
分析数据库:点亮数据科学智慧人生
本篇文章要讲的是数据科学家最重要的技能,因此,请先容许我说别的技能都不重要^_^
运用一个 Python 或 R 算法非常简单。我们都知道,只要稍微修改或添加两行代码,我们就能将这些算法变成线性回归模型,神经网络模型,分类器,或者其他一些 Fancy 的模型。
定义超参数(Hyperparameters)也不是难事儿,只要会交互效度分析和格点搜索就能轻松搞定。试运行模型可能需要考验点耐性,要经过许多次试验和纠错,才能够最终上传一个每分钟可以处理上百万个请求的模型。这些技能似乎都不是最难的。
那什么才是数据科学家最应该掌握的技能呢?简洁版的答案是:

交易数据库(Transactional databases),即储存在订单、支付订单、访问日志等这些交易数据的数据库,主要来源于软件。这些数据并不适合直接用来做数据科学分析。制定这种数据库结构的开发者,他们的目的是创建出运行更好的软件或平台,因此,可能并没有考虑到这些数据将如何用于分析。
用交易数据创建一个机器学习模型并没有什么意义,除非你想要做的是预测交易。一个数据科学家需要的是通过整理和分析这些交易数据,建立自己的分析数据库。所以什么是分析数据库呢?它和交易数据库有什么不同呢?

分析数据库(Analytical database)是用于特定分析目的的数据库。比如,用于分析客户流失的数据库和用于分析购物车商品推荐的数据库是不同的,虽然这两个数据集的来源可能都是交易数据库。想要分析客户流失,就需要将客户的行为数据进行分组,从而观察特定客户在一段时间内的行为。想要分析购物车推荐,数据需要根据购物车里的商品关联性而进行分组。
知道如何创建分析数据库是数据科学家需要培养的一个重要技能。这一技能几乎没有在学校的课程里或公共网课里被提到。为了将交易数据库转化成分析数据库,我们需要了解我们所在的行业。对于行业的了解加上批判性的思维构建了我们分析问题的框架基础。
数据科学家通常需要目标来训练他/他的模型。如果你浏览了Kaggle的竞赛项目,你会发现很目标在训练和评估之前就已经被定义了。然而,一个交易数据库通常没有能够使用的目标。数据科学家需要首先定义什么时候顾客才会抛弃这个公司的服务,然后才能创建客户流失模型。需要先定义什么是不良的支付行为,才能预测客户的欠款行为。目标有时候不是一眼就能看出来的,它需要一个很长的观察和研究的过程,但这可能是你的经理所不能容忍的。

试想我们现在有一个数据库,我们要根据客户行为档案对现有的客户进行分类。客户行为档案里包含对这一类客户的特征描述。现在我们作为分析师,需要观察和记录客户的行为,将这些行为与客户档案中描述的行为特征对应,然后对客户进行分类。但是在这里,我们会遇到一些潜在的问题:
● 在观察客户行为时,不同的分析师会对客户行为有着不同的判断。因此,可能将同一个客户分到不同的类别。
● 分析师们真的准确理解了每个行为档案所描述的特征吗?我们有明确的标准能够把客户分到x类别而不是y类别吗?
● 在数据采集阶段,是否还有新的变动?比如产生一个新的行为档案/类别?那么我们定义目标时,是否应该将这部分变动列入考虑呢?
● 分析师是否选择了最合适的类别?是否每次都会将这些档案重新洗牌,使得分析师能不总是看到同一个第一选择,从而受到先入为主的影响?
● 经理需要这个分类非常准确吗?有时候客户分类可能只是为了整理客户信息。当客户档案总是按照相同的内容和顺序交到分析师手上时,我们就不禁要怀疑客户分类只是日常整理而不是分析工作了。
思考这些潜在问题之后,我们可能会发现,到现在为止,我们收集的数据一无是处。因为这些数据并没有根据固定标准和流程进行采集。

试想我们在金融行业工作,此时,我们面临着如下问题:
我们需要建立一个模型来识别那些在近段时间内不会偿还他们的信用卡欠款的客户。
为了解决这个问题,我们需要创建描述客户支付行为的变量。接下来我们很可能需要创建一个回归模型,来对信誉“好”的信用卡用户和“坏”的信用卡用户进行区分。最后我们需要计算一个客户是“好”或“坏”的几率。

我们可能很难找到一个现存的变量来描述客户的“好”“坏”。首先,我们需要定义什么是“好客户”和“坏客户”。为此,我们需要引入逾期支付。我们可能会发现,平均来说,客户的支付会有20天的逾期,但是75%的欠款都在截止日期后的17天里被付清了。
我们可以设计一个累积分布的逾期支付天数。我们发现,在截止日期30天后,87%的客户都还清了欠款。6个月后,90%的客户还清了欠款。我们可以用贝叶斯推理来预测客户在30天付清欠款的几率。看👇

我们可以总结的是,如果一个顾客超过 30 天还没有支付欠款,那么他在近期还清欠款的可能性非常低(23%)。要定义一个顾客是“好”还是“坏”,我们还需要深度了解金融行业和银行的运行,才能有充分的背景知识作为依据,才能将30天内未支付欠款的客户判定为“坏”客户,而在30天内付款了的客户判定为“好”客户。

我们想要通过顾客在过去一段时间内的行为,来预测顾客在将来一定时间内还清欠款的几率。选择时间范围更偏向于商业决策而不是统计决策。需要注意的是,这个时间范围要足够容纳一个客户观察周期。时间窗口太短会导致观察结果有所偏差,从而导致模型不准确。
定义:基于客户过去12个月内的行为,我想预测客户是在未来六个月里是一个“好”客户(截止日期后30天内还清付款)的几率。
为了完善这个定义,我们需要:
● 确定一个观察时间点,这个时间要比现在至少早6个月。
● 确定一个观察时间范围,比观察时间点早12个月。
● 确定表现窗口,从观察时间开始后的6个月。
● 定义好客户(根据上述定义)
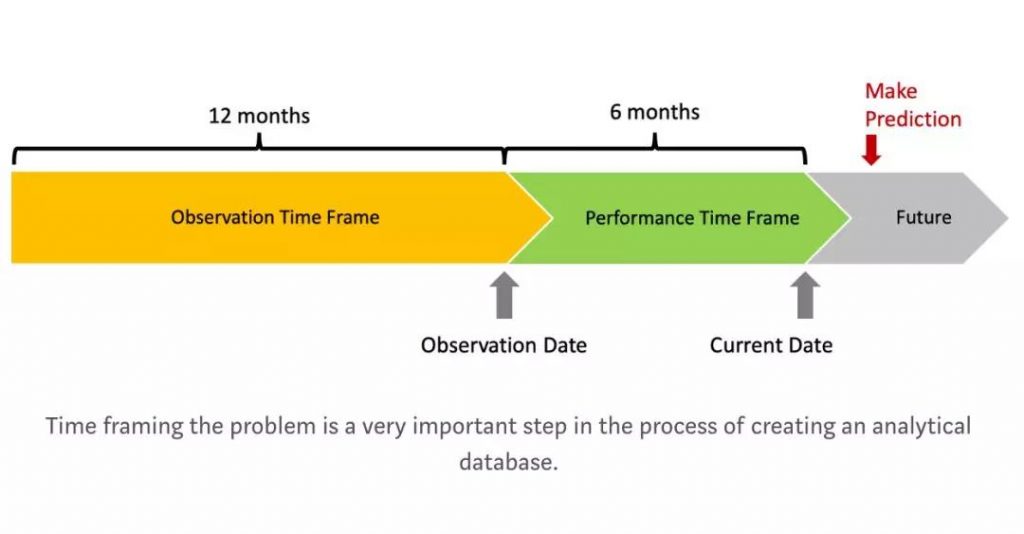
同时,需要注意上述定义有一些隐含的意义:
● 你至少需要18个月的数据
● 你的预测可以根据时间范围的变化而改变。当你输入不同时间范围的数据到这个模型中,它都会给出该时间范围之后六个月的欠款偿清几率。
● 观察时间点和时间范围都是你创造分析数据集特征的依据之一。

我们已经定义了我们的目标,观察时间点, 和表现窗口,现在我们需要创建数据库的目标了。我们需要计算在表现窗口内客户最晚逾期还款的天数,并根据以下👇规则创建GOOD_PAYER 的变量:

所以,在表现窗口内,如果顾客逾期30天未偿还欠款,他/她可能会被判定为“坏”顾客,尽管债务在30天后被支付了。我们用 0 表示“坏”客户,1表示“好”客户,这样分数越高,逾期欠款的几率就越低。

现在我们需要商业知识来做一些排除:
● 排除那些在观察时间点没有欠款上限的客户
● 排除那些在观察时间点已经有30天以上为偿还欠款的客户,因为他们已经是坏客户了
● 排除那些从未使用过信用卡的客户(仅欠引用卡管理费用)

在这个案例中,我们需要将客户进行分类,并创建变量。每个变量都应该描述了一类客户在观察时间范围内的行为。下面是一些可以参考的例子:
STATE: 个人信息特征 — 表示顾客居住的省/州
AGE: 个人信息特征 –表示客户的年龄,按照观察时间点时的年龄纪录
GENDER:个人信息特征 – 表示客户的性别
MOB: 成为该银行客户的月份数 – 客户从注册成为用户到观察时间点的月数
AVG_LIMIT: 在12个月观察期月平均信用卡消费数额占可适用额度的百分比
MAX_LIMIT: 在12个月观察期内最大消费额占信用卡可使用总额的百分比
PURCHASE_TOTAL: 12个月观察期内总消费数额
DPD_OP: 超过截止日期还款的天数
MAX_DPD: 12个月观察期内的最晚逾期还款天数,如果每次都提前偿还,可能是负数
AVG_DPD: 12个月观察期内还款平均逾期天数。如果提前还款可能是负数。
BEFORE_DUE_QTY: 12个月观察期内提前还款的次数。
GOOD_PAYER: 目标 – 表示顾客在6个的表现窗口里没有超过30天未还款的情况。

最后,我们终于可以开始建模了!我们可开始运用在数据科学里学到的所有内容。你的分析数据集已经设计好可以使用了。最简单的解决方案就是运用一个逻辑回归,通过上述变量来预测GOOD-PAYER这个目标。模型会根据每个客户的数据返回一个0到1之间的数据,表示这个客户是好客户的几率。
注意要正确解读分析的结果:最后的分数表示了一个客户在未来6个月里不会超过30天不偿还欠款的几率。
原文作者:Andre Sionek
翻译作者:喝豆奶的Narcia
美工编辑:喝豆奶的Narcia
校对审稿:卡里
原文链接:https://towardsdatascience.com/what-is-the-key-skill-that-the-best-data-scientists-have-655edea228ac





