
SQL和Pandas同时掉到河里,你先救谁?
在我的数据分析生涯中,我几乎完全是在SQL中锻炼我的技能。虽然SQL可以做一些非常酷的事情,但它有它的局限性 – 这些限制在很大程度上让我决定了要不要去感受数据科学别的巨大魅力。在我之前的数据岗位中,我需要分析来自外部源的数据文件和工具,但这些工具限制了它可以处理的数据量或花费过多的时间,使任务变得几乎不可能彻底完成。
在我所有职位中有一个数据pipeline有点像这样:
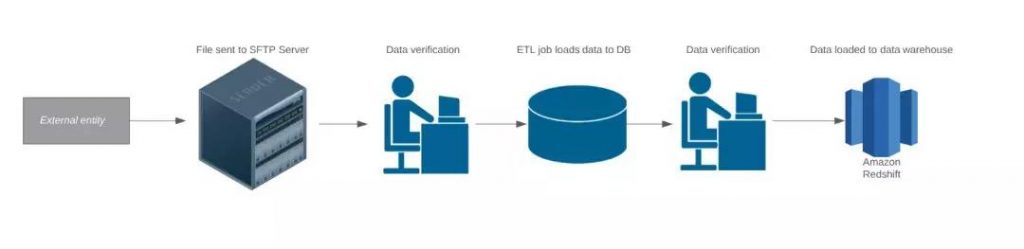
当我们收到了来自外部来源的数据,需要进行质量分析而且我们需要理解ETL的要求。当我们使用excel来做这件事的时候,任何尝试使用excel进行大型文件分析的人都知道这是一场噩梦。所以我们编写excel宏,但由于每个数据文件都是如此不同,所以它们并不有用。其他数据分析的工具通常不是天上掉下来的,得花钱的,但是帮你付钱的爸爸如果不能切身感受到你的pain,那他们就会拒绝做你的爸爸。
但是世界在我搜索了 Python Pandas Library 变得清凉了。
卧槽,这么刺激免费有用高级的东西!我居然现在才发现!
Pandas

Pandas与SQL不同,Pandas有内置方程。当数据已经是文件格式(.csv,.txt,.tsv等)时,Pandas允许我们在不影响数据库资源的情况下处理数据集。
我将解释并展示一些我真正喜欢的功能的例子:
pandas.read_csv()
首先,我们需要将数据存为data frame。一旦我们将其设置为变量名称(下面的“df”),我们就可以使用其他函数来分析和操作数据。在将数据加载到data frame时,我使用了’index_col‘参数,这个参数将第一列(index = 0)设置为数据帧的row label。有时我们需要调整多个参数来让我们的data变成正确的format。如果这个dataframe被设为为一个variable, 那么这个方程不会返回output, 但你可以用下面的方程来观察数据。
# Command to import the pandas library to your notebook
import pandas as pd
# Read data from Titanic dataset.
df = pd.read_csv(‘…titanic.csv’, index_col=0)
# Location of file, can be url or local folder structure
pandas.head()
head方程非常有用,只需在我们之前的的dataframe的variable名称后加.head(), 默认设置是显示前5行,但咱们也可以通过调整数值来改变 例如.head(10)。
df.head()

前5行的数据
我们可以看到数据里有一些String,Int,Float,有些列有NaN值。
pandas.info()
info方程将给出数据帧列的细分以及每个列的非空条目数, 而且还会告诉我们每列的数据类型以及数据框中的总条目数。
df.info()

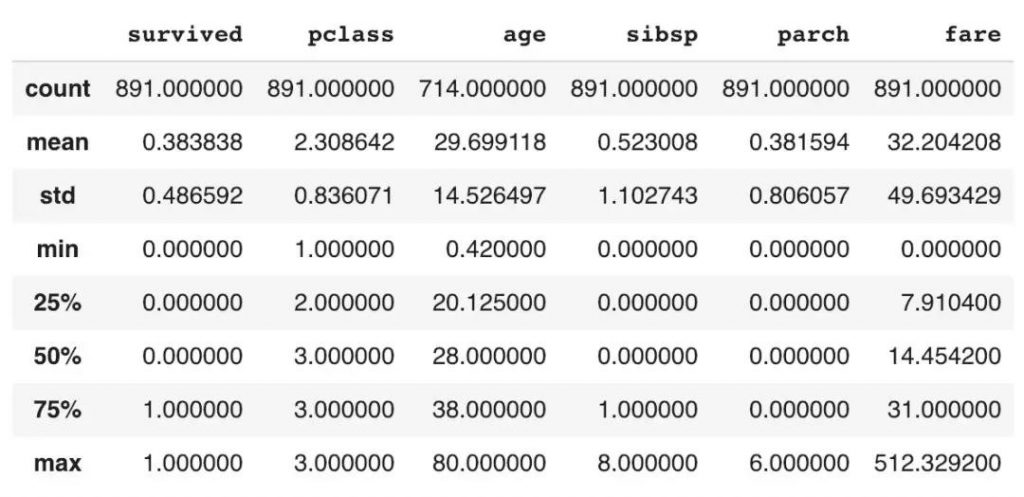
pandas.describe()
describe函数对于查看数据的分布非常有用,特别是像int和float这样的int类型。如下所示,它将返回一个数据框其中包含每列的均值,最小值,最大值,标准差等。
df.describe()
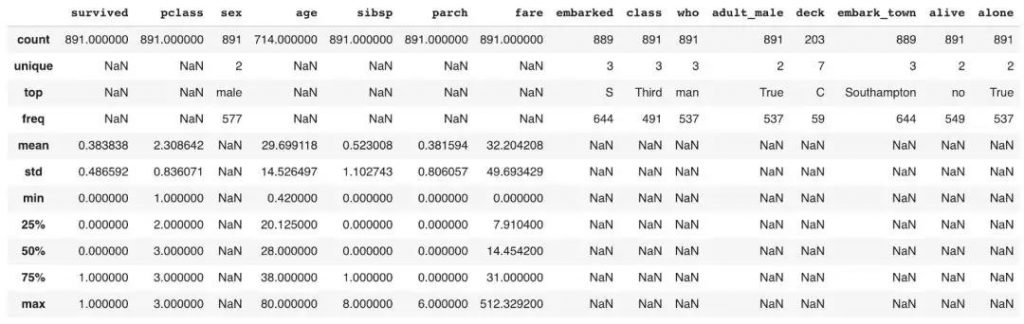
如果我们要查看不仅仅numeric而是所有类型的variable,就必须使用include参数。但值得注意的是“unique”,“top”和“freq”会被加入进dataframe中。这些仅针对非Numeric数据类型和NaN显示。对于这些新的Row,其他对应数字的细分都是NaN。
df.describe(include= ‘all’)
pandas.isna()
单独的is.na 方程自己不是非常的有用,它将返回整个数据帧为False,如果有NaN或NULL值,返回True。如果你在is.na()中包含.sum(),那么你将获得类似下面的输出,显示每列的NaN或NULL的个数。
df.isna().sum()

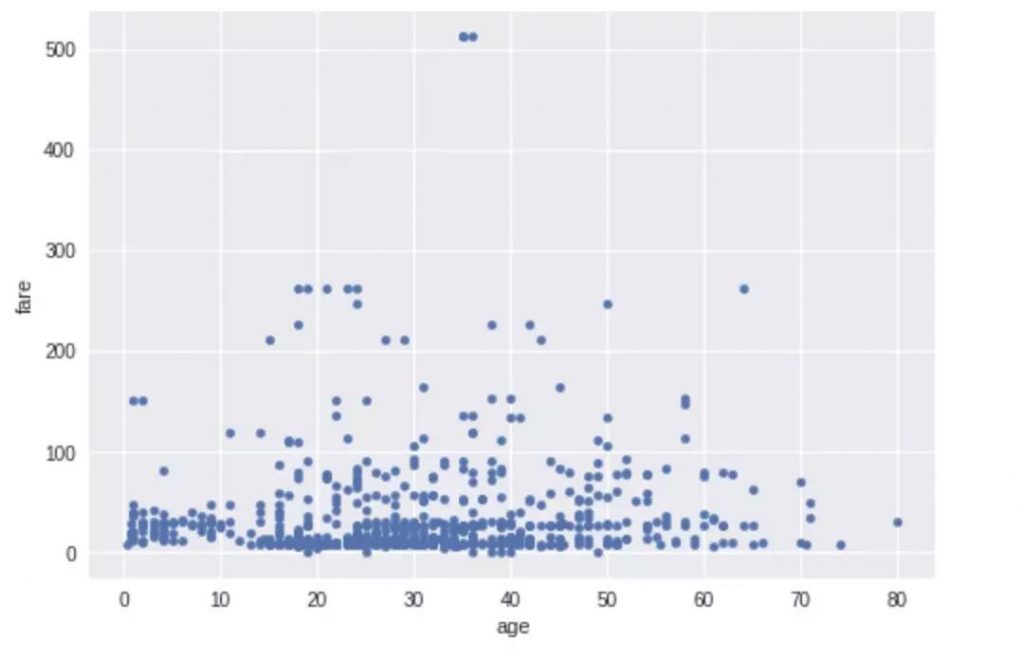
pandas.plot()
Pandas绘图功能对于快速可视化数据非常有用,这个此函数使用matplotlib进行可视化.
df.plot(x =’age’,y =’fare’,kind =’scatter’)
这些只是我用于初始数据分析的一些有用的Pandas函数。我们可以在此处找到更多关于pandas的用法。
什么时候使用SQL? 什么时候使用 Pandas?
使用哪种工具取决于数据存储的位置,想要使用的数据和自己的优势。如果你的数据属于文件格式,则无需使用SQL进行任何操作。如果你的数据来自数据库,那么咱们应该通过以下问题来了解应该使用SQL。
对于数据库,你有多大的进入权限?
如果你只有写一个 query 的权限,真正运行是别人来做的话,你大概就不能真正透彻地了解你的这组数据。这个时候,你要做的就是把你觉得你可能需要的所有数据都 pull 下来,然后导出成一个 csv,然后用 Pandas 去处理。
或者
如果你知道你要 run 的这个 query 会占用这个数据库很大的资源,然后数据库的 admin 大概率会不爽的话,那你就在数据库之外用 Pandas 处理。尽量避免在你的 query 里使用 SELECT*,特别是你无法琢磨你的 table 里会生存多少数据的时候。
你想要怎么 transform / join 你的数据?
如果你已经知道你将如何处置你的数据了,比如你打算加哪些具体的 filter,或者把数据 join 进某个具体的 table,或者把两组数据通过某种计算或者集合 combine 一下,等等;那这个时候选择使用 SQL 会简单一些。你可以通过 SQL 把你的数据都 pull 下来然后导成一个 CSV 再来进行接下来的数据分析或者建模等等。
你知道自己的强项是什么嘛?
这其实是最重要的一个问题,你知道自己最强的地方在哪么?如果你知道自己和谁相处更舒适一些,那就不要犹豫!贴紧它!榨干它!做整条街最靓的仔!
总结一下:
这两个工具都非常有用,我建议大家同时学习。该组合将使我们能够更有效地进行广泛的数据分析和操作。很快,你将不再需要处理令人崩溃的Excel了。
原文作者:Kailey Smith
翻译作者:Zihao
美工编辑:Miya
校对审稿:卡里
原文链接:https://towardsdatascience.com/sql-and-pandas-268f634a4f5d





