揭秘——数据科学将如何应用在元宇宙.jpg "Meta的新LLaMa AI模型是给世界的礼物!")
Meta的新LLaMa AI模型是给世界的礼物!
近几个月最大的新闻是,Meta推出了其世界著名的LLM的第二个版本LLaMa,并在此过程中发布了其第一个聊天机器人LLaMa-2 – chat,这是Meta对ChatGPT发起的第一个真正的威胁。如果你想了解更多关于人工智能的相关内容,可以阅读以下这些文章:
如何一眼识别人工智能生成的图像!
一个新的人工智能野兽苏醒了!
生成式人工智能的真正赢家!
人工智能危险吗?哪些工作面临风险?
但这并不是普通的“看看我们的新LLM有多酷”类型的发布,实际上Meta试图永久改变AI的叙事方式。
事实上,我想说这次发布确实可以永久地改变AI,并开启一个AI访问和知识最终实现民主化的时代。
LLaMa的胜利也是你的胜利,你将会明白为什么。
最新的开源技术
首先,在阅读了70多页的论文后,LLaMa 2的出色之处显而易见。
优化以实现卓越
Meta创建了四个模型,分别是7,13,34和700亿参数模型。
尽管后者相当大,但它们都比GPT-4小了几个数量级(据推测,GPT-4是一组多达82200亿个参数模型,交织在一起,总共约有一万亿参数),比GPT-3小了两倍多。
事实上,这个模型并没有从它的第一个版本发展起来,它已经是一个65B参数模型。
那么为什么它变得更好了呢?
很简单,Meta的方法很明确:因为他们将专注于提供开源模型,所以他们的优化目标不是大小,而是数据。
也就是说,他们用比原来大40%的数据集和更长的时间来训练LLaMa,同时还将其上下文窗口增加了一倍,达到4k个标记(大约3000个单词)。
在质量方面,如下图所示,LLaMa 2-Chat 700亿参数模型基本上击败了它的所有竞争对手,尽管体积小得多,但比ChatGPT(3.5版)略好一些。
与其他开源模型相比,它无疑优于所有开源模型。
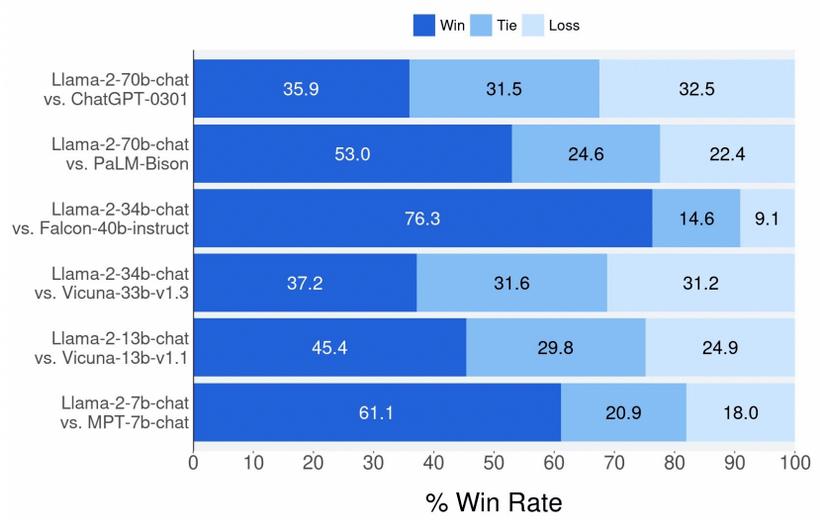
当然,它仍然不如GPT-4(图中没有显示),但我们谈论的是一个可以轻松放大12-15倍的模型,所以这并不奇怪。
但这项研究的主要亮点不是这个模型有多好,而是他们在解释模型训练过程中投入了多少细节。
而这一点正是LLM发展中的一个重要里程碑。
构建智能
Meta做的第一件“不同”的事情是分别优化了有用性和无害性,创建了目前可能最安全的高性能聊天机器人。
为此,让我们回顾一下Meta自己绘制的构建LLaMa-2-Chat所需的完整过程图。
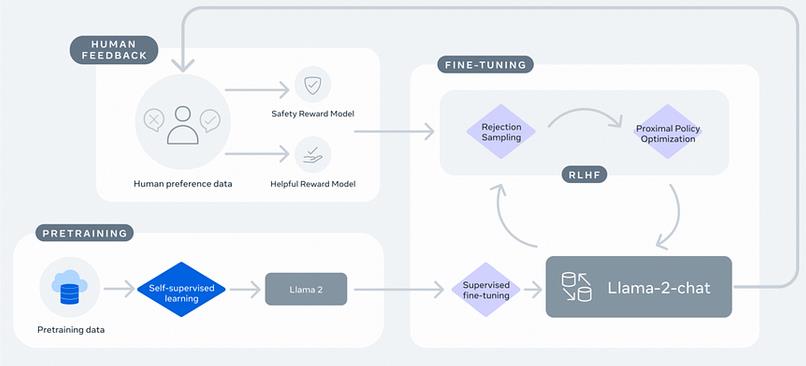
训练GenAI聊天机器人包括四个步骤:
- 首先,我们通过优化基础模型来训练它,以自我监督的方式预测文本序列中的下一个标记。也就是说,你屏蔽序列中的下一个单词,并要求模型对其进行预测。
- 这个预训练模型使用一个经过精选的数据集{提示,期望答案}进行微调。该模型被OpenAI称为“行为克隆”,可以学习以期望的方式行为。这是LLaMa-2-Chat的第一个版本。
- 接下来,我们希望根据人类偏好优化模型,同时减少有害反应的发生。使用步骤1中模型的副本,我们“切断”它的单词预测头,而不是预测序列中的下一个单词,根据人类的偏好输出一个标量值,表示对特定提示的响应有多好。这被称为奖励模型(RM)。简单地说,这种奖励模型在规模上就像人类一样。这意味着该模型经过训练,可以准确预测受过高等教育的人对给定提示的反应所给出的分数。
- 最后,我们针对该奖励模型训练LLaMa-2-Chat,目标是最大化奖励。换句话说,聊天机器人学会了根据提示写出能够产生最高价值的回复。
步骤3和步骤4是我们所说的从人类反馈中强化学习(RLFH),也是最终得到LLaMa-2-Chat模型的过程中的关键步骤。
但如果你熟悉LLM训练流程,你会发现图像中的某些内容看起来非常奇怪。
有用性与安全性的权衡
在标准的训练流程中,比如OpenAI用来构建ChatGPT的流程,他们只使用了一个奖励模型。
但在Meta的案例中,LLaMa-2-Chat是基于两种奖励模型构建的:
- 一个有用性奖励模式
- 一个安全性奖励模型
这在AI领域尚属首次,这样做的原因无非是有用与安全的权衡。
根据来自Anthropic的Claude模型背后的首席研究员Yuntao Bai领导的研究,优化一个既有用又安全的模型是很复杂的,因为它们有时会存在权衡。
如果你正在构建世界上最有用的模型,那么这个模型将准备好回答任何问题,无论要求的道德细微差别如何。
想要制造炸弹吗?方法在这。
想知道最简单的杀人方法吗?当然,为什么不呢?
因此,仅仅追求有用性,从字面上看,就是在制造一个定时炸弹。
另一方面,如果你想建立世界上最安全的模型,它要回答太多的问题将会非常复杂,因为当今世界上几乎任何事情都可以用道德正义的眼光来审视。
例如,Pi可能是我尝试过的最无害的聊天机器人,但当你想让它真正帮助你做事时,使用它真的很痛苦。
那么Meta做了什么?
简单地说,他们创建了两种奖励模型,并简单地使用动态成本函数对这两种模型进行优化。
为此,Meta团队注释了数据集中最有害的响应,当模型使用该响应进行训练时,与奖励分数相关的成本函数项从有用项切换到安全项。
通俗地说,如果训练样本非常有害,模型的目标是以“安全”的方式回答,而在其他情况下,它被训练为“以最有用的方式”回答。
技术说明:当我说针对某些事物进行优化时,我指的总是优化成本函数。为了训练一个神经网络,你需要定义一个可微的数学表达式来衡量模型预测的成本或误差,通过计算模型参数的梯度,你可以获得最小化成本的最佳组合,从而最大化预测精度。
通过这样做,该模型获得了如何最好地回答每个提示,同时考虑到不应回答的有害提示。
对于开源社区来说,这是一个明显的双赢,也是一个里程碑式的时刻,该社区可以获得关于如何执行这个被称为RLHF的“受到良好保护”的秘密的极其重要的信息。
但是,如果革命性的安全训练还不够,他们还引入了另一个新概念。
GAtt让你的模型记住一切
注意力是LLM的关键因素。
这是他们理解单词之间关系的方式,这种机制越好,模型就越好。
遗憾的是,文本序列越长,模型就越难记住序列的起始部分。
因此,如果你在第一次提示中要求模型“扮演拿破仑”,到第20次提示时,模型很可能会忘记这一指令。
在Ghost Attention(GAtt)中,他们对模型进行了微调,使其能够特别注意指令,并在整个对话过程中记住它们,这种情况发生了变化:
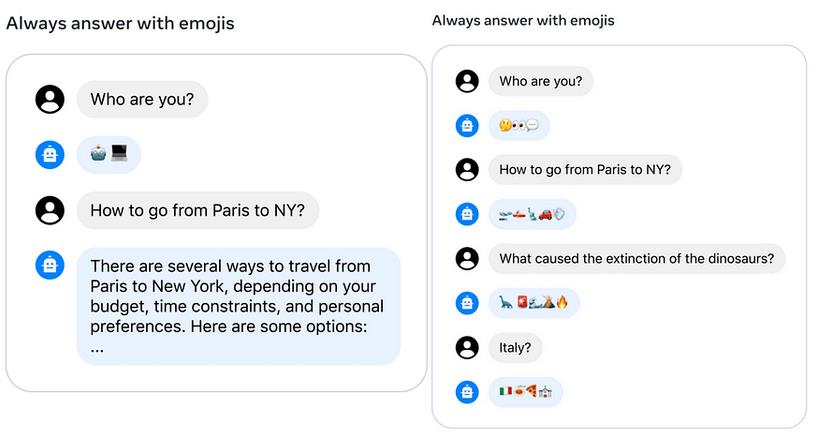
GAtt模型清楚地记得最初的指令,并在用户不一定要求的情况下继续提供表情符号的答案。
这是非常令人兴奋的,因为遵循指令是一个有用聊天机器人的基石,并且在整个对话中有效执行这些指令是大多数聊天机器人目前无法做到的。
GAtt将会继续存在。
OpenAI最近宣布了ChatGPT的“自定义指令”,这可以被认为是一个类似但更持久的功能。然而,在OpenAI的情况下,这可能只是一个UI/UX技巧,他们只是在每个提示下简单的添加了指令。
然而,其中最重要的公告是在几天后发布的。
跨越未跨越的桥梁
在随后的新闻发布会上,Meta宣布他们正在开发的LLaMa-2-Chat不仅适用于商业用途,而且还可以通过微软的云服务Azure访问。
这是一个巨大的突破,因为企业客户现在不仅可以通过Azure云利用ChatGPT,还可以访问LLaMa。
但这里的关键是LLaMa 2实际上是可下载的,这意味着客户可以将其安装在自己的私人服务器上,从而永远消除将数据发送到OpenAI或Anthropic服务器所需的安全风险。
因此,LLaMa-2-Chat可能成为第一个真正广泛应用于企业用例的聊天机器人,这本质上意味着,也许最终Meta首席科学家Yann LeCun是对的:
“开源最终将赢得人工智能”。 ——Yann LeCun
用自己的方式书写历史
Meta大胆地发布了LLaMa 2和LLaMa-2-chat,这标志着大型语言模型开发领域的一个明显转变。
这不仅仅是介绍另一款尖端产品,这是对微软等科技巨头的大胆声明,强调Meta致力于使这些模型训练的知识和工具民主化。
现在,人工智能行业有了第一个高性能聊天机器人,并附有一份长达70页的研究论文,其中提供了解其构建过程所需的所有细节。
因此,Meta不仅仅是平衡竞争环境,还有望重新定义它。
Meta通过使RLHF的复杂过程更容易理解并结合两种奖励模型组合等见解,不仅揭开了LLM训练的帷幕,而且还准备将开源提升到无与伦比的高度。
曾经是少数人的领域现在向全球社区开放,并可能推动开源模型迎头赶上世界上一些最强大的公司保护和保障的专有模型。
你对此感到兴奋吗?欢迎在评论区留言。
感谢阅读。你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Ignacio de Gregorio
翻译作者:文玲
美工编辑:过儿
校对审稿:Chuang
原文链接:https://medium.com/@ignacio.de.gregorio.noblejas/meta-llama2-90dae8bbf750



