
XGBoost VS LightGBM
前言

屠龙刀——XGBoost
XGBoost是由华盛顿大学(University of Washington)的陈天奇作为 Distributed (Deep) Machine Learning Community (DMLC) 组员所开发的一个研究项目。在陈天奇与队友一起赢得了Higgs Machine Learning Challenge后,许多的数据科学竞赛队伍使用XGBoost并获得了冠军,促进了该工具在数据科学应用中的广泛使用。
倚天剑——LightGBM
LightGBM是微软旗下的Distributed Machine Learning Toolkit (DMKT)的一个项目,由2014年首届阿里巴巴大数据竞赛获胜者之一柯国霖主持开发。虽然其开源时间才仅仅2个月,但是其快速高效的特点已经在数据科学竞赛中崭露头角。Allstate Claims Severity竞赛中的冠军解决方案里就使用了LightGBM,并对其大嘉赞赏。
屠龙刀VS倚天剑
其不同之处在于:XGBoost作为屠龙刀,刚劲有力,无坚不摧;LightGBM作为倚天剑,剑如飞风,唯快不破。
决策树算法
决策树生长策略
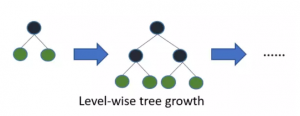
Figure 1 Level-wise生长策略
LightGBM采用leaf-wise生长策略,如Figure 2所示,每次从当前所有叶子中找到分裂增益最大(一般也是数据量最大)的一个叶子,然后分裂,如此循环;但会生长出比较深的决策树,产生过拟合。
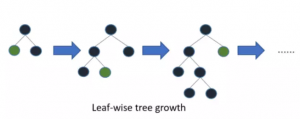
Figure 2Leaf-wise生长策略
网络通信优化
Allstate Claims Severity竞赛实践对比
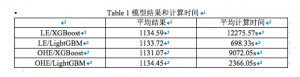
同时,参考Allstate Claims Severity竞赛中的冠军解决方案,XGBoost的单个模型最佳LeaderBoard得分为1105,而LightGBM的单个模型最佳LeaderBoard得分为1111。XGBoost的模型准确性方面仍然高于LightGBM。





