023年创建,是新一代编排器解决方案,专注于无服务器架构,将一切统一在一个平台上。
优点
- 无服务器模块化架构:你不再需要Kubernetes集群。
- 快速交付:几分钟内构建企业级业务流程。
- 增强监控:不要浪费时间识别错误。
- 最先进的集成:数百种开箱即用的集成。
结论
这项研究强调,强调异构性、支持多种编程语言、有效使用元数据以及采用数据网格架构是构建现代、强大且可扩展的数据平台的数据管道编排的重要趋势。
例如,ApacheAirflow提供了各种预构建的数据连接器,可促进跨各种云供应商(包括AWS、GCP和Azure)的无缝ETL任务。但是,它缺少任务内检查点和缓存等功能,并且未针对机器学习管道进行优化。
预计对多种编程语言的支持将成为未来几年的重要趋势。例如,Temporal可容纳各种语言和运行时,而Airflow主要强调Python。
数据网格时代的协作是数据领域成功的关键。你的组织可能有单独的数据管理、分类模型和预测模型团队,所有这些团队都可以协作使用同一平台(例如Mage或Flyte)。这使他们可以在同一工作区内操作而不会干扰彼此的工作。
我们可以看到各种用于数据提取和转换的ETL框架的“寒武纪大爆发”。毫不奇怪,其中许多都是开源的并且基于Python。
感谢阅读!你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/。
原文作者:MikeShakhomirov
翻译作者:诗彤
美工编辑:过儿
校对审稿:Jason
原文链接:https://towardsdatascience.com/how-data-engineering-evolved-since-2014-9cc85f37fea6



