
别犯这5个数据科学家常见错误,你就已经一只脚迈进FAANG了
你为最终成为一名数据科学家做了充分准备。你参加了Kaggle的比赛,疯狂地看了Coursera的课程。你觉得自己准备好了,但事实将证明,作为一名现实生活中的数据科学家的工作与你可能预期的大相径庭。
这篇文章检验了早期数据科学家的5个常见错误。榜单是由Sebastien Foucaud博士发布的,他在指导和领导学术界和工业界的年轻数据科学家方面有20年的经验。这篇文章旨在帮助你在现实生活中更好地准备你的工作。
让我们开始吧。 👩🏫👼🦄🐣
1. 进入“Kaggle时代”
你已经参与了Kaggle挑战并练习了你的数据科学技能。你可以把决策树和神经网络叠在一起,这很好。说实话,你不会像数据科学家那样做那么多的模型堆积工作。请记住,作为一般规则,你将花费80%的时间预处理数据,其余20%的时间构建模型。
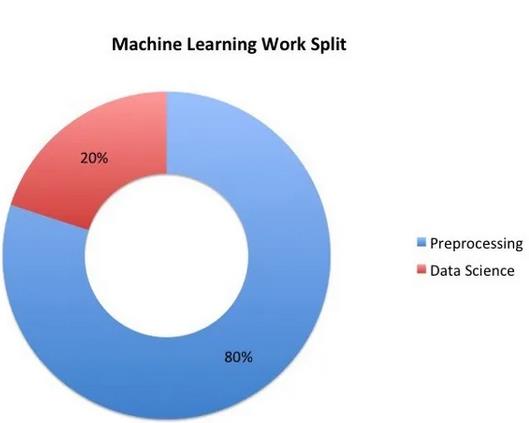
成为“Kaggle时代”的一份子在很多方面都很有帮助。数据通常得到完美的清理,以便你可以花时间调整你的模型。但在实际工作中很少出现这种情况,因为在实际工作中,你必须使用不同格式和命名惯例从不同来源收集数据。
你将使用80%的时间做艰苦的工作和练习技能,数据预处理。从API中抓取图像或收集它们。收集来自Genius的歌词。准备好解决特定问题所需的数据,然后将其输入笔记本,练习机器学习的生命周期。精通数据预处理无疑会让你成为对公司有直接影响的数据科学家。
2. 神经网络是治愈的良药
深度学习模型在计算机视觉或自然语言处理领域优于其他机器学习模型。但它们也有明显的缺点。
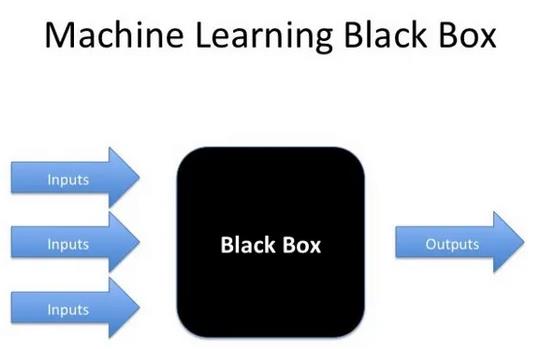
神经网络非常需要数据。如果是使用较少的样本,使用决策树或逻辑回归模型通常会更好。神经网络也是一个黑盒子。众所周知,它们很难解释。如果产品负责人或经理开始质疑模型的输出,你必须能够解释模型。对于传统模型来说,这要容易得多。
正如James Le在这篇文章中解释的那样,有很多很棒的统计学习模型。教自己学会它们。了解它们的优缺点,并根据用例的局限性来应用模型。除非你的工作领域是计算机视觉或自然语音识别,否则最成功的模式很可能是传统的机器学习算法。你很快就会发现,通常最简单的模型(如逻辑回归)是最好的模型。
3.机器学习就是产品
机器学习在过去的十年里经历了巨大的炒作。太多初创企业承诺,机器学习可以解决存在的任何问题。
机器学习本身就不应该是产品。机器学习是创造满足客户需求的产品的强大工具。如果客户能从收到准确的商品推荐中获益,机器学习可以提供帮助。如果客户需要准确地识别图像中的物体,机器学习可以提供帮助。如果企业能从向用户展示有价值的广告中获益,那么机器学习可以提供帮助。
作为一名数据科学家,你需要以客户的目标为主要优先级来规划项目。只有这样,你才能评估机器学习是否有用。
4. 混淆因果关系和相关性
大约90%的数据是在过去几年产生的。随着大数据的出现,对于机器学习从业者来说,数据已经变得唾手可得。有这么多数据要评估,通过学习模型发现随机相关性的可能性就会增加。
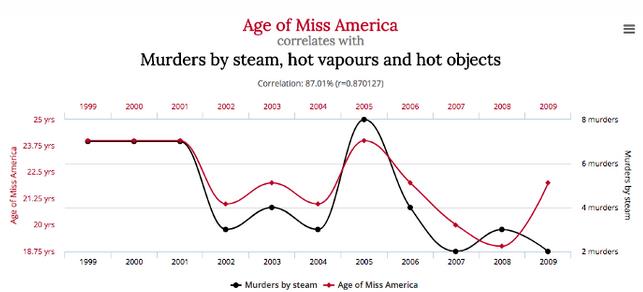
上图显示了美国小姐的年龄以及通过蒸汽、热蒸汽和热物体被谋杀的总数。有了这些数据,一个学习算法就会了解到美国小姐的年龄会影响被某些物体谋杀的次数,反之亦然。然而,两个数据点实际上是不相关的,两个变量对另一个变量绝对没有预测能力。
当发现数据中的模式时,应用你的领域知识。这可能是一种相关性还是因果关系?回答这个问题是从数据中引导出行动的关键。
5. 优化错误的指标
开发机器学习模型要遵循agile生命周期。首先,定义想法和关键指标。其次,生成结果的原型。第三,你要不断改进,直到你满足关键指标。
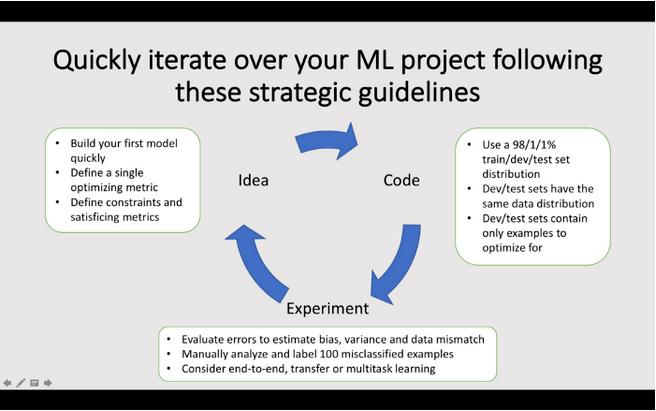
当建立一个机器学习模型时,记住要做一个手动的错误分析。虽然这个过程很繁琐并且需要精力,但是它将帮助你在接下来的迭代中有效地改进模型。请参阅下面的文章,从Andrew Ng的深度学习专门化中获得改进模型的其他技巧。
年轻的数据科学家为公司提供巨大的价值。他们从头学习网络课程,之后可以立即提供帮助。他们通常是自学成才的,因为只有少部分大学提供数据科学学位,因此他们表现出极大的投入和好奇心。他们对自己选择的领域充满热情,渴望学习更多。所以要想在你的第一份数据科学工作中取得成功,要小心上述的陷阱。
关键点回顾:
- 练习数据管理
- 研究不同模型的优缺点
- 保持模型尽可能简单
- 将你的结论与因果关系和相关性进行对比
- 优化最有前途的指标
原文作者:Jan Zawadzki
翻译作者:Sophie Li
美工编辑:过儿
校对审稿:Dongdong
原文链接:https://towardsdatascience.com/top-5-mistakes-of-greenhorn-data-scientists-90fa26201d51





