
数据人必知的5个异常值检测小技巧,你用过哪个?
异常值是与总体样本中的其他数据点存在显著差异(不同属性)的观测值。在本文中,我们将介绍每个“数据爱好者”都必须了解的 5 种异常值检测技术。如果你想了解更多关于数据分析的相关内容,可以阅读以下这些文章:
一篇文章带你了解探索性数据分析
8 种数据挖掘技术,让你成为更好的数据分析师
Python为什么这么火?如何利用Python进行数据分析?
20个常用函数——用Excel做数据分析
但在此之前,让我们了解一下异常值的来源。
数据集中异常值的可能来源是什么?
数据集中可能存在异常值的原因有多种,例如人为错误(错误的数据输入)、测量错误(系统/工具错误)、数据操作错误(错误数据的预处理错误)、采样错误(从异构来源创建样本)等。检测和处理这些异常值对于学习一个健壮且可推广的机器学习系统非常重要。

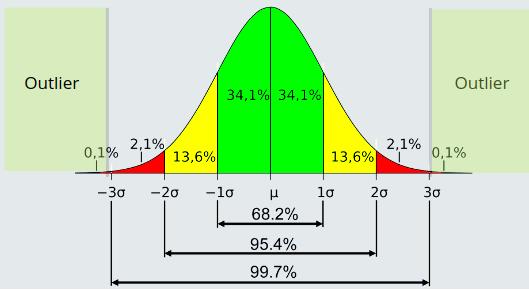
Z分数(也称为标准分数)是统计学中的一个重要概念,它表示某个点离均值有多远。通过应用Z变换移动分布,并使其具有单位标准偏差的0均值。例如,Z分数为2表示数据点与均值相差2个标准差。
此外,任何数据点的Z-Score都可以按如下所示进行计算:
Z-Score(i) = (x(i) -均值) / 标准差
它假设数据是正态分布的,因此位于±1标准差之间的数据点的百分比约为68%,±2标准差约为 95%,±3标准差约为 99.7%。因此,如果Z-Score > 3,我们就可以将该点标记为异常值。参考下图。
你可以用Python实现它,如下所示:
import numpy as np
data = [1, 2, 3, 2, 1, 100, 1, 2, 3, 2, 1]
threshold = 3
mean = np.mean(data)
std = np.std(data)
z_score_outlier = [i for i in data if (i-mean)/std > threshold]
print (z_score_outlier)
>> 100 (outlier)你还可以在Python中使用Scikit-learn和Scipy提供的内置函数。(参考资料部分的链接)

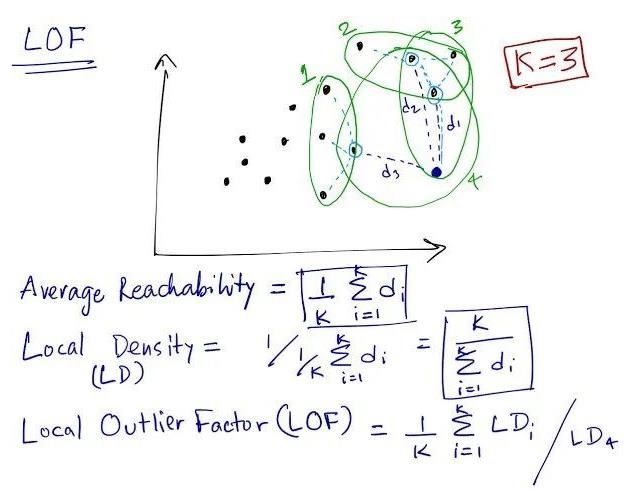
在局部离群因子 (LOF) 中,该概念围绕局部区域展开。在这里,我们计算并比较了焦点的局部密度及其邻域的局部密度。如果我们发现焦点的局部密度与相邻点相比非常低,这将暗示焦点在该空间中是孤立的,并且是一个潜在的异常值。该算法取决于超参数K,它决定了计算局部密度时要考虑的邻域数。该值在空间中的0(无相邻点)和总点(所有点都是相邻点)之间有界。
局部密度函数定义为平均可达距离的倒数,其中,平均可达距离定义为焦点到邻域中所有点的平均距离。
LOF = 邻域的平均局部密度/焦点的局部密度
如果:
- LOF ≈ 1 与邻域密度相似
- LOF < 1 密度高于邻域(正常点)
- LOF > 1 密度低于邻域(异常)
此外,下图显示了空间中样本焦点(深蓝色)的LOF和局部密度的计算。这里,K=3 (邻居),d(距离)可以计算为欧几里得、曼哈顿等。
你可以使用python的Scikit-learn库来实现它,如下所示:
from sklearn.neighbors import LocalOutlierFactor
data = [[1, 1], [2, 2.1], [1, 2], [2, 1], [50, 35], [2, 1.5]]
lof = LocalOutlierFactor(n_neighbors=2, metric='manhattan')
prediction = lof.fit_predict(data)
>> [ 1, 1, 1, 1, -1, 1]请随意探索该库进行超参数调整等(参考资料部分中的链接)

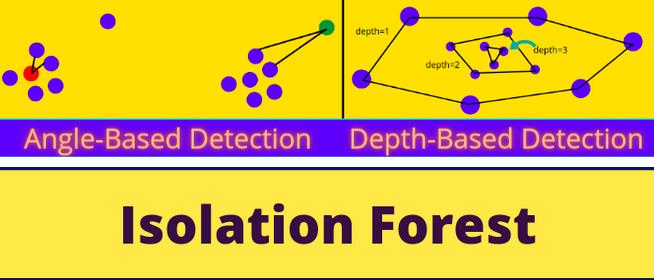
我主要关注基于角度的技术(ABOD)和基于深度的技术(Convex Hull)。你可以在这里查看 ABOD。下图显示了这两种检测异常值的技术视图:
隔离森林是一种基于树的算法,它试图根据决策边界的概念找出异常值(就像我们对决策树所做的那样)。这里的想法是继续以随机阈值和特征分割数据,直到每个点都被隔离(这就像在数据集上过度拟合决策树)。一旦实现隔离,我们就把在这个过程中很早就被隔离的点分块出来,并将这些点标记为潜在的异常值。你可以直观地看到这一点,如果一个点离大多数点越远,它就越容易隔离,而隔离属于一个组的点需要更多的切割来隔离每个点。
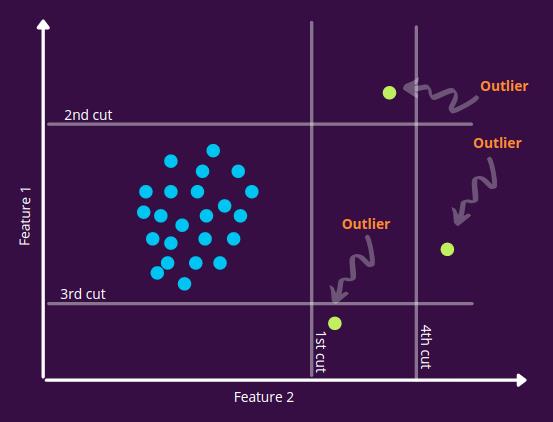
如果你在下图中看到,我们会随机选择切割位置的特征和值。在4次切割之后,我们就能够分离出异常点,这意味着,这些节点将在构建树的早期阶段出现。
你可以使用Python的Scikit-learn 库来实现它,如下所示:
from sklearn.ensemble import IsolationForest
data = [[1, 1], [2, 2.1], [1, 2], [2, 1], [50, 35], [2, 1.5]]
iforest = IsolationForest(n_estimators=5)
iforest.fit(data)
actual_data = [[1, 1.5]]
iforest.predict(actual_data)
>> 1 (Normal)
outlier_data = [[45, 55]]
iforest.predict(outlier_data)
>> -1 (Outlier)请随意探索该库进行超参数调整等(参考资料部分中的链接)

自动编码器是经过训练再现输入本身的神经网络架构。它由两个可训练的组件组成,即编码器和解码器。其中编码器的目标是学习输入的潜在表示(原始维度到低维度),而解码器的目标是学习从该潜在表示(低维度到原始维度)重构输入。因此,为了让自动编码器正常工作,这两个组件都应该针对各自的任务进行优化。
自动编码器广泛用于检测异常。其背后典型的工作原理是,如果特征空间中的一个点远离大多数点(这意味着它具有不同的属性,例如,狗图像聚集在特征空间某个部分周围,而牛图像则离该簇相当远),在这种情况下,自动编码器会学习狗的分布(因为狗图像的数量比牛的数量要高——这就是为什么它是异常的,因此模型主要关注于学习狗集群)。
这意味着,该模型或多或少能够正确地重新生成狗图像,从而导致较低的损失值,而对于牛图像,它将产生较高的损失(因为这是它第一次看到的奇怪现象,而它所学到的权重主要是重建狗图像)。我们使用这些重建损失值作为异常分数,因此分数越高,输入成为异常的可能性越高。
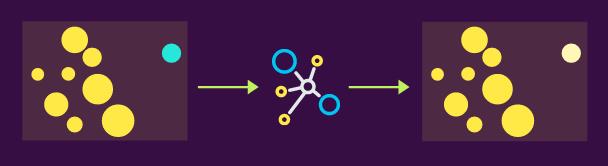
在下图中,将绿点视为狗,蓝点视为牛。我们用这种输入分布来训练系统,并期望它输出相同的结果。但我们可以看到,该模型或多或少完美地重新生成了黄点,但不能很好地适合蓝点(因为它与黄点的特征范围不同)
在下图的推理过程中,当我们给模型加上一个黄点时,它能够重新生成它,误差较小(正常点的信号),而对于蓝色点,由于无法重新生成,它返回一个高误差(异常/离群值的信号)。
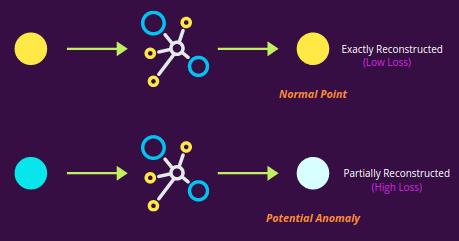
你可以使用Python的PyOD库来实现它。(参考资料部分中的链接)

在使用入度数(ODIN)的异常值检测中,我们计算每个数据点的入度。这里,入度定义为该点所属的最近邻集的数量。值越高,该点属于空间中某个密集区域的置信度越高。而另一方面,这个值越小,就意味着它不是许多最近邻集的一部分,并且在空间中是孤立的。你可以把这个方法想成是KNN的反面。
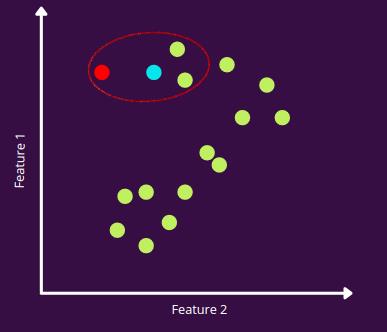
在图中,我们设置k(最近邻)=3,红点仅属于一个最近邻集,该最近邻集为蓝点集,而所有其他点都是多个最近邻集的一部分。因此,我们得出结论,红点是一个异常值。
你可以使用 Python 的package-outlier库来实现它。
如下所示:
import package_outlier as po
data = [[1, 1], [2, 2.1], [1, 2], [2, 1], [50, 35], [2, 1.5]]
result = po.LocalOutlierFactorOutlier(data)
print (result)请随意探索该库进行超参数调整等(参考资料部分中的链接)
资源:
- PyOD:https ://pypi.org/project/pyod/
- Scikit-Learn:https ://scikit-learn.org/stable/index.html
- package-outlier:https ://pypi.org/project/package-outlier/
感谢阅读,欢迎订阅。你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Prakhar Mishra
翻译作者:过儿
美工编辑:过儿
校对审稿:Miya
原文链接:https://towardsdatascience.com/5-outlier-detection-methods-that-every-data-enthusiast-must-know-f917bf439210





