
2.5年MLflow经验总结之八个技巧
我从Databricks客户互动中学到的。
在Databricks,我帮助大型组织部署和扩展机器学习管道。以下是我在这一过程中学到的8个关于MLflow的关键技巧。如果你想了解更多关于MLflow的相关内容,可以阅读以下这些文章:
MLOps→LLMOps→AgentOps:引领AI系统的未来发展
实现高效MLOps的六个关键原则
MLOps简介:机器学习的实验跟踪
2022 年科学家必须知道的顶级MLOps工具数据
0. MLflow的优势与不足
MLflow的优势在哪里?
MLflow非常适合以迭代开发为核心的团队,但通常需要一定的学习曲线。
MLflow是一个开源的MLOps工具,旨在简化机器学习开发生命周期管理。它涵盖了机器学习项目的各个阶段,确保每一步都可以被管理、追踪和复现。如果需要复习基础知识,可以参考本教程。
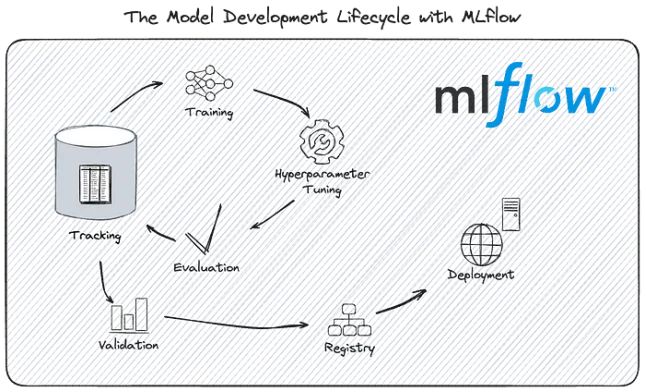
MLflow的优势
- 团队协作:MLflow简化了模型的版本控制、组织和部署,使多个团队成员能够高效协作并管理多种模型。
- 便捷的部署:MLflow会自动组织模型服务所需的包和文件依赖项。通过PyFunc提供标准化API的模型服务,或以原始格式加载模型并利用其本地API进行操作。
- 支持迭代开发:MLflow的跟踪功能支持高效的迭代开发。通过自动记录或显式跟踪调用,你可以方便地组织和比较不同实验。
- 与Databricks的深度集成:Databricks的大部分机器学习产品都围绕MLflow构建,并提供高性能、可扩展的企业版MLflow(对Databricks用户免费)。
MLflow的不足
- 复杂性:MLflow的强大功能带来了一定的学习曲线,这对新手来说可能具有挑战性。本文旨在帮助简化这一过程。
- 文档的可用性:MLflow的文档内容虽然丰富,但可能较难浏览。请参阅技巧2以获取更简单的方法。
- 总结:对于以迭代模型开发为核心的技术团队来说,MLOps框架必不可少,而MLflow是一个优秀的选择。
1. MLflow术语表
以下是MLflow中与MLOps框架相关的一些关键术语:
- 工件(Artifact):与训练运行相关的文件或对象,例如数据集、模型文件或度量输出。
- 运行(Run):一组记录的工件。传统上,运行通常与训练过程相关,但在生成式AI(GenAI)中,其定义已被扩展。
- 实验(Experiment):一组运行的集合。
- 模型(Model,注册表中):一组相关的模型版本,由唯一名称标识。
- 模型版本(Model Version,注册表中):模型的特定迭代,通常与特定的运行或训练周期相关联。
- 模型签名(Model Signature):定义模型预期输入和输出格式的模式,包括额外的推理参数。
这些定义背后还有更多复杂性,超出本文讨论范围。
2. 如何高效浏览MLflow文档?
MLflow的文档内容丰富,但导航体验较为复杂。最近,一个名为RunLLM的第三方工具被集成到了MLflow文档中,它提供了更高效的方式来访问代码片段并找到问题的答案。
3. 如何正确记录模型?
答案:使用log_model()并设置以下4个关键参数
许多新手在记录模型时容易出错。虽然log_model()看似简单,但如果配置正确,它可以提供丰富的功能支持:
确保为你的模型类型使用正确的log_model()方法。例如,使用mlflow.sklearn.log_model()记录Scikit-learn模型。如果MLflow不支持你的模型类型,可以使用mlflow.pyfunc.log_model()记录自定义PyFunc模型。
需要设置的4个关键参数:
- model:要记录的模型对象。
- artifact_path:保存模型工件的相对路径。
- registered_model_name:在模型注册表中注册的名称。
- input_example:模型推理的示例输入数据。
通过正确配置,你可以获得以下好处:
- 序列化的模型工件,可通过跟踪服务器或模型注册中心访问。
- 自动生成列出推理依赖项的requirements.txt文件。
- 带附加依赖项的Conda环境规范文件。
- 在MLflow UI中查看模型输入/输出示例和模型签名。
示例代码:
import mlflow
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
with mlflow.start_run():
# Create the model
X,y = load_iris(return_X_y=True)
model = RandomForestClassifier().fit(X, y)
# Log the model
mlflow.sklearn.log_model(
sk_model=model,
artifact_path="local_path_to_model",
registered_model_name="my_awesome_model",
input_example=X
)此实现适用于大多数用例。如果需要更高的定制化,你可以结合log_model()和mlflow.register_model()进行扩展。
4. 模型注册表与跟踪服务器的区别
跟踪服务器保存的是原始数据,而模型注册表则保存你记录的工件的元数据。
在开源版MLflow中,跟踪服务器和模型注册表是用户管理的两个后端系统,用于存储模型开发的数据。以下是两者的主要区别:
- 跟踪服务器:存储来自实验的实际数据,例如序列化的模型文件、度量和工件。它通常使用对象存储解决方案(例如S3、ADLS、GCS)来管理这些文件。
- 模型注册表(Model Registry):充当轻量级元数据层,通过在跟踪服务器中存储对工件的引用(指针)来组织和管理模型版本。它通常使用关系数据库(例如MySQL、PostgreSQL)来管理这些元数据。
5. 什么是URI?
URI用于查询run_id和relative_artifact_path。
MLflow中的URI是用于定位特定模型或工件的唯一标识符。假设模型URI是加载模型的入口点,URI在MLflow中被广泛使用,因此理解它们至关重要。以下是将模型加载回内存的最佳方法(以Scikit-learn为例)。
############# Via Runs #############
# Use this if you log and load the model in the same Python session
# Option 1: URI recreated from the model info
with mlflow.start_run() as run:
# Log the model
model_info = mlflow.sklearn.log_model(
sk_model=model,
artifact_path=artifact_path,
)
model_uri = model_info.model_uri
# Option 2: URI recreated from a run object
artifact_path = "my_cool_model"
with mlflow.start_run() as run:
# Log the model
mlflow.sklearn.log_model(
sk_model=model,
artifact_path=artifact_path,
)
model_uri = f"runs:/{run.info.run_id}/{artifact_path}"
############# Via Model Registry #############
# Use this if you DON'T log and load the model in the same Python session
# Option 1: URI that points to the model registry via a model version
model_name = "my_cool_model"
model_version = 3
model_uri = f"models:/{model_name}/{model_version}"
# Option 2: URI that points to the model registry vai a model alias
model_name = "my_cool_model"
model_alias = "prod"
model_uri = f"models:/{model_name}/{model_alias}"注意,你还可以利用MLflowClient或fluent api进一步与这些模型进行交互。
6. 你应该如何对spark数据框架进行预测?
答案:Spark用户定义函数(udf)
MLflow Spark udf利用Pandas udf来并行化模型的推理。
import mlflow
from pyspark.sql.functions import struct
# Step 1: Train and log your model
# (your model training and logging code here)
# Step 2: Create a Spark DataFrame `df` for inference
# (your DataFrame creation code here)
# Step 3: Perform inference using the logged model
model_uri = "/path/to/logged/model"
custom_predict_udf = mlflow.pyfunc.spark_udf(spark, model_uri)
df.withColumn("prediction", custom_predict_udf(struct("name", "age"))).show()为什么你应该使用mlflow.pyfunc.spark_udf?
- 并行推理:Spark UDF利用Spark的分布式计算能力来并行处理推理任务。
- 优化的性能:Pandas UDF是Spark中性能最优的Python UDF类型。
- 自动依赖管理:依赖项会在Spark Worker上下文中自动加载,这大大简化了设置过程。
7. 如何使用MLflow跟踪GenAI代理?
回答:使用MLflow的自动记录(Auto-logging)来跟踪代理执行的粒度信息。
如果您正在构建GenAI代理而尚未使用跟踪功能,那么这将极大地改善您的工作流程。
由于GenAI代理的执行通常是异步和不确定的,能够准确跟踪每一步的执行非常宝贵。
MLflow提供了高级的跟踪API,支持在代理框架内进行详细的执行跟踪。对于许多MLflow支持的模型类型(例如LangChain和LlamaIndex),您可以通过调用mlflow.{flavor}.autolog()来自动捕获该类型的所有操作的完整日志。
对于没有本机自动记录支持的库,您可以通过@mlflow装饰器在任何Python可调用对象上实现自定义跟踪。
在下图4中,我们可以看到一个RAG代理的MLflow跟踪UI示例。图中清晰地展示了主要代理组件的执行顺序、持续时间和输入/输出。
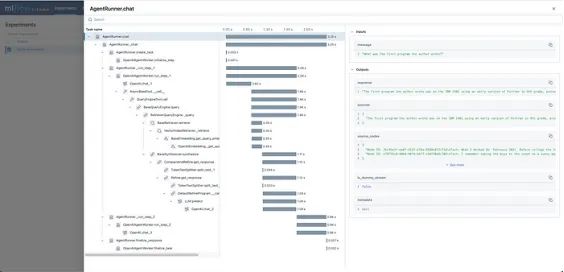
这种细粒度的执行数据有助于快速识别错误、优化性能,并提升响应质量。
Model from Code特性
Model from Code特性允许您直接在Python中定义模型。这种方法绕过了许多序列化挑战,尤其是在使用基于Pydantic的GenAI包时,使得模型的部署变得更加平滑和灵活。
自定义PyFunc模型非常通用——几乎任何东西都可以变成一个模型!尽管这种灵活性非常强大,但它只涉及一个基本的类实现,能够提供大量的功能和多样化的用途。
模型版本别名
模型版本别名是将模型服务端点与所服务的特定模型版本解耦的极好方法。通过为模型版本分配可变标识符,您可以无缝地更新所服务的模型,而无需更改端点配置。这种灵活性使得在生产环境中管理和更新模型变得更加容易。
总结
总之,MLflow是一个功能强大的MLOps工具,能够高效地管理整个机器学习生命周期。然而,只有通过一些特定的策略,才能充分发挥其潜力。通过深入理解MLflow的关键特性,团队能够简化模型开发、促进协作并高效地管理产品化流程。
感谢阅读!你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/。
原文作者:Michael Berk
翻译作者:文杰
美工编辑:过儿
校对审稿:Jason
原文链接:https://michaelberk.medium.com/25-years-of-mlflow-knowledge-in-8-tips-b6023dd168df





