
一文带你了解 Google 的数据科学Agent
过去十年,数据科学领域呈现爆炸式增长,通过从数据中挖掘洞见,改变了各个行业。然而,构建端到端数据科学管道的过程(从数据清理和预处理到模型训练和评估)仍然复杂且耗时。
Google的数据科学Agent (Data Science Agent)是一款直接嵌入Google Colab的突破性工具,旨在根据提供的数据集自动生成完整的数据科学管道。这项创新代表着人工智能和机器学习民主化的重大飞跃,使各个级别的用户都能以前所未有的轻松方式充分利用数据科学的全部功能。
在本文中,我们将深入了解 Google 的数据科学Agent、它的功能、工作原理、实际用例、与其他工具的比较以及它对数据科学未来的意义。
什么是 Google 的数据科学Agent?
Colab环境中的下一代 AI 助手。通过利用大型语言模型和特定于数据科学的推理引擎,该Agent可以:
- 分析用户上传的数据集。
- 自动理解数据的结构、类型和上下文。
- 生成完整的数据科学管道,包括:
- 数据清理
- 探索性数据分析 (EDA)
- 特征工程
- 模型选择和训练
- 评估指标
- 可选部署策略
Colab中以人类可读和可编辑的 Python 代码形式呈现输出,使用户能够逐步检查、修改和运行它。
主要特性和功能
Colab无缝集成
该Agent在 Google Colab界面中运行,因此用户无需安装任何新工具或软件包。它使用自然语言指令来指导工作流程,即使对于初学者来说,界面也很直观。
2. 自动化 EDA 和可视化
一旦加载数据集,Agent就会自动:
- 检测数据类型
- 识别缺失值
- 建议可视化技术
- 生成统计摘要
Plotly以情节和叙述解释的形式呈现。
3.智能特征工程
Agent应用智能转换:
- 分类变量的独热编码
- 标准缩放或规范化
- 创建派生特征(例如基于日期的特征、文本嵌入)
4.模型选择与训练
根据问题类型(分类、回归、聚类),Agent:
- 选择合适的模型(例如随机森林、 XGBoost 、SVM)
- 使用交叉验证来提高性能
- GridSearchCV或Optuna提供超参数调整
5. 评估和解释
该Agent包括:
- 性能指标,如准确度、F1 分数、AUC-ROC、RMSE 等。
- 使用 SHAP 和 LIME 的模型可解释性工具
- 混淆矩阵和特征重要性图表
6. 代码透明度和可编辑性
生成的每个代码块都是完全透明且可编辑的。用户可以修改、重新运行和改进代码,从而促进实践学习体验。
工作原理
Google 的数据科学Agent建立在由 Gemini(Google 的 LLM)提供支持的多Agent架构之上,专注于工具增强推理。工作流程如下:
步骤1:数据集上传
用户将.csv 、 .xlsx或.json文件直接上传到Colab 。Agent会解析文件并推断架构。
步骤2:意图识别
使用自然语言提示(例如“预测房价”),Agent可以识别手头的任务——分类、回归还是无监督学习。
步骤3:管道建设
Agent构建模块化管道组件:
- 数据采集和初步检查
- 预处理函数
- 建模和评估代码
- 可选:部署到云服务或通过pickle / joblib导出
步骤4:用户交互
在每个阶段,用户都可以向Agent查询解释(例如,“为什么删除此功能?”)或请求更改(例如,“使用XGBoost而不是随机森林”)。
不同用户群体的益处
1. 初学者和学生
Agent充当实时导师,展示最佳实践并逐步指导用户。它降低了数据科学教育的入门门槛。
2.数据分析师
现在,即使不是机器学习专家的分析师也无需深度编码即可构建预测模型和高级见解。
3. 专业数据科学家
对于经验丰富的专业人士,Agent可以加速探索阶段,为日常任务提供样板代码,然后进行进一步微调。
4. 企业和初创企业
概念验证模型的周转时间更快意味着更快的迭代和更灵活的数据驱动决策。
真实用例
用例 1:客户流失预测
上传客户数据 CSV,Agent将自动:
- 清理数据
- 执行 EDA
- 选择分类模型
- 使用 AUC-ROC 和混淆矩阵进行评估
- 重点介绍导致客户流失的主要因素
用例 2:房地产价格估算
给定一个住房数据集:
- 特征工程包括日期和位置转换
- 训练XGBoost或线性回归等回归模型
- 输出包括 SHAP 图和 RMSE 指标
用例 3:根据健康数据进行医疗诊断
- 处理缺失的临床值
- 应用集成模型
- 使用可解释性工具来证明决策的合理性
与其他工具的比较
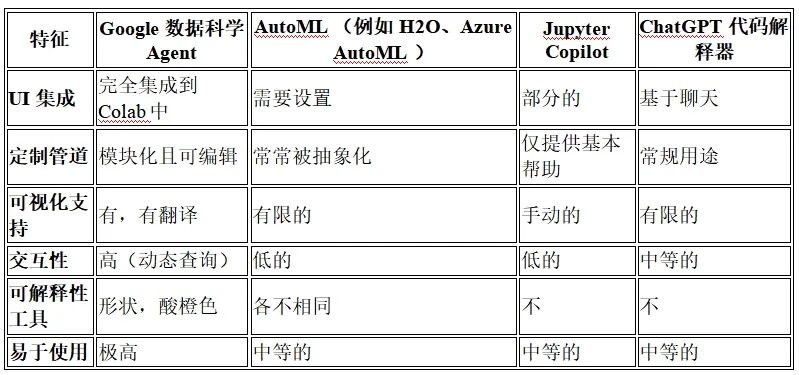
谷歌的方法平衡了自动化和用户Agent——用户不会被锁定在黑盒结果中。
挑战与限制
尽管它功能强大,但仍存在一些局限性:
- 数据集大小限制: Colab 的内存限制仍然适用。
- 自定义模型:高级用户可能会发现某些 ML 模型并非立即可用。
- 互联网依赖性:该工具基于云并依赖于在线访问。
- 可解释性:虽然包含了 SHAP,但更细微的可解释性(如反事实或因果关系)仍处于早期阶段。
这对数据科学的未来意味着什么?
Google 的数据科学Agent代表了我们处理数据工作流程方式的转变:
- 人工智能作为合作者:LLM 不再仅仅是工具,而是编码过程中的副驾驶。
- 加速人工智能素养:学生和专业人士可以通过示例进行学习——亲手实践真实代码和指导反馈。
- 标准化:跨项目和用户一致的最佳实践。
- 工作转型:常规数据准备和样板建模现已实现自动化,专业人员可以专注于策略、解释和领域知识。
入门提示
- 打开一个新的 Google Colab笔记本。
- 通过文件侧边栏上传您的数据集。
- 从“工具”菜单启用数据科学Agent。
- 通过以下任务来提示它:
- “建立一个分类模型来检测垃圾邮件。”
- “清理并分析这个数据集。”
- “创建一个洞察仪表板。”
5. 与生成的代码进行交互并提出后续问题。
最后的想法
Google 的数据科学Agent不仅仅是另一个人工智能助手,它向更智能、更快速、更易于访问的数据科学迈进了一步。通过将其嵌入到熟悉且广泛使用的 Colab环境,谷歌降低了高级分析的门槛,让更广泛的受众能够参与机器学习。
无论您是刚开始数据之旅的学生、寻求加快工作流程的专业人士,还是在没有专门团队的情况下寻求见解的企业主,此工具都能提供切实的价值。随着法学硕士的不断发展,此类工具标志着数据世界中人类与人工智能之间新协作时代的开始。
感谢阅读!你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/。





