
关于P与0.05的爱恨情仇
假设检验有时候让人非常困惑。因为用来描述检验结果的语言非常累赘,同时准确地解释 p-value 的含义也非常考验人的逻辑。在假设检验中,我们应该如何设置一个标准,来确定我们的结果是显著的呢?这个标准是否符合实际?
在这篇文章中,我们将使用Northwind 数据库中的数据来完成统计假设检验。我们要解决的问题是:
打折是否对销量有显著的提升效果?如果是的,在折扣为多少是时,我们能观察到统计显著性?

这个数据库包含了一个专门经营特色食品的公司的销售数据。数据库中包含的数据表在下面的实体关系图中。
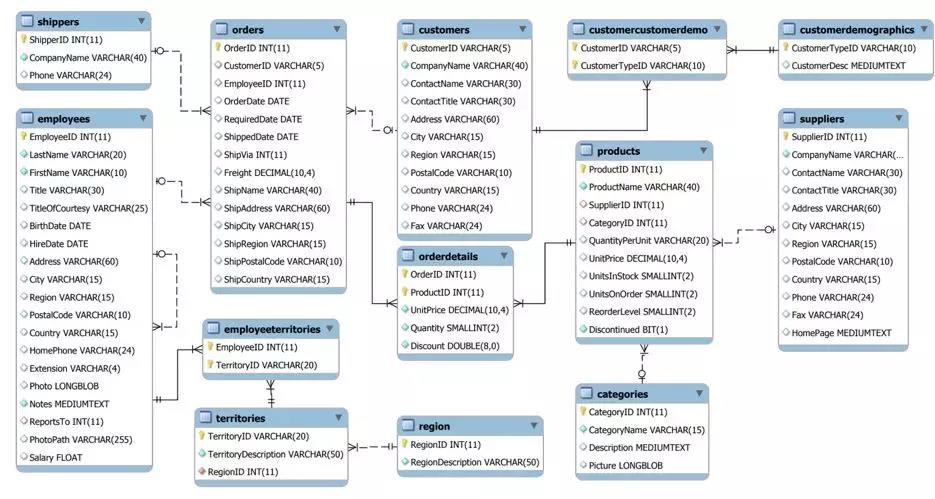
我们需要的数据是:产品的订单数量和折扣力度,来解决我们的问题。我们通过SQL抽取数据,并将数据保存在数据框架中。

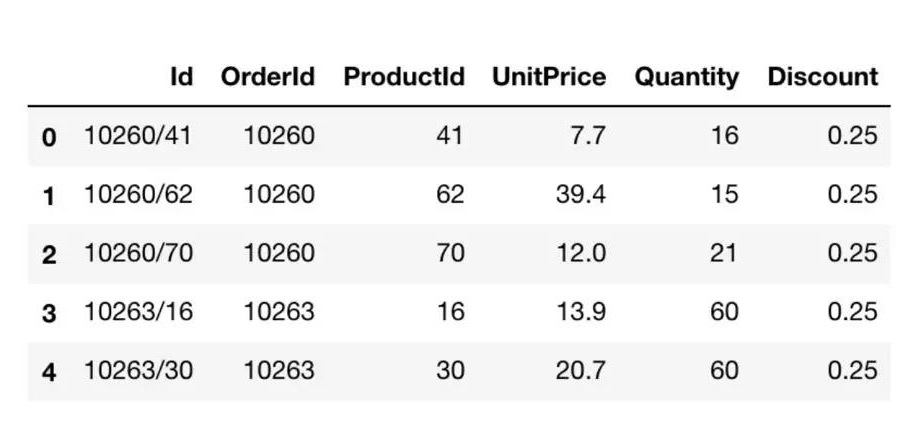

在进行统计测试之前,我们需要考虑实验设计。我们研究的问题是,折扣力度是否对订单数量有统计显著效果。这意味着我们需要将数据分成两组来对比他们的区别。这两组数据分别叫做控制组和实验组。
控制组的顾客不会享受折扣优惠
实验组的顾客会享受到折扣优惠

为了让测试结果有信度,我们需要做出下列假设:
1. 正态性
人口数据一般都符合正态分布。我们可以通过正太测试来从视图上检验这个假设。只需要使用normaltest 函数就可以做到。

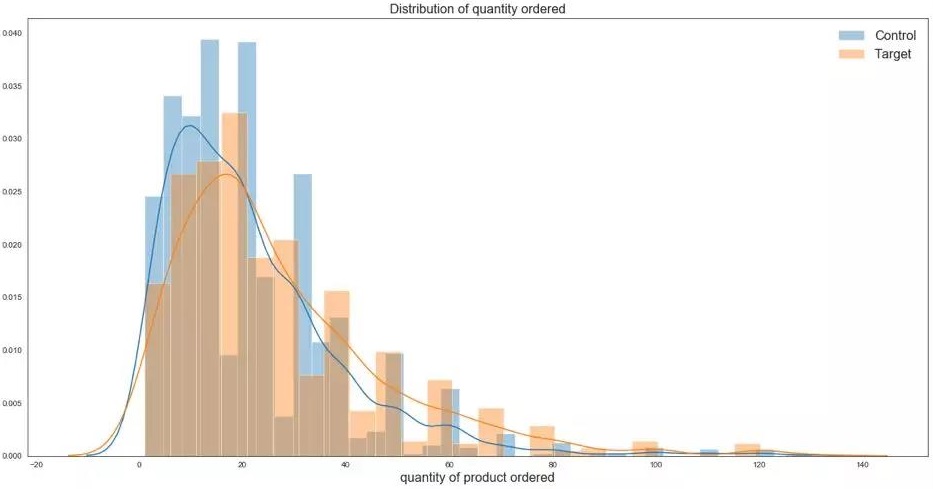
Normaltest 函数通过偏度和峰度来验证正态分布。我们的零假设是这组数据符合正态分布。这个函数会输出一个p-value 帮助我们做出统计决定。在这种情况下,我们根据 p-value 得出为零假设不能很好地解释观测到的数据,因此这组数据不符合正态分布。
但是,不用担心!我们可以通过中心极限定理(Central Limit Theorem)来进行参数估计和假设检验。中心极限定理简单来说就是在样本数量足够多的情况下,无论数据本身是什么分布,来自这组样本的数据平均值都会近似于正态分布。样本需要的大小取决于分布的偏度,但一般来说,样本数量必须要大于30。
2. 独立性
另一个假设是独立性,代表一个顾客的下单数量并不会影响下一位顾客的下单数量。我们认为顾客下单的行为是单独且独立的。
3. 随机性
最后数据样本必须是随机选择的。这很重要,因为在实验设计中我们要尽量避免引入偏见。为了保证随机性,我们会使用 random.choice 这个函数来产生随机样本。

下一步就是创建能用来假设检验的样本平均值的抽样分布。我们需要创建一个函数并重复这个函数1,000次来明确分布的范围参数。就像之前提到的,一个足够大的样本会近似于正态分布,所以我们用一个样本数量为500的样本来满足正态性的假设。

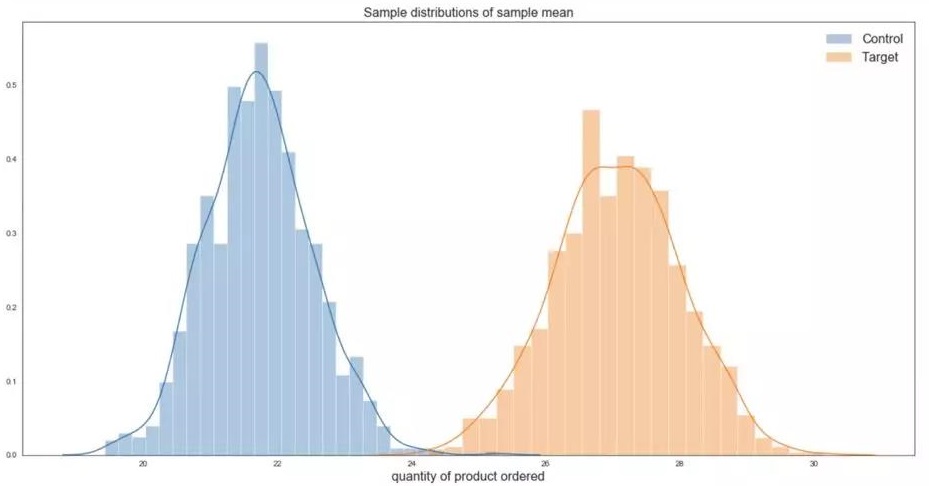

因为有两个组的数据,我们要通过两个样本的 t-test 来对比两组独立的平均数。零假设H。是假设一个参数值为真,除非我们能证伪的。备则假设 Ha 是对这个参数剩下可能的范围作出的假设。我们要做的是右侧检验,因为我们假设参数值会大于某一个特定数值。
假设
H。:无论顾客是否享受折扣,订单数量的平均值都没有区别。
Ha :折扣期间,平均订单数量应该比非折扣期间多21.7。
显著水平和统计功效
我们将特定程度的显著水平称为alpha (α),用来对零假设作出决定。α 代表了当零假设为真我们却拒绝了它的概率。α 是出现第一类错误的概率。根据历史传统,α的值一般是0.05。还有第二类错误,即当我们接受H。而其为假时的概率。这个概率用β值表示。
通常Type I 错误是更加严重的错误,因为我们想要找到零假设为假的证据,所以我们想要让 α 更小一些。
第一类错误:当折扣没有效果时,接受“折扣有效果”这个假设。(这可能导致我们持续提供优惠折扣,却对销售数量毫无影响,最终导致应得利润丢失)
第二类错误:当折扣有效果时,拒绝“折扣有效果”这个假设。(当折扣有效果时,不提供折扣给顾客,导致没能抓住潜在利润)
我们可以看出第一类错误更加令人难以容忍,因为这回导致公司丢失利润做着没有意义的活动。
这时我们要讲到统计功效这个概念了。统计功效是正确地拒绝一个错误的零假设的概率,它的大小由1-β 表示。在这里我们注意到 α 和 β 有一个相反关系。减小 α则会增大 β, 反之亦然。为了减小这两个几率,我们需要增大样本数量,因此我们选择了一个数量为 500 的样本。在实验设计时,及早识别这些错误可以帮助我们有效避免陷阱,我就做得很好。
p-value
最后我们要说的一个概念就是 p-value。P-value 是假设零假设为真时,观察到更为极端情况的概率。也就是说,如果 p < α,就表示零假设不符合数据观察结果,因此我们要拒绝它。
Welch’s t检验
我们可以对这两个样本进行学生t检验或者Welch t 检验。这两者的区别在于,前者假设了两个样本的总体方差是相通的,而后者没有。在样本方差不同时,Welch t 检验被认为更可靠。鉴于我们使用的数据方差不同,我们决定使用 ttest_ind 函数来进行 Welch t 检验。


我们得出了检验统计量为136,p-value为0。 因为检验得到的是双侧的p-value,因此我们将这个值除以2,来得到单侧的p值。在这里,单侧p-value也是0。0 < 0.05 ( p < α),我们拒绝零假设。我们可以说,在5%的显著水平下,有折扣优惠时顾客平均订单量比没有优惠的控制组平均订单量高21.7。

当我们说统计差异存在时,我们需要进一步明确差异程度,这就是我们要说的效应量了。效应量不受样本数量的影响。这也是我们要计算效应量的原因。当样本数量很大时,我们可能观察到效应量很低但却很显著的结果。我们通常用 Cohen’s d 来计算效应量。当这个值介于0-0.2之间时,我们认为效果很小或不存在。当这个值大于0.8时,我们认为效果很明显。

通过计算我们得出了上图的数值,我们可以认为优惠力度对订单数量有统计显著效果。

我们知道折扣力度会产生一个效果,但在折扣力度为多少时,我们会观察到统计显著效果呢?95折的效果和8折的效果会有什么不同吗?这时我们需要做一个单项方差分析,来检验不同折扣力度时的显著差异。

H。认为不同折扣力度的组之间没有差异,Ha 认为至少有一组的平均值会明显区别于其他组。这个模型产生p值为(4.7e-09)< α, 所以我们拒绝了零假设。但此时,我们仍然不知道什么程度的折扣会产生较为显著的效果。为了确定折扣数值,我们对所有可能的两组平均值进行了多重比较分析。
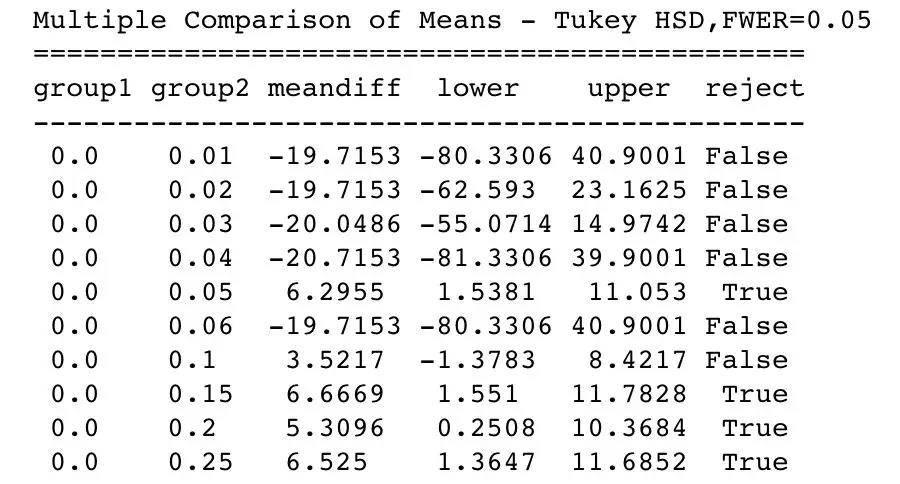
我们得出了我们项目所研究问题的答案:
当折扣力度为95折,85折,8折和75折时,会对订单平均量产生较为显著的统计效果。

让我们来看看我们还能用假设检验解决哪些问题?
1. 不同的供应区域是否会对商品单价产生统计显著效果?
H。 不同供应区域的商品单价没有差异。
Ha 至少有一个供应区域有不同的商品单价。
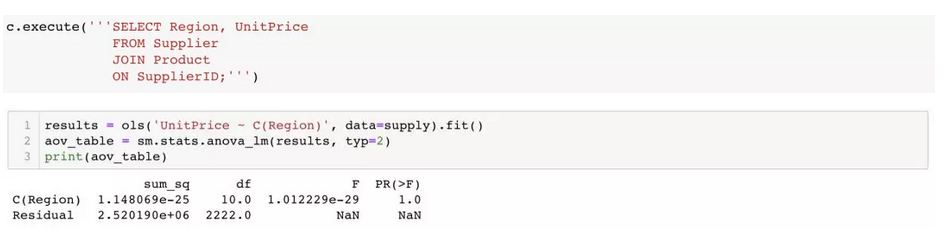
整个模型并没有产生显著效果,因为为 p (1.0) > α。也就是说我们不能拒绝零假设。研究这个问题的主要目的是想知道,公司是否可以通过选择单价比较便宜的供应区域来减少成本。然而结果显示了不同供应区域之间的单价并没有显著差异。
2. 选择Federal 或是 Speedy Express 是否会对商品平均运费产生显著影响?
H。 两家公司对平均运费不产生影响。
Ha 两家公司对平均运费产生影响。
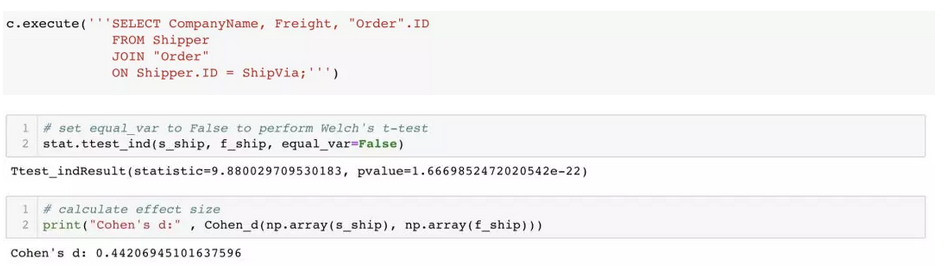
这里p (1.6e -22) < α, 所以我们拒绝零假设,并认为这两家公司会对商品平均运费产生显著影响。经过计算,效应量为中等 (0.2-0.5),我们仍可认为其中一家公司会比另一家公司运费更低。这个研究问题的目的是为了通过选择一家运费成本更低的公司。
3. 来自东欧的顾客的单笔订单购买商品的数量相比其他区域是否有统计显著效果?
H。单笔订单购买商品的平均数量是23.8。
Ha 东欧顾客单笔订单购买的商品数量少于23.8
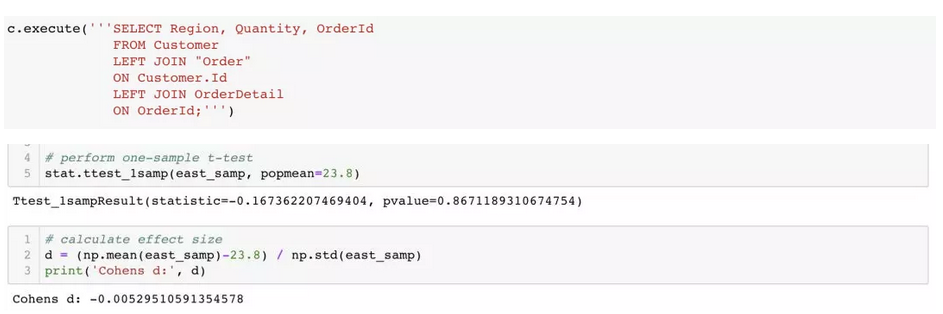
P (0.86) > α,因此我们不能拒绝零假设,也不能认为东欧顾客单笔订单购买数量比较少。Cohen’s d 也表明效果量几乎不存在。有一个比较有趣的发现是,西欧的顾客总订单量是60,340 而东欧是 2,155,如果我们发现东欧顾客的单笔订单购买数量比较少,这说明东欧市场很有潜力。然而我们分析的结果证明,东欧顾客单笔订单数量并不比西欧少。
原文作者:Steven Liu
翻译作者:喝豆奶的Narcia
美工编辑:喝豆奶的Narcia
校对审稿:卡里
原文链接:https://towardsdatascience.com/hypothesis-testing-how-to-determine-significance-ce3991c5db53





