
数据揭秘六大航空公司究竟如何窥探顾客情绪?
说到情感分析,它其实是自然语言处理的一个小分支,就是如何处理短文本。对于短文本,业界通常是建立一个分类器,分析文本的情感极性,然后将分析的结果作为一个有价值的新feature,嵌入到更大的数据集中,从而得到重要的商业结论。
我们这次的项目主题是看六大航空公司如何窥探顾客情绪,数据集是Twitter US Airline Statement。
那么,在了解如何窥探顾客情绪之前,我们先来窥探一下数据集:
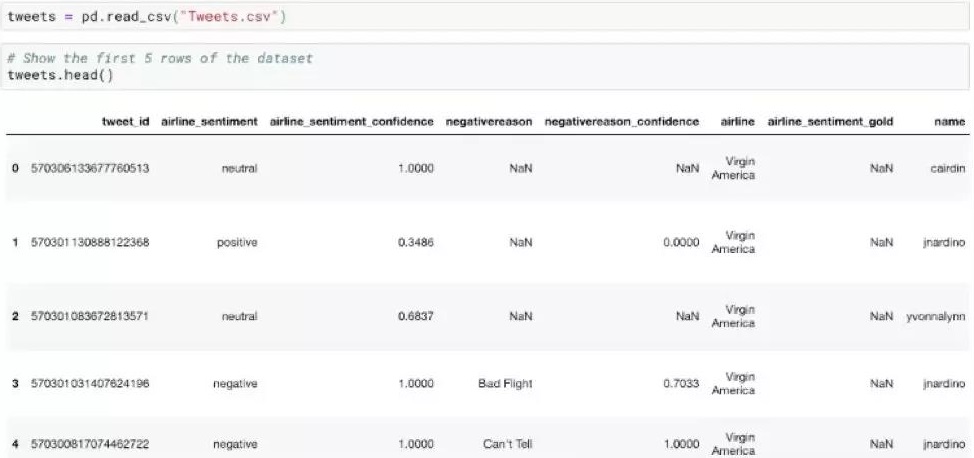
在这个数据集中,我们会用到的有:
– Airline_sentiment
– Airline_sentiment_confidence
– Negativereason
– Airline
在具体分析之前,我们先把数据按照好评、差评、凑合分成三类。
由此可见,乘客们对航空公司的意见还是蛮多的🤷♀️。

接下来就让我们看看这些意见的情感了!
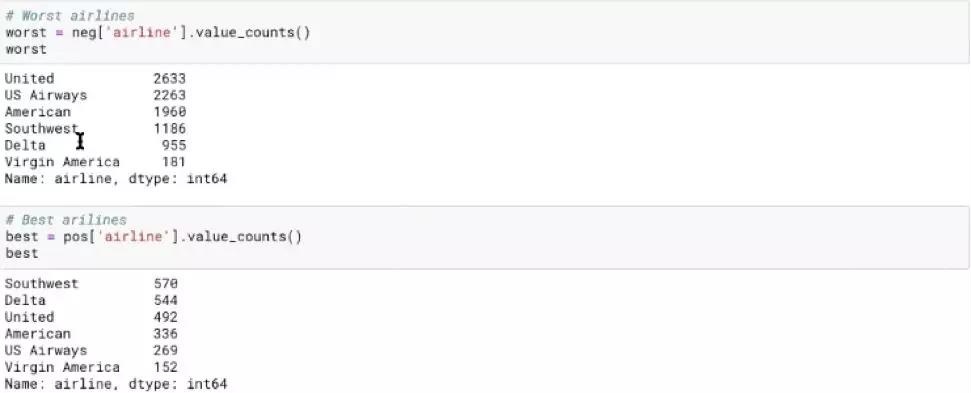
从这个结果已经可以得到一些insights了,比如US Airways好评少差评多,估计是没什么前途了。
这种方法有没有什么问题呢?当然有。首先,单纯通过数值来比较是不科学的,因为航空公司收到的反馈总量肯定不同;其次,如果数据集比较小,所得到的反馈的参考价值可能不大。
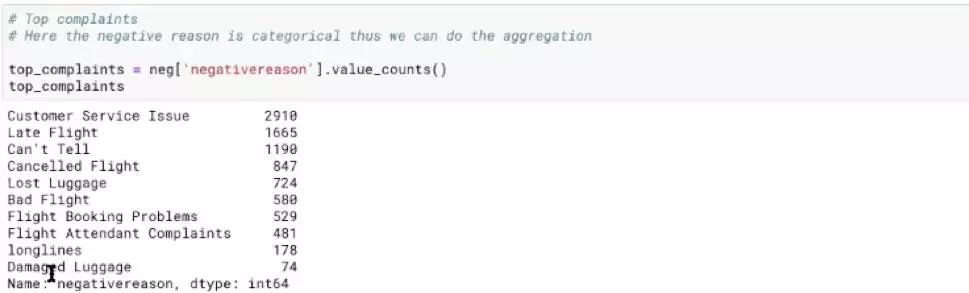
这个分析还是很make sense的。非常明显,大部分用户的吐槽点都是customer service。+1!!

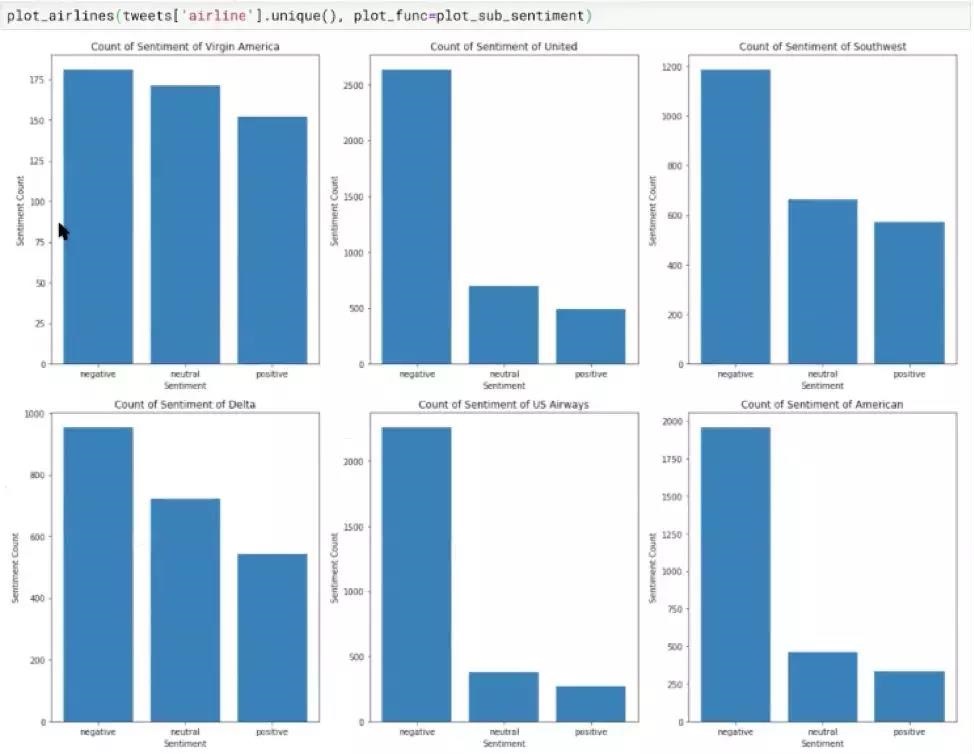
这样画图分析之后,就直观了很多。但凡是negative和别的评价数量相差比较大的,都是比较差的航空公司了🤷♀️
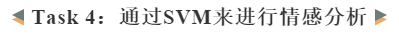

关于train_test_split,看似很简单明了,但是你知道如何根据分析之后的结果对模型进行改良么?
如果train score很低,那么就是你的模型不行,去改模型吧!如果train score 很高,test score反而低,那么就是你的模型overfitting了!如果train score和test score都很高,但是evaluation score不高,说明training dataset 和evaluation dataset分布不同!
下图是对文本的向量化处理。Tokenization将文本中的词根据它们在文本中出现的次数转化成了向量,使用lemmatize的方法,把单词都变成了它原来的形式,名词变成单数的形式,动词变成动词原形。这样做是为了使我们的单词表不会太大,生成的向量维度不至于太高。
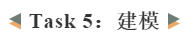
下图就是建模的过程了。选择线性的kernel,通过grid search的方法调参,就可以得到最终的模型了!
更多关于情感分析,NLP的讲解,欢迎关注我们的LinkedIn 中文账号 @数据应用学院(美国)看公开课视频回放!





