
预测流失模型:数据怎样帮助维持用户粘性?
用户粘性是公司关注的焦点。获得用户的代价一般是比维持一个用户的5-25倍还要多。然而,你不会想要把你所有的用户放进维持项目中。你可能最后把那些不想被打扰的用户赶走。另一方面,一些用户想要离开,不管你给他们提供什么。那么你怎样来确认哪些用户值得花时间精力维护呢?
答案是用户流失模型
但是这个不像你把数据扔进一张工作表然后建立一个模型那么简单。你可能通过许多不同的来源得到用户数据。在每一个用户的人口数据统计之外,像他们什么时候第一次成为用户和住在哪里,或许你有他们的购买或者产品使用历史记录,你可能有他们与你的支持团队的交流和调查结果。合并这个数据能提供更多的信息到为什么一个用户可能流失。所以,你怎样把这所有的数据整合到一起呢?
流失对你的公司意味着什么?
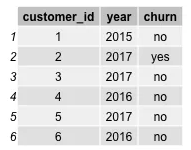
在合并你的数据源之前,这里有重要的数据和商业指标要考虑。第一也是最重要的:你需要定义流失对于你意味着什么。它是用户不会在接下来的30天购买?还是下一年?或者你是一个以订阅为基础的公司,你的流失取决于一个用户是否更新他们的订阅?对于这些的问题的答案将定义你怎样创造你的目标变量(流失)以及你想要专注的时间线。
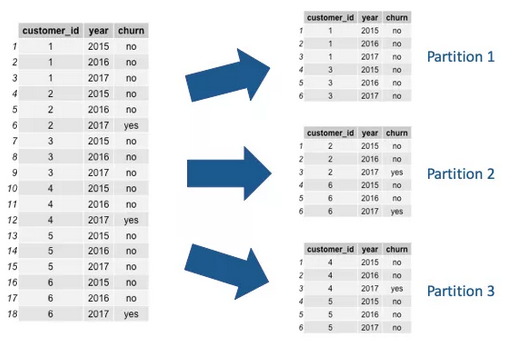
下一个要解决的问题是,你有多大的数据?如果你有成千或者百万的用户,然后你能从一个固定的时间段简化你的用户。一个用户在这个数据集中不应该超过一列。
但是如果你仅有很少的几百个用户呢?如果你的数据被有限的单位限制,然后你可以创建一个每一列代表对一个用户一个时间段的数据集。时间段将取决于你怎么定义流失。如果你定义流失是在未来30天内的购买,那么时间段就是1个月,每一个用户将有一些列等同于他们曾是一个用户的月数。如果你的用户是每年订阅,那么时间段就是1年。在这个情况下,你的数据是累积的。按用户切分你的数据很重要。
如果一个用户的数据分离成多个部分,那么你的样本外的预测将不是真的样本外的,并且你的模型将过度拟合你的训练数据。
最后,你需要明白你的公司将用这个用户流失模型做什么。如果一天时间不足以说服用户留下,这个模型有多么的好来预测明天哪些用户会流失?客服人员会使用这个模型来花费额外的时间在最有可能流失的用户吗?你能营销集体优惠打折或者优质产品来说服用户留下吗?这不仅仅影响你的模型的时间段,还会给予你需要在数据中包括的变量的线索。
时刻注意你预测的时间的未来,你的模型会需要更少的数据来平衡。因此你的模型的准确率很大概率会减少。与你的模型预测的用户紧密合作将确保他们得到他们需要的能够信任的模型的商业结果。
怎样避免前瞻性误差
我们在流失模型中最常见的错误是前瞻性偏差。
对于流失模型,它很容易包括你不会在你的模型的时间段中的数据。举个例子,如果你预测在一月一日那些用户会在下一年离开,那么你不能包括在二月购买的数量。相似的是,如果你的随机样本选择一个用户是否在2017流失,并且你其中的一个变量是月平均消费,然后你需要小心地不去计算用户的各个使用期限的月平均消费。它必须是2017年以前的消费。提前考虑潜在的目标的流失量能帮助你的模型在生产环境中表现得如预期一样好。
原文作者:Jake Snyder
翻译作者:Yan Wang
美工编辑:过儿
校对审稿:Dongdong
原文链接:https://www.datarobot.com/blog/predicting-churn-how-data-can-help-with-customer-retention/





