
数据科学家必备:Git操作指南
为什么选择Git作为你的数据科学项目?
Git是一个广泛用于软件开发的版本控制系统,但它是你的数据科学项目的正确选择吗?绝对的。
以下是为什么Git对于数据科学是无价的一些原因。如果你想了解更多关于数据科学的相关内容,可以阅读以下这些文章:
从优秀到卓越:数据科学家的Python技能进化之路
ChatGPT的代码解释器将永远改变数据科学
每个数据科学家都应该避免的十大统计错误
每个数据科学家都应该知道的12个Python特性!
版本控制
场景:
用一种新的方法代替当前的数据处理技术,在意识到新方法不能产生期望的结果之后,你希望恢复到以前的工作版本。
不幸的是,如果没有版本控制,撤销多个更改将成为一项艰巨的任务。
解决方案:
使用Git,你可以跟踪对代码库的更改,在不同版本之间切换,比较更改,并在必要时回滚到稳定状态。
协作
场景:
你在机器学习项目上与其他数据科学家合作。要合并团队成员所做的所有更改,你需要手动交换文件并检查彼此的代码,这需要花费时间和精力。
解决方案:
Git可以很容易地合并变更、解决冲突和同步进度,使你和你的团队成员能够更有效地一起工作。

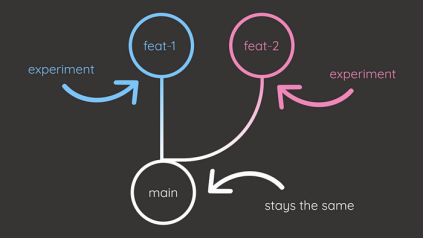
分支
场景:
你希望探索新的方法来增强模型的性能,但是对于是否直接对生产代码进行更改犹豫不决。对已部署模型的任何意外影响都可能对你的公司造成严重后果。
解决方案:
使用Git的分支,你可以为不同的特性创建单独的分支。这允许你在不影响生产分支稳定性的情况下进行测试和迭代。
备份
硬件故障或盗窃会导致丢失所有代码,使你遭受重创,并使你的工作倒退数月。
解决方案:
Git通过将项目安全地存储在远程存储库中来备份它们。因此,即使遇到这样的不幸事件,你也可以从远程存储库恢复代码库并继续工作,而不会丢失重要的进展。

如何使用Git
既然我们已经理解了Git在数据科学项目中的价值,那么让我们探索一下如何在不同的场景中有效地使用它。
初始化Git
要在当前项目中初始化Git并将项目上传到远程存储库,请遵循以下步骤:
首先,在项目目录中初始化一个新的Git存储库:
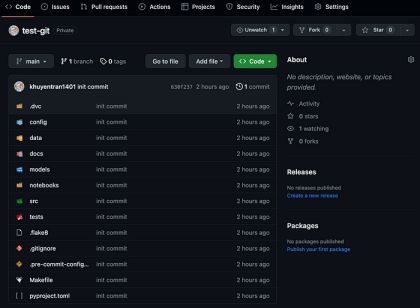
git init接下来,向本地Git存储库添加一个远程存储库。要使用GitHub作为远程存储库,请在GitHub上创建一个新的存储库并复制其URL。
然后,将URL添加到本地Git存储库中,名称为“origin”:
git remote add origin <repository URL>接下来,在Git存储库中进行阶段更改或添加新文件:
# Add all changes in the current directory
git add .审核要提交的变更清单:
git status
Changes to be committed:
(use "git rm --cached..." to unstage)
new file: .dvc/.gitignore
new file: .dvc/config
new file: .flake8
new file: .gitignore
new file: .pre-commit-config.yaml
new file: Makefile
new file: config/main.yaml
new file: config/model/model1.yaml
new file: config/model/model2.yaml
new file: config/process/process1.yaml
new file: config/process/process2.yaml
new file: data/final/.gitkeep
new file: data/processed/.gitkeep
new file: data/raw.dvc
new file: data/raw/.gitkeep
new file: docs/.gitkeep
new file: models/.gitkeep
new file: notebooks/.gitkeep
new file: pyproject.toml
new file: src/__init__.py
new file: src/process.py
new file: src/train_model.py
new file: tests/__init__.py
new file: tests/test_process.py
new file: tests/test_train_model.py在存储库的历史记录中永久保存阶段性更改,并附上提交消息:
Git commit -m 'init commit'一旦提交完成并存储在本地存储库中,就可以通过将更改推送到远程存储库与他人共享更改。
# push to the "main" branch on the "origin" repository
git push origin main运行此命令后,远程存储库上的“main”分支将接收来自本地存储库的最新更改。
为现有项目做出贡献
要对现有项目做出贡献,首先在本地机器上创建远程Git存储库的本地副本:
git clone <repository URL>该命令将创建一个与远程存储库同名的新存储库。要访问这些文件,请导航到存储库目录:
cd <repository-name>在单独的分支上而不是在“main”分支上进行更改是一种很好的做法,以避免对主代码库产生任何影响。
创建并切换到一个新的分支使用:
git checkout -b <branch-name>对新分支做一些修改,然后添加,提交,并将这些修改推送到远程Git存储库上的新分支:
git add .
git commit -m 'print finish in process_data'
git push origin推送提交后,你可以创建一个pull请求,将更改合并到“main”分支中。
在你的同事批准并合并你的pull请求之后,你的代码将被集成到“main”分支中。
合并本地更改和远程更改
假设你已经从主分支创建了一个名为“feature -2”的分支。在对“feature -2”分支进行了几次更改之后,你发现主分支已经更新。如何将主分支中的远程更改合并到本地分支中?

首先,确保通过分段和提交本地更改来保存本地工作。
git add .
git commit -m 'commit-2'这可以防止远程更改覆盖你的工作。
接下来,使用git pull从远程存储库的主分支中拉出更改。第一次执行该命令时,系统将提示你选择一种策略来协调分支。以下是可用的选项:
$ git pull origin main
From https://github.com/khuyentran1401/test-git
* branch main -> FETCH_HEAD
hint: You have divergent branches and need to specify how to reconcile them.
hint: You can do so by running one of the following commands sometime before
hint: your next pull:
hint:
hint: git config pull.rebase false # merge
hint: git config pull.rebase true # rebase
hint: git config pull.ff only # fast-forward only
hint:
hint: You can replace "git config" with "git config --global" to set a default
hint: preference for all repositories. You can also pass --rebase, --no-rebase,
hint: or --ff-only on the command line to override the configured default per
hint: invocation.
fatal: Need to specify how to reconcile divergent branches.运行git pull origin main——no-rebase将在“feature -2”分支中创建一个新的合并提交,将“main”分支和“feature -2”分支的历史记录联系在一起。
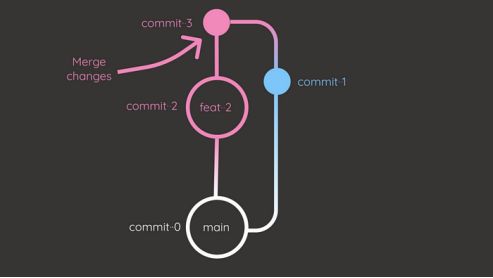
运行git pull origin main——rebase将执行一个rebase操作,这将把来自“feature -2”分支的提交放在“main”分支的顶部。

Rebase不像merge那样创建新的合并提交,相反,它修改“feature -2”分支的现有提交。这将产生更清晰的提交历史记录。
但是,rebase命令应该谨慎使用,特别是当其他团队成员正在积极使用相同的分支时,例如“feature -2”分支。
如果在其他人也在修改“feature -2”分支的时候对其进行了修改,则可能导致分支历史记录中的不一致。Git在尝试同步这些分支时可能会遇到困难。
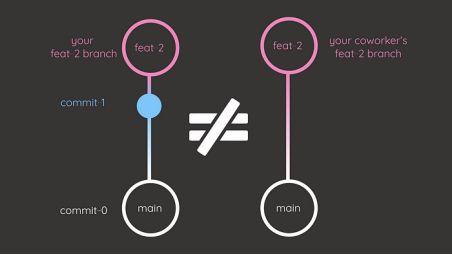
如果你是Git的新手,并且优先考虑简洁性而不是维护干净的历史记录,请使用合并方法作为默认选项,因为与rebase相比,合并方法通常更容易理解和使用。
恢复到之前的提交
想象一下:在创建了新的提交之后,你意识到在这些提交中出现了错误,并希望恢复到特定的提交。你是怎么做到的?
首先,通过运行以下命令来确定要恢复的特定提交的提交哈希值:
git log
commit 0b9bee172936b45c3007b6bf6fa387ac51bdeb8c
commit-2
commit 992601c3fb66bf1a39cec566bb88a832305d705f
commit-1假设你想恢复到“commit-1”,你可以使用git revert或者git reset。
Git revert创建一个新的提交,撤销指定提交之后所做的更改。
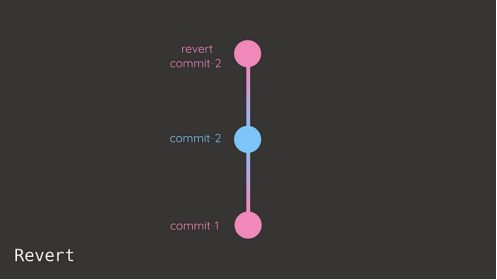
Git reset通过将分支指针更改为指定的提交来修改提交历史。
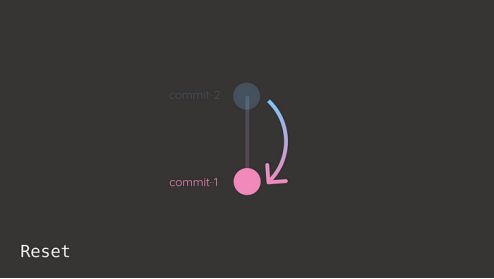
虽然git reset保持提交历史干净,但它更具破坏性,因为它会丢弃提交。Git revert是一个更安全的选择,因为它保持原始提交的完整性。
良好的实践
忽略大文件和私有文件
在Git存储库中,必须将特定的文件或目录从版本控制中排除,以解决诸如文件存储空间和隐私问题之类的问题。
在数据科学项目中,由于以下原因,你应该忽略某些文件,例如datasets和secrets:
- datasets:对二进制数据集进行版本控制可以显著增加存储库的大小
- Secrets:数据科学项目通常需要凭据或API密钥来访问外部服务。如果存储库被破坏或被公开共享,在代码库中包含这些秘密可能会带来安全风险
要排除特定的文件或目录,可以将它们添加到项目根目录中的.gitignore文件中。下面是一些例子:
# .gitignore
data/
.env此外,你应该忽略可能导致大文件存储空间或特定于你的开发环境的非必要文件,例如依赖管理文件,如“venv”或编辑器特定文件,如“.vscode”。
在这里找到适合你的语言的有用.gitignore模板列表:https://github.com/github/gitignore
做小的提交
将你的更改分解为小的、集中的提交。这种方法确保每次提交都有一个明确的目的,使其更容易理解,在需要时恢复更改,并最大限度地减少冲突的可能性。
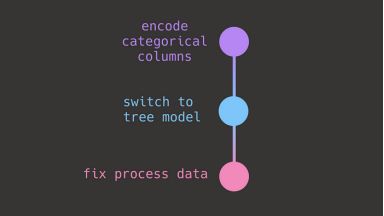
有一个描述性的分支名称
选择能够准确反映你正在处理的任务或特性的描述性分支名称。避免使用像“add file”这样模糊的名字或像“john-branch”这样的个人标识符。相反,应该选择更具描述性的名称,如“将线性模型更改为树模型”或“编码-分类-列”。
标准化代码格式,便于代码审查
一致的代码格式有助于审查者关注代码的逻辑,而不是格式不一致。
在下面的示例代码片段中,检查人员很难确定由于不规则缩进、空格和引号而添加的print语句。
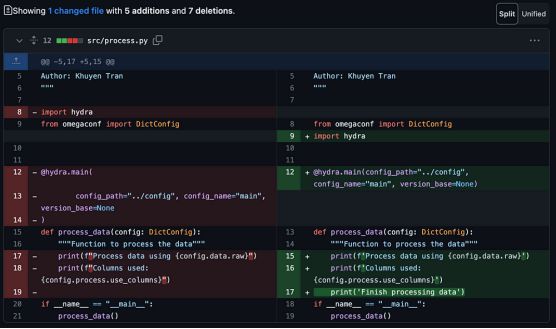
标准化代码可以提高代码的可读性。
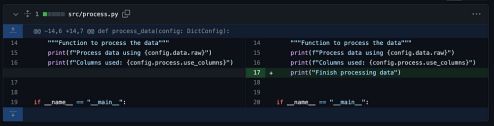
我最喜欢的格式化和标准化代码的工具是:
- Ruff:一个非常快的Python检查器,用Rust编写
- black:Python代码格式化器,自动重新格式化你的代码
补充Git的工具
pre-commit(预提交)
在每次提交之前,根据风格指南维护一致的代码风格可能会让人不知所措。通过在提交之前检查和重新格式化代码,预提交自动化了这个过程。下面是它如何工作的一个例子:
$ git commit -m 'my commit'
ruff.......................................Failed
- hook id: ruff
- exit code: 1
Found 3 errors (3 fixed, 0 remaining).
black....................................Failed
- hook id: black
- files were modified by this hook
reformatted src/process.py
All done! ✨
1 file reformatted.DVC
DVC(数据版本控制)是一个数据版本控制系统。它本质上类似于Git,但用于数据。DVC允许你将原始数据存储在单独的位置,同时在Git中跟踪不同版本的数据。

结论
通过采用Git并利用它的特性以及这些补充工具,你可以提高生产力,维护代码质量,并有效地与团队成员协作。
感谢阅读。你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
参考:
Atlassian. (n.d.). Merging vs. rebasing:Atlassian Git Tutorial. Atlassian. https://www.atlassian.com/git/tutorials/merging-vs-rebasing
原文作者:Khuyen Tran
翻译作者:过儿
美工编辑:过儿
校对审稿:Chuang
原文链接:https://towardsdatascience.com/git-deep-dive-for-data-scientists-1c9cc45c7612



