
如何巧用数据可视化,讲好一个故事?
原文作者:SHANTANUKUMAR
原文链接:https://www.analyticsvidhya.com/blog/2017/10/art-story-telling-data-science/
翻译:Xin Qin
- 6%的男性司机认为发短信会导致分心,相比之下,只有4.2%的女性司机这样认为。
- 9.8%的男性司机认为车中有儿童会导致开车分心汽车里,而女性司机中则有26.3%。
另一种方式则是把这些统计数据重组,进行数据可视化。
你觉得哪一种方式更好地讲述了一个故事呢?
- 为何要讲故事?
- 如何创造一个故事?
- 从一纸一笔开始
- 深入挖掘故事的最终目的
- 有力的标题
- 设计一个roadmap
- 简洁的结论
- 数据类型和使用的图表
- 文字[wordclouds]
- 混合[facet Grids]
- 数值[折线图/条形图]
- 股票[烛台图]
- 地理[地图]
- 预测建模中的讲故事
- 数据挖掘
- 特征可视化
- 模型创建
- 模型比较
- 一些实用的tips
- 小结
- 为何要讲故事?
讲故事是一门既简单又复杂的艺术。 故事能够激发出思想,展示出以前难以理解或解释的观点。然而讲好故事的重要性经常被我们在数据操作中忽视。
然而我们不知道的是,如果没有被良好地表达出来,故事本身再好也是没有用的。
在公司中,分析任何事情的第一步是讲故事。例如我们为什么要分析它? 通过分析我们可以做出什么决策?有时候,数据本身会告诉我们这样的视觉化的、复杂的故事,我们并不需要运行复杂的相关性检验来确认它。
而需要故事和视觉化来解释数据的最好的例子是Anscombe的Quartet。Anscombe的Quartet是一组四个数据集,它们的统计数据非常相似,但是将它们可视化之后却完全不同。
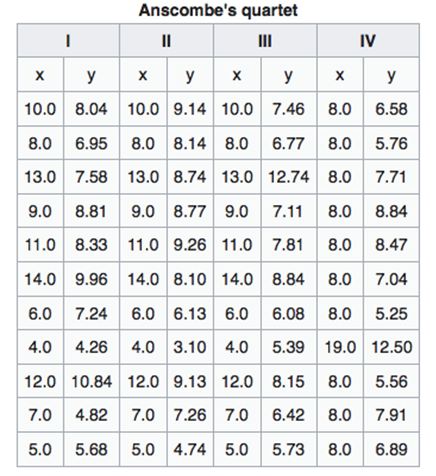
上表是Anscomb’sQuartet中使用的四个数据集。 如果我们只看数字,我们发现他们的统计数据几乎是一样的。
但是可视化之后呢?
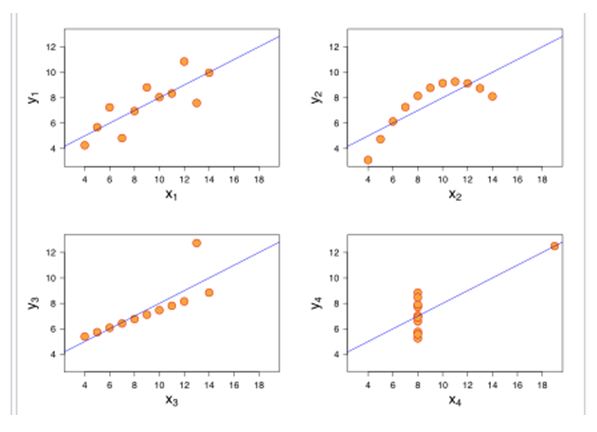
你有猜想过这四组数据可视化之后的差距会如此大吗?
- 如何创造故事?
创造一个故事或一个情景是推销你的想法的第一步。大多数人都不思考自己的故事,所以也无法展现特殊性。 下面的例子,能够帮助指导你进行故事创作。
我们将探索一个数据集,其中包含纳斯达克100所科技公司每股价格的新闻标题和细节。所选columns如下。

最好的展示通常仅仅始于一纸一笔。在开始构建故事之前,确定思路和流程非常重要。为此,我们可以参考亚里士多德经典的五步骤:
1.引起观众兴趣的故事或陈述。
2.提出一个必须解决或回答的问题。
3.为该问题提出解决方案。
4.解释采用解决方案的具体好处。
5.呼吁行动。
我组织报告的方式是设计情节,这些情节能够使我更好地理解数据。
面对我拥有的股票数据,我的第一个想法是,如何做出更好的投资决策?
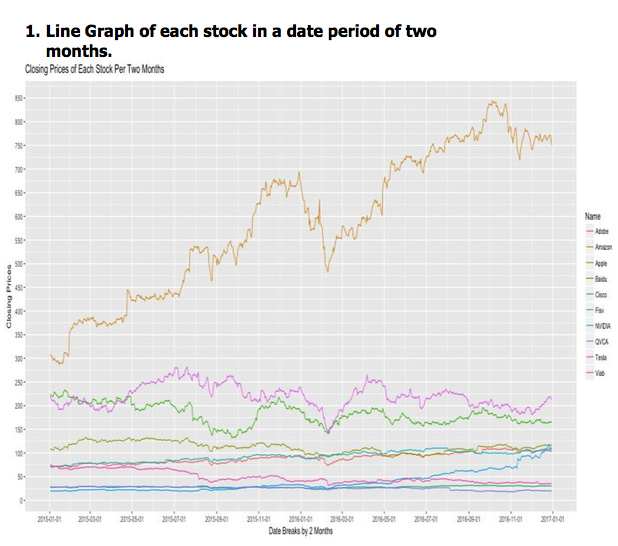
折线图可以帮助我分析特定股票价格的趋势。如图所示,2016年2月份所有股票都下跌了。那么我将只从搜索这个时期的新闻文章,以确定是什么原因造成了下降。现在,我该如何选择哪个新闻来源呢?
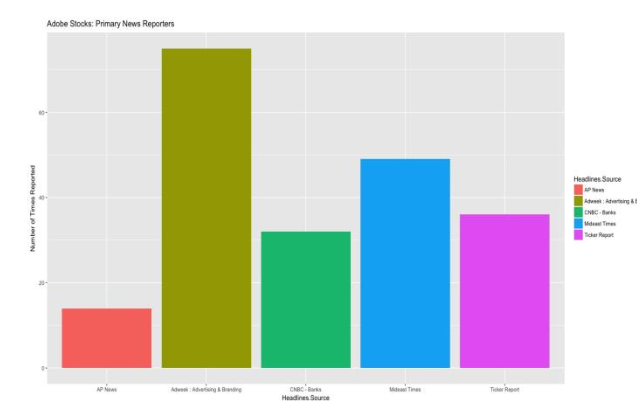
通过识别哪个新闻来源最频繁地提到一支特定的股票,我们有理由相信这是这支特定股票的好的新闻来源。
仔细确定你的故事的核心是什么。 问自己:“我通过这个故事得到什么?”不是故事本身,而是通过这个故事可以做出什么更好的决策。
阐述你的“passionstatement”。用简单的话表达你的立场和观点,以及你为什么有热情去研究它。

给你的故事、图表或分析创建标题,通常是一句陈述。 最有效的标题通畅是简洁的、具体的、有价值的。
标题要能够很好地被观众所理解。
列出所有让观众了解故事,图表或分析的所有关键点。
对所有关键点进行分类排序,直到只剩下三个最主要的。这三个点将组成你的故事的roadmap。
在三个关键信息下,增加支持论据。这些可能包括:个人经历,事实,例子,类比等

展示完所有的关键信息和论证,你需要的是一个简短有力的结论。正如我的报告中,只用3-4行话来总结为什么要买一支特定的股票。

- 数据类型和适用的图表
常见的数据类型有:
当我们得到的是文本数据,我们通常会去研究这些文本词语被使用的频率或者文本表达的情感。
当以这种形式找到数据时,找出一个单词被使用的频率或文本的情感是很好的。 故事可以使用这种形式的数据最好地被告知。
文本数据最适合的可视化方式之一是WordCloud。 wordcloud将出现频率最高的词语放到中央并放大,能够让我们清楚地了解文本的整体状况。
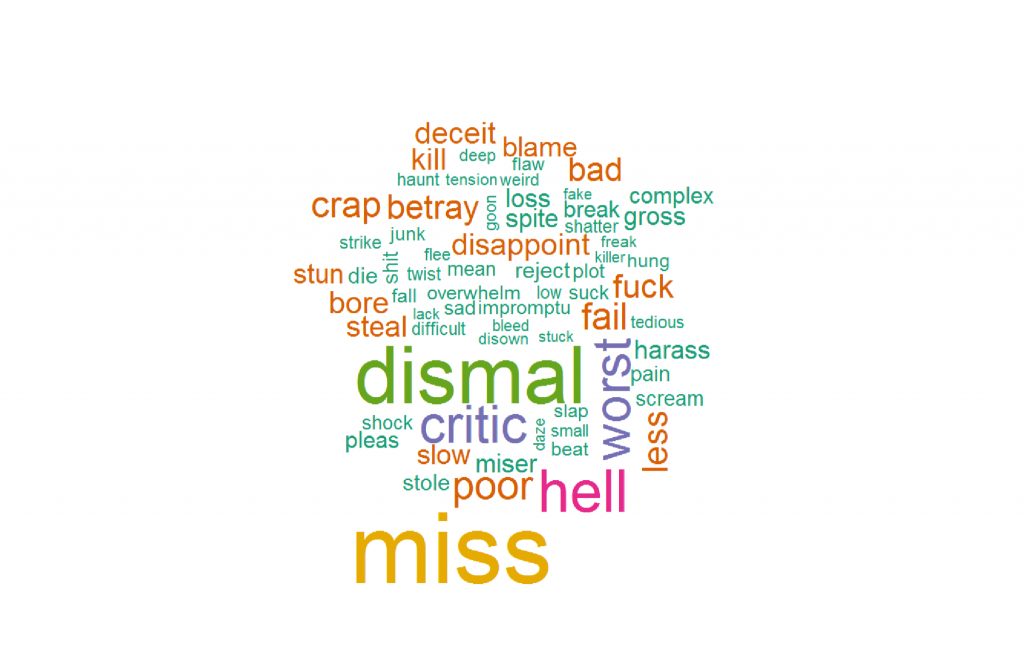
例如,这篇文章中的分析就使用了wordcloud来展现推特数据集。
当我们的数据由数字或其他格式组成时,我们需要知道哪些数据是重要的能产生观点和价值的。
这种数据适合的图表在不同情况下不尽相同; 在此我将展示如何使用facet grids来描述泰坦尼克号乘客数据。
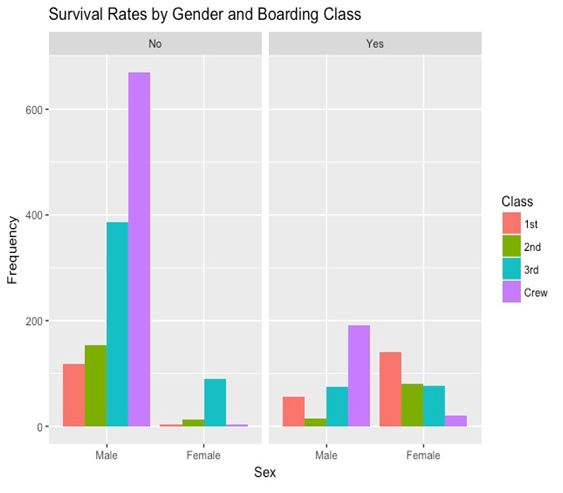
正如上图所显示的,女性乘客和一等舱的乘客比男性或低等舱的乘客有更高的生存机会。
泰坦尼克号上真的发生了这样的故事么?
另一种可视化这种数据的方法是尝试多变量图(multivariate plot)。用于该图的数据集是关于汽车性能和规格的数据集。
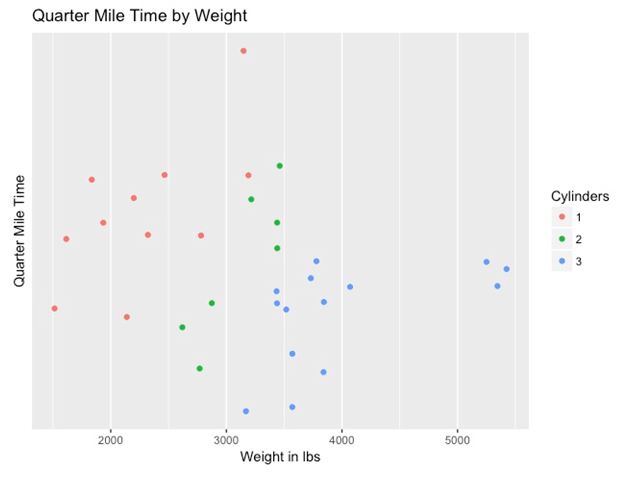
从上图我们可以看出车体较重的汽车比车体较轻的汽车开得慢,而这也符合逻辑,不是吗?
当遇到数值数据时,我们通常会研究如何描述数字的趋势。 最适合数值数据的图表是折线图或条形图。
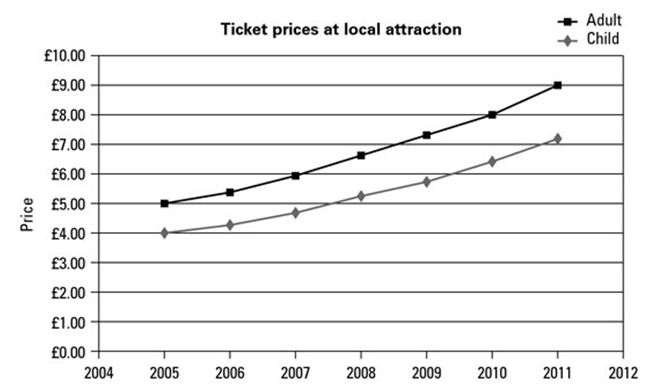
在这里,我们可以清楚地看到本地景点的成人票价和儿童票价的上升趋势,以及每年价格上升程度。
股市的数据主要是数值的时间序列数据,但作为交易者或投资者,我想了解每个具体日期的涨跌情况,对此最合适的图表是烛台图。
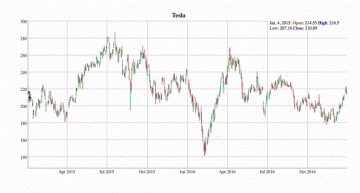
在这里,我们以特斯拉的股票为例。烛台图可显示每个日期股价的波动以及股价的最高值和最低值。我们根据当前或过去的市场趋势可以做出更好的投资决策。
如图所示,2016年2月特斯拉股票下跌。我们可以利用这些信息来进一步分析市场和经济状况,作出投资决策。
针对关于特定地点和地区的数据时,我们使用地图来助力分析。
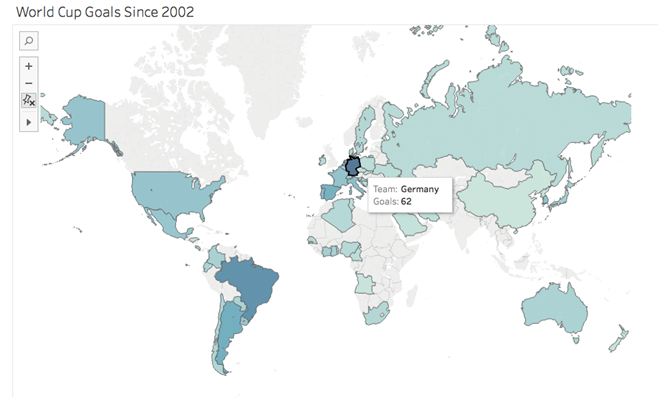
在上面这个例子中,我们可以看到2002年世界杯比赛时及之后各个国家队的表现。德国队进球数量最多,成为世界足坛的主导球队之一。
- 请预测建模中的讲故事
通常在建立数学模型时,我们会质疑我们的故事和可视化是否有作用。然而在预测建模的各个阶段,讲故事可能是分析的一个重要补充。
模型构建的第一步是理解数据。那么如何在不计算复杂的统计数据的情况下理解数据呢?
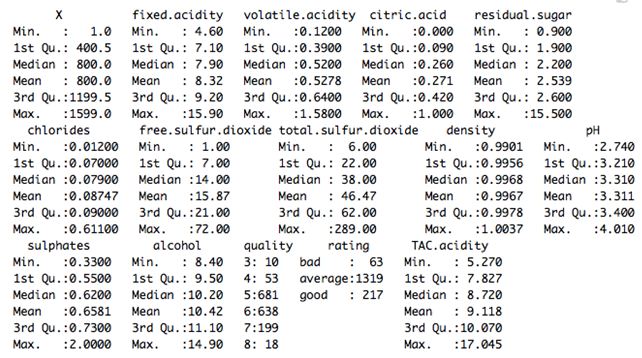
我们来考虑一下WineQuality的数据集。数据集的结构如下:
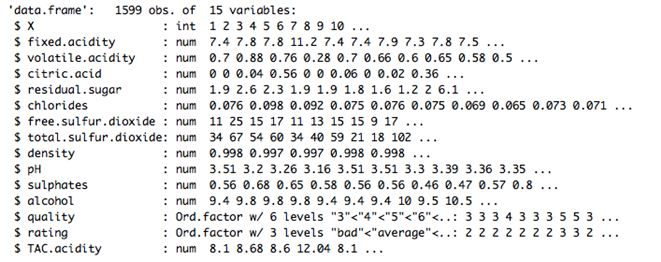
这里我们可以看到数据集的相关汇总统计数据。
如果我们需要看看酒精含量和葡萄酒的质量之间是否存在相关性,我们该怎么做?
我们可以计算Pearson’r’。 这将有助于我们建立一个模型,但无法帮助我们进行进一步分析。
![]()
这表明酒精含量和葡萄酒质量之间有很强的相关性。但它有告诉你什么其他的吗?
但是我们可以通过可视化发现更多。
首先,我们看葡萄酒的质量和酒精含量之间的联系。
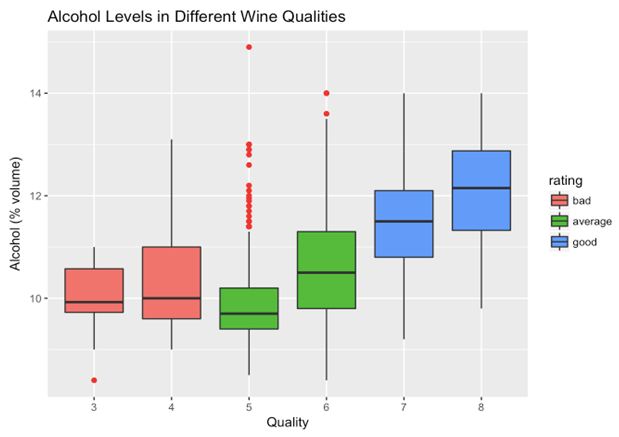
我们可以看到酒精含量越高对应的葡萄酒质量越高。我们还可以通过图中的点看出数据中的outliers。
下一步,你会想酒中的酸度是否会影响质量?
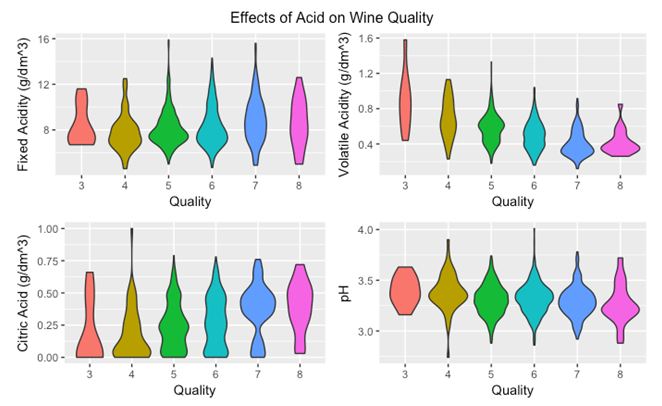
提琴图横向扩展,表示的是这个区域内有更多的数据点。
当你建立特征值之后,如何知道它们能否准确预测?
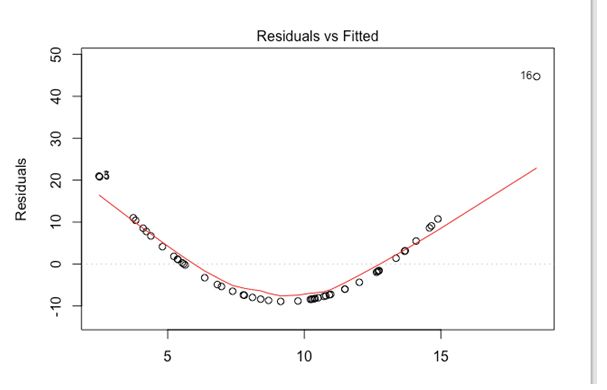
上图告诉我们预测点(predictedpoints)离我们的拟合线(fitted line)有多远。
另一个需要创造性可视化的例子是主成分分析(Principal Component Analysis)。 如果你想深入了解PCA,您可以阅读这篇文章。
以下是在RStudio中建立的Iris数据集。
当我们用该数据集进行主成分分析,我们得到以下统计数据。

而当我们作图之后,会发现图表比这些统计数据更有信息表现力。
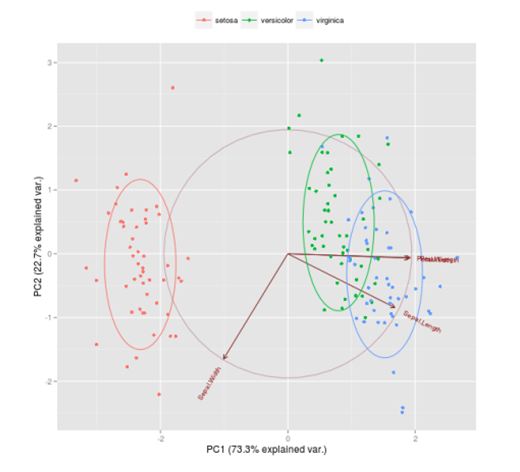
进入模型建立的阶段,我们需要理解模型和数据的拟合程度。
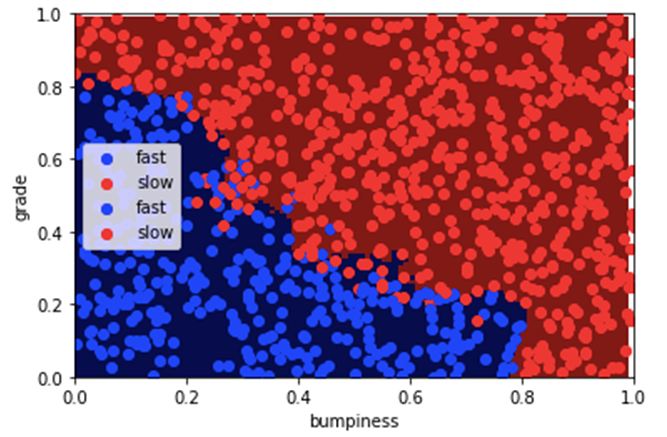
上图是根据道路坡度和颠簸程度来预测汽车行驶速度快慢的模型。判别边界(decision boundary)清楚地分类了大部分的数据,但是准确率为88.21%并不能说明一个完整的故事。在这里,我们甚至可以看到错误分类点距离判别边界有多远。
我们可以通过观察判别边界来比较特定的算法和技术。
下面关于支持向量机的是另一个使用Iris数据集的例子。
在这里我们没有足够的信息得出关于模型的有效观点。
要了解更多关于支持向量机(SupportVector Machines )的内容,请参考这篇文章。
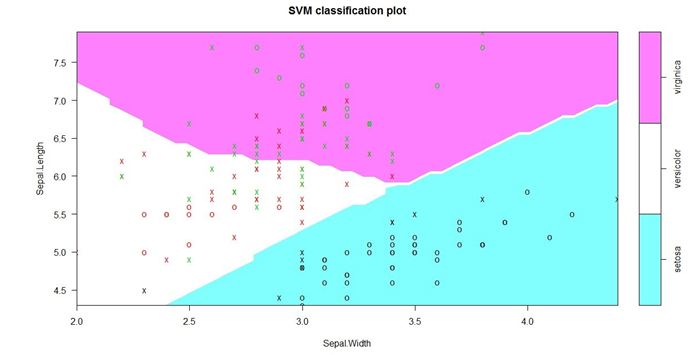
但是这张图向我们展示了物种彼此区分的清晰的分界线(classification boundary)。
- 一些实用的tips
- 现在你知道了我们可以通过讲故事来解释观点,这还有一些展示时更实际的tips。
- 在图中标出坐标轴,并给出标题。
- 必要时使用备注
- 使用不刺眼的颜色
- 避免将不必要的细节添加到图表中,如复杂的背景或主题。
- 基于水平和垂直位置的两个定量值只能用一个点同时编码。
- 进行时间序列编码时,不要用点进行可视化。
- 小结





