
这个关于春招必考的爱情故事,写出了贝叶斯的前世今生
统计学分析一直是数据分析中的重要一环,而贝叶斯统计又是统计学中一个比较大的分支,在面试中也经常考到。所以,了解贝叶斯统计是稳赚不赔的。
贝叶斯统计和传统的频率统计最大的区别就是,贝叶斯统计是先有一个假设,然后基于通过实验获得的数据,对之前的假设进行改良。

下图就是贝叶斯公式,A事件是先发生的,B事件是后发生的。贝叶斯公式解决的问题是,已经知道后面发生的事件B,计算在B发生的前提下,先发生的事件A可能发生的概率。比如说,我们已知今天下了雨,然后我们想知道昨天多云的概率是多少。
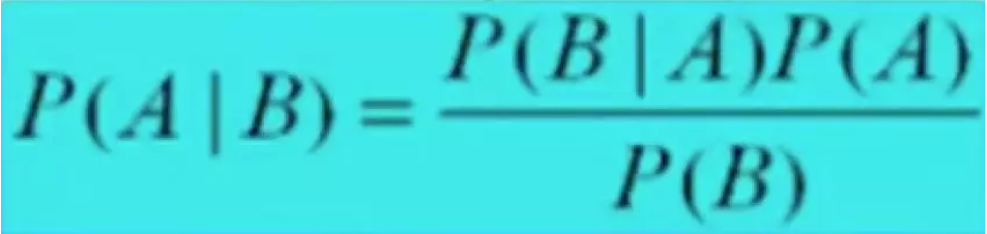
其实,知道后面的事情发生,求之前发生的事情发生的概率,这本身是不成立的,然而使用这种理论来解决很多问题都意外的有效。这也就是贝叶斯统计厉害的地方。

贝叶斯统计一般都有什么用途呢?它的用途可不是简单的求平均值方差等计算,它往往被用来进行分析推断。那么什么是推断呢?就是根据样本数据,根据生活当中所发生的事情,进行分析和推理的过程。传统频率学派的推断,是直接根据给出的数据来进行推断;而贝叶斯推断,如下图,则是先有了一个假设(prior),也就是先验概率,然后依据所得的实验数据,求得在这些实验数据发生的基础上,原来的假设会表现为一种什么样的形式,也就是后验概率。
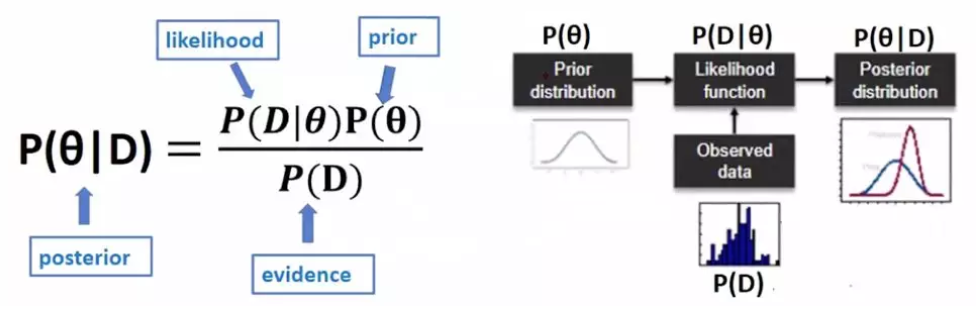

那么,普通的频率推断和贝叶斯推断的区别是什么呢?它们最大的区别是 random 的来源不同。
我们知道,每一次的推断和预测背后都是有一个真实的概率的,只不过这个真实值基于非常庞大的数据,我们无法得到(比如人口的分布,下雨的可能性,大选结果等)。
基于频率的推断,是没有预假设的,它是直接从总样本里进行抽样,统计符合条件的样本,然后进行概率的计算。所以对它来说,这个分布的 θ 是固定的,因为总样本的分布是固定的,且没有预假设,但是样本是随机从总样本里抽取的,所以频率推断的随机性来源于样本。
而所谓贝叶斯推断呢,是先有了预假设,也就是假设数据的分布可能符合参数是θ的分布,通过获得的真实存在的数据来看假设的分布是否成立,求出最大的likelihood,来得出基于这些真实数据的情况下,整体的分布,或者这个分布的参数θ最有可能是什么样的。所以它的数据是固定的,真实的,而θ是随机的,可修正的。
举一个简单的例子,如果班里有50个人,现在要估计这50个人的平均身高。如果用频率推断的方法,也就是求一个点估计,直接在50个人中取出20个人,求出这20个人的平均身高,就认为这20个人的平均身高就是这50个人的平均身高;而对贝叶斯推断而言,这样的点估计是不存在的,贝叶斯推断是假设50个人的身高符合一种分布,然后用实际的数据去修正之前假设的分布。
拿线性回归做一个简单的对比。

对频率分析而言,线性回归就相当于是最小二乘法;而对贝叶斯推断而言,则是先假设一个普通的模型,然后不断去改良。如你所见,这两者的区别不在于模型,而在于分析方法。在数据集比较大的情况下,它们的分析结果基本相同,但是它们各有优劣。
频率分析不需要做预假设,运算量相对于贝叶斯而言小一些,但它在数据量比较小的时候的结果可能不如贝叶斯分析得准确。
贝叶斯分析需要做预假设,运算量比频率分析的方法大,但其实对现在的科技发展水平而言,这种级别的运算量已经不再是什么问题。它的另外一个缺点是不太容易解释给其他部门的人,让别人明白你到底做了什么。





