")
数据科学的新生代工具(附实操代码)
自从“数据科学”进入人们视野以来, 它一直被用来形容处理那些一台电脑装不下的大数据。所以,处理大数据的能力被认为是数据科学概念的核心。虽然Mapreduce依然是基础工具,但很多新涌现的有趣工具已经超越了它的基本功能。比如说,Mantel-Haenszel 计量就无法在基本的Mapreduce中运行。Spark和Google Cloud Dataflow正是下一代数据处理体系的代表。本文将结合笔者的第一手经验和调研对两者进行比较。
引言
Mapreduce是设计大规模数据(成百上千TB)处理pipeline的方法。在Google框架内外,Hadoop/Mapreduce都已经被广泛地使用。(对一些人来说, Hadoop就是数据科学的同义词)。 但是, 书写复杂的Mapreduce程序很快就会让人很痛苦。 正是Mapreduce的局限性,让Spark和Google Cloud Dataflow涌现,并在不同的方面显现优势。从两者最终产品上微妙但明显的差异上就能看出来:Dataflow将Google框架与复杂批量pipeline(比如FlumeJava)或实时pipeline(比如MillWheel)匹配; 而Spark则是当初加州伯克利设计用来实现探究分析和大规模机器学习的。
六个月前,Google将Cloud Dataflow的程序模型和软件开发工具包(SDKs)捐给了Apache软件基金,孵化了Apache Beam。将来,Apache Beam将成为展示数据处理pipeline的工具,而Cloud Dataflow则保留为运行这些pipeline的管理职能。如果说程序模型和API(应用程序界面)是Beam的话,那Cloud Dataflow就是运营GCP的服务。本文的代码示例使用当前Dataflow的SDK;Apache Beam使用类似的概念和编程模式。
本文将比较Spark和Beam/ Dataflow的异同。从两者框架差异 考虑,因为框架的考虑,Spark善于处理探索分析、交互分析和迭代算法,比如梯度下降法gradient descent 和马氏链蒙特卡罗法MCMC;而Dataflow的优势则在于处理流数据和高度优化、灵活的数据。文章的其他内容还包括:两者最重要的不同点和框架的主要差异;举例如何分别应用Spark和Beam/ Dataflow,以及如何进行流处理;用Spark编写聚类算法clustering algorithm的示例。
不满足于Mapreduce
Mapreduce是一个简单平行数据处理的优秀工具,但如果想用Mapreduce处理更复杂的pipeline,问题出现了:
· 处理复杂pipeline需要关键的样本文件、独立的项目包 和层次之间的“界面”
· 在硬盘中写入pipeline层次之间的交互结果是一个瓶 颈,这要求使用者手动优化这些分支的设置
· 运行探究分析要求同时读写硬盘,这会变得很慢
· 不支持流pipeline(原始数据来源,极少延迟)
· 编写多层次pipeline时很容易被卡住,比如用曼特尔― 亨塞尔法(Mantel-Haenszel)衡量一个随机实验 参数和指标有效性(参见下文)
Spark和Beam/ Dataflow 通过将Mapreduce步骤的结果储存下来,优化和减少步骤,在内存中储存必要的交互结果,解决了以上的大部分困难。Dataflow中的PCollections和Spark中的RDD(resilient distributed dataset )不需要写入硬盘,它们只需要重新存回内存里。
核心差异:图像评估
Spark和Beam最根本的不同在于:Spark只建立必要的计算图,而Dataflow在优化和发给服务器或云端执行之前就建立了完整的计算图。其他主要的差异也根源于此。所以,Spark很适合用来做交互分析(来自python或scale的解释器),或用来做机器学习算法的模型;但用Dataflow就很难实现。澄清一点,不是说Dataflow不能做机器学习——简单的流算法是没问题的。但很多机器学习算法,比如比如梯度下降法gradient descent 和马氏链蒙特卡罗法MCMC,需要决定在趋同之前需要多少迭代;而Spark就提供了高度的灵活性。
然而,建立完整计算图的好处是,执行Beampipeline的系统(比如Dataflow)可以优化整个计算图。更重要的是,从执行中分离计算图架构使Beam可以重新呈现和语音无关的计算图。这样,Dataflow图可以在其他的分布处理后台中执行,包括Spark。这也是建立Apache Beam项目的初衷。
Beam对整个计算图进行详细读取的另一个影响是,Dataflow将作为一个功能存在。这种“将pipeline作为一种功能运行”的模式将读取计算图、输入数据,并输出数据。 Cloud Dataflow Service可以看成是一个黑匣子,处理的细节包括使用的虚拟存储器的数量、每一级甚至总体的层次、任务分配等等。需要的时候,这些信息都可以查看更多的细节。 这是Spark一个很显著的不同,因为Spark是聚类导向(集群导向, cluster-oriented),而不是任务导向的。在Spark里运行一个固定pipeline时,我们会在建立集群cluster-运行pipeline-重建集群中循环。虽然有很多工具(比如 Cloud Dataproc on GCP 或 Databricks on AWS)简化这个过程,但用户依然非常重视集群管理。
超越Hadoop/Mapreduce
为了更好地比较这两个新工具,我将演示如何用两种方法解决同一个问题,并且突出它们的不同。假设我们拥有一个产品众多的在线拍卖网站。客户浏览产品图片,查看拍品描述,并决定是否竞标。因为这是一个竞拍网站,所以每一个产品的价格都在实时变化。产品范围跨度很大,从几块钱的Emoji橡皮到几千元的自动咖啡机都有,所以追踪产品的一个重要方法是按产品目录分类。
我们将做一个随机控制实验,来评估买卖中高像素图片的有效率。比如,我们希望知道控制组对平均售价的影响。最简单的做法是比较控制组和参照组的平均售价。但这可能会得到误导的结果—因为就算在每一样商品的价格保持不变、且只有产品组被影响的情况下,这样的比较肯定会产生有差异的结果。
具体一点,假设高像素图片为咖啡机带来的销量比Emoji套装的多。曼特尔―亨塞尔法(Mantel-Haenszel,或Cochran-Mantel-Haenszel) , 正是通过平衡测试组和参照组中的变量来解决这个问题。基本的概念,是分别计算测试组和参照组中每一个独立样品(比如每一副图片)的平均价格,然后得到测试组相对于参照组的价格权重组合。 MH的核心是,这种权重组合对于测试组和参照组都有效,并且因为筛选方法一致而最大程度地减少了其他变量的影响。
预测法和延伸应用在医药界的计数数据中被广泛应用,Google的数据科学里更是无处不在。 将来我们还会专门讨论在Google分析中的应用和扩展。现在,让我们先看这个非技术数据的价格案例。我们以产品目录(i)为分类,测试组和参照组分别售出nti和nci, MH预测法对两组间价格交叉调整的公式为:
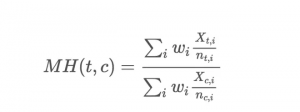
权重wi是nti和nci的调和平均值。简化计算时我们可以将公式写为:
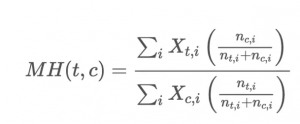
记得排除nti+nci=0的情况。以下是一个csv的架构:exp_id, product_id, price, sale_count 。
如果要用Mapreduce来计算MH价格指数,需要3次程序:

这很可能会得到一组庞大的code,因为一个基础的计数就需要接近60行的标准java code。感兴趣的读者可以看看延伸阅读:Hadoop/Mapreduce versus Spark,比如 Dattamsha上的这篇文章 Hadoop/MR vs Spark/RDD WordCount program。
用python写MH
相比这些乏味的code,更喜欢python的朋友可以看这个github在jupyter notebook soluteon的例子Spark vs Dataflow。为了更好地比较,我从code中提取出两个商业逻辑,分别是 calc_numerator 和 calc_denominator;这两个功能可以计算上述公式里的数量、特定商品的价格数据,并计算分子和分母。
用Apache Spark写MH
打开Spark shell,为PATH添加组件,在pySpark/shell。py运行execfile(更多detail查看notebook)。然后编写Spark代码:
from operator import add
# We want to calculate MH(v_{t,i},n_{t,i},v_{c,i},n_{c,i}), where t and c are treatment
# and control. v and n in our cases are value of the sale prices and sale_count.
input_rdd = sc.textFile(‘sim_data_{0}_{1}.csv’.format(NUM_LE, NUM_HE))
header = input_rdd.first() # Remove the first line.
parsed_input_rdd = input_rdd.filter(lambda x: x !=header)
.map(lambda x: convert_line(x.split(‘,’)))
transformed = parsed_input_rdd.map(lambda x: ((x[exp], x[prod]),
(x[sale_count]*x
(sp, clks) = (0, 1) # sale price and sale_count
(ep, spc) = (0, 1) # exp_id&product_id, sp&sale_count
(exp2, prod2) = (0, 1) # exp_id, product_id
# For each product cross exp_id, sum the sale prices and sale_count
grouped_result = transformed.reduceByKey(lambda x,y: (x[sp]+y[sp], x[clks]+y[clks]))
grouped_by_product = grouped_result.map(lambda x: ((x[ep][prod2]), (x[ep][exp2], x[spc][sp], x[spc][clks]))).groupByKey()
numerator_sum = grouped_by_product.map(lambda x: calc_numerator(x)).reduce(add)
denominator_sum = grouped_by_product.map(lambda x: calc_denominator(x)).reduce(add)
effect = numerator_sum / denominator_sum
print(numerator_sum, denominator_sum, effect)
Spark的功能有两种:transformations处理文档中(比如地图或文件夹)中记录的数据,actions让数据被识别(比如利用groupByKey, reduceByKey)。核心的区别就是是transformations只在覆盖到的地方执行,其他的部分不会产生直接的影响,这也是我们说Spark进行‘懒惰评估’。
除了商业逻辑,程序只运行很少的几行代码:
- sc.textFile(…) transforms a file on disk into an RDD (the distributed data structure in Spark)
- input_rdd.first() acts on the RDD returning first, header, element to the driver (my notebook).
- input_rdd.filter(…).map(…) transforms input_rdd removing the header then converts each csv line into floats and ints.
- parsed_input_rdd.map(…) transforms records into key-value tuples ((exp_id, product_id), (cost, clicks))
- transformed.reduceByKey(…) acts on transformed causing input_rdd.filter(…).map(…) and parsed_input_rdd.map(…) to be executed and produces the total clicks and cost by (exp_id, product_id)
- grouped_result.map(…).groupByKey() acts to produce the same data, only grouped by product_id instead of product_id and experiment_id.
- grouped_by_product.map(…).reduce(add) transforms the data per product_id into the numerator and denominator of the MH calculation and then performs the action of summing the results using the add function.
用Apache Beam写MH
Dataflow跟Spark的的代码框架有少量的不同,总体上很类似,但却有很重要的区别。 区别中的一个缺点是,Dataflow至今还没有一个reduce的总功能,所以我要自己写代码(t_sum)。注意这个code用Dataflow SDK (而不是新的Beam SDK)。
Beam在概念上是两个部分:pipeline建设和pipeline执行。 beam.Pipeline()返回一个pipeline,p,在其上构建(使用beam.Map,beam.GroupByKey等)和p.run()在Dataflow的服务器或者在本地集群上执行Pipeline。
- beam.Pipeline(options=pipeline_options) begins constructing a pipeline to run locally.
- p | beam.io.Read(…) | beam.Filter(…) | beam.Map(…) add reading the file, filtering lines that look like the header (starting with ‘#’), converting each line into floats and ints to the graph.
- parsed_input_rdd | beam.Map(…) adds mapping each record to be keyed by exp_id, product_id to the graph
- transformed | beam.CombinePerKey(…) | beam.Map(…) | beam.GroupByKey() adds summing clicks and cost by exp_id, product_id and regrouping by product_id to the graph
- grouped_by_product | beam.Map(…) | beam.CombineGlobally(…) adds calculating the numerator/denominator values and the global sum to the graph
- numerator_sum | beam.Write(…) adds a sync for the numerator (there is a matching output for the denominator).
- p.run() optimizes constructed graph and ships the result to be executed (in our case the local machine)
应用的比较
总体来看,两个应用很相似,都利用了相同的平行基础操作。不同的是Spark只在行动(比如reduceByKey)中执行图片; 而Beam(比如CloudDataflow), 在运行的同时执行了整个图片。 另一个不同是,Dataflow要求有sources和sinks,这意味着结果必须用pipeline输出到文件中,而不能输出到发出指令的程序(除非使用本地运行器)。
Spark的优势:整合算法
起初Spark是探索性研究和机器学习的解决方案。最简单的展示就是集群技术k-means集群。 K-means的基本原理是不断地重复两个步骤:分配每一个聚点到集群中,然后以此更新集群中心。直到集群中心被最终固定下来。以下就是用Spark写的核心算法。
# Load the data, remove the first line, and pick initial locations for the clusters.
# We put the x,y points in pt_rdd, and RDD of PtAgg (a class containing x, y,
# and count).
pt_rdd = parsed_input_rdd.map(lambda x: PtAgg(x[0], x[1], 1))
MAX_STEPS = 100; MIN_DELTA = 0.001; delta = 1.0; step = 0
while delta > MIN_DELTA and step < MAX_STEPS:
step += 1
c_centers_old = copy.deepcopy(c_centers)
b_c_centers = sc.broadcast(c_centers_old)
# For every point, find the cluster its closer to and add to its total x, y, and count
totals = pt_rdd.map(lambda x: pick_closest_center(x, b_c_centers.value)).reduce(
lambda a,b: center_reduce(a,b))
# Now update the location of the centers as the mean of all of the points closest to it
# (unless there are none, in which case pick a new random spot).
c_centers = [t.Normalize() if t.cnt != 0 else random_point_location() for t in totals]
# compute the distance that each cluster center moves, the set the max of those as
# the delta used to the stop condition.
deltas = [math.sqrt(c.DistSqr(c_old)) for c, c_old in zip(c_centers, c_centers_old)]
delta = max(deltas)
s = ‘ ‘.join([str(x) for x in c_centers])
print(‘final centers: {0}’.format(s))
在这过程中,我不需要真的写这些代码,因为Spark有ML library(mllib),提供了包括k-means在内的很多算法。实际上,k-means只是很小的一个功能。
在表征上,最大的不同就是: Beam不能表达迭代算法,包括k-means。这是因为Beam建立、优化并输出了整个图片。在迭代算法中,不能事先知道整个图片框架(不知道要建立多少步骤),所以不能在里运行“loops”。用Dataflow表达loops是可以的,但只局限于添加固定数目。
Beam/Dataflow的优势:流处理
对于数据科学,流处理是一个越来越重要的话题。毕竟,谁愿意等日常输送pipeline告诉我们实时数据到底表现得怎么样。关于流处理入门,我强烈推荐Tyler Akidau的两篇博客 The world beyond batch: Streaming 101和 102。
当Dataflow发布时,它最吸引人的卖点就是流处理。不是说Spark不支持或缺少应对大量的流数据的统一处理能力。Dataflow的重要步骤是:
1. 统一的批量和流API。
2. 支持处理实时数据的事件,也就是在它们发生的 时候就分析结果,而不是等到数据到达分析机器 的时候 。
3. 水印(一个追踪无界数据收集过程的方法)和窗口提 示完成进度(即收集完毕该阶段的所有数据)。
事实上,Dataflow,现在是Beam,提供一个流API,解决了流处理问题的核心:what,where,when,how。 现在有不同的支持等级,这是没有意义的,比如Dataflow支持Java的流处理,但不支持Python的。
从Dataflow团队最近在blog上公布的例子就能很容易看出这一点。他们通过计算一个在线游戏每小时的团队积分来比较这两者的不同。
其他框架”哲学”的不同
有几个设计上的特点可以看出Spark钟意默认的快速开发,并要求用户进行选择性执行,而Dataflow选择以稍慢的开发时间来换取更好的表现。
超高速缓存caching
Dataflow通过”熔合”相同输入的同级层次来避免了caching。 熔合带来的局限性是不应该使用不稳定的类型,因为熔断的层次之间共享相同的数据,这样调和会产生无效的结果(可以通过run-time来核实)。 这意味着写正确的Beam代码需要对不稳定的类型格外注意。Spark默认双执行,比较慢但不需要担心正确的问题。Spark也支持不同类型的超高速缓冲方法。
等式
在GroupByKey和其他步骤中,Dataflow使用快速的、非语言的、程序化的byte级别的等式来比较classes。如果程序使用组合运营来管理classes,这将会是一个问题,Hashmaps或导致语义等式跟byte等式不一样的结果的任何东西都可能是原因。Spark并行classes,默认用class’s comparison operator做grouping,允许用户选择byte级别的等式。
总体表现
很遗憾,现在我们还不能下定论说哪一个框架比较好。唯一一个比较两者的文章使用的是比较旧的版本Spark1.3,但Spark 2.0有了显著的更新,所以还不清楚现在哪一个系统的表现比较好。
总结
Spark和Dataflow从不同方面解决了Mapreduce的不足,哪一个系统更适合得取决于项目本身。如果是交互性,数据探索或算法开发方面的,Spark可能是更好的选择。如果处理复杂的流计算(特别是实时事件),Beam可能会表现更好。而对于运行大规模生产pipeline,Beam on Cloud Dataflow也许更适合。
原文: David Adams
翻译:胡丁凡
编辑:Yvette Niu





