
6种常见处理Missing Value的方法
许多现实世界中的数据集会因为各种原因而包含缺失值,这些缺失值通常会被留为空白,或是被标记为NaNs或其他占位符。在训练一个包含很多缺失值的数据集时,缺失值的存在会很大程度上影响机器学习模型的表现。scikit-learn中的一些算法会假设所有值都是数值型且包含意义的。
处理这种问题的一种途径是删除包含缺失值的observations,但是这种做法存在丢失有价值信息的风险。另一种更优的策略则是插补缺失值,也就是从观测的数据中推测出缺失值的大小。常见的缺失值有三种分类:
●完全随机缺失 (Missing completely at random, MCAR)
(注:缺失数据发生的概率与任何值均无关,包括观测到的与缺失的值)
●随机缺失 (Missing at random, MAR)
(注:缺失数据发生的概率与观测到的其他变量的值有关,但与它本身的值无关,例如体重信息是否缺失与性别变量有关,女性群体体重信息缺失的概率更高)
●非随机缺失 (Not missing at random, NMAR)
(注:缺失数据发生的概率与它本身的值有关,例如学历信息缺失的群体往往是学历最低的群体,是不可忽略的缺失形式)
这篇文章将会介绍针对cross-sectional数据集六种常见的插补缺失值的方法。(不针对时间序列数据集,时间序列数据集会用到别的方法)
01 什么都不做
这是最简单的一种策略:什么都不做,然后直接依靠算法本身来解决这个问题。有一些算法,例如XGBoost,会通过training loss reduction来学习并找到最佳插补值。另一些算法可以设置选项以忽略缺失值,例如LightGBM – use_missing = false。但是其他的算法,例如scikit learn里的Linear Regression,则会因为缺失值报错。那么在这种情况下,你就需要在把数据扔给算法前清理好缺失值。
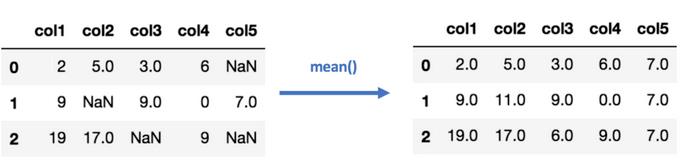
02 Mean/Median插补
计算每列数据中非缺失值的平均数或中位数,然后用平均数或中位数补齐每列中的缺失值。这种方法只适用于数值型数据。
优点:
● 快速、容易实现
● 对小型数值型数据集很好用
缺点:
● 没有考虑到特征间的相关性,只单独对每列进行计算
● 在encoded categorical variable上效果很差,不建议这样使用
● 不会非常精确
● 没有考虑到插补值的不确定性
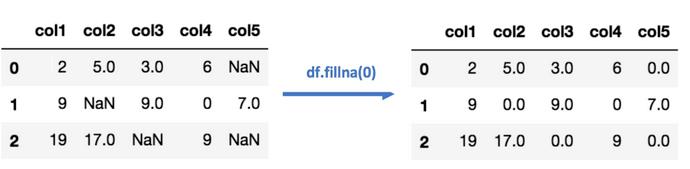
03 频率最高 / 0 / 其他常数插补
使用众数,即每列出现频率最高的数,补齐每列中的缺失值。这种方法可以用在categorical variable上。
优点:
● 适用于分类变量
缺点:
● 依然没有考虑到特征间的相关性
● 对样本存在干扰

除了出现频率最高的数,另一种方式是用0,或指定的其他常数来插补。
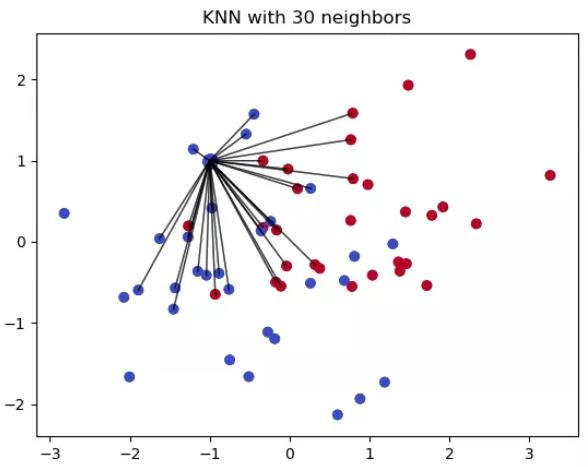
04 KNN插补
KNN是一种Classification算法。这种算法基于特征相似性来预测新数据点的值,这就意味着新数据点是基于和其他点的相似程度来被赋值。这对于缺失值的预测非常有用:找到距离缺失值距离最近的K个数据点,然后基于这些点的值来插补缺失值。Impyute library支持KNN插补法。

那它是如何实现的呢?首先创建一个基本的均值插补,使用complete list构建一个KDTree, 然后使用KDTree来计算距离最近的点(NN),找到距离最近的K个点以后,取这些点的加权平均数。
优点:
● 比mean / median / most frequent 插补的方法更精确
缺点:
● 计算量大,需要在memory里存储整个training数据集
● KNN对outliers非常敏感
05 多重插补
Multivariate Imputation by Chained Equation (MICE)
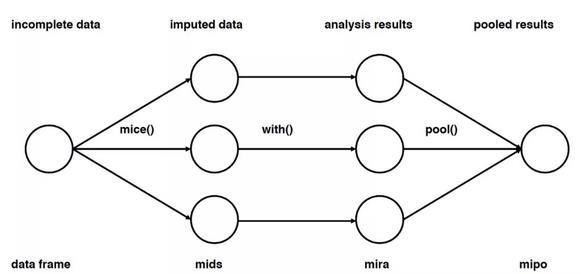
这种方法是通过多次插补实现的。(注:多值插补的思想来源于贝叶斯,认为待插补的值是随机的,它的值来自于已观测到的值。过程大致为复制多份原数据集,在每份数据集上使用MICE算法上填补缺失值,依据所选取的统计方法分析结果,合并产生最终的插补值)。这种方法考虑到了缺失值的不确定性,因而优于其他简单的插补方法。且这种方式非常灵活,适用于continuous、binary等不同数据类型,也能应对bounds, survey skip patterns等不同复杂程度。
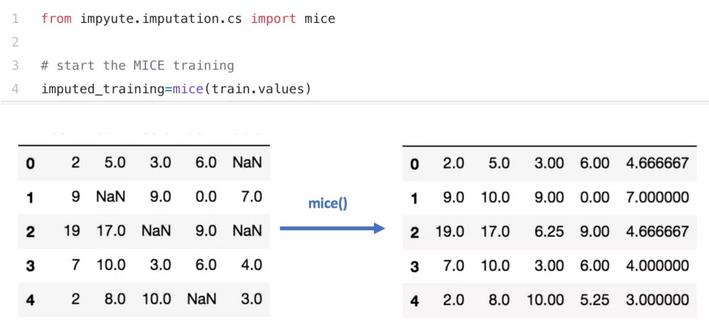
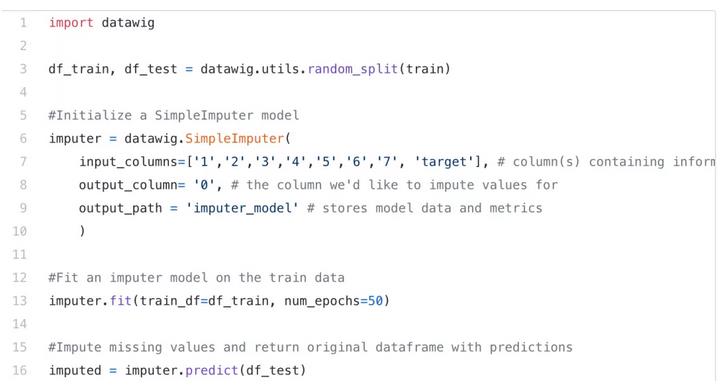
06 深度学习插补
(Datawig library)
这种方法适用于分类变量和非数值型变量的特征。datawig library使用 Deep Neural Networks来插补缺失值,并且他支持CPU和GPU训练。
优点:
● 相较其他方法非常准确
● 可以处理categorical variable (有feature encoder功能)
● 支持CPUs和GPUs
缺点:
● 单列填补
● 处理大型数据集很慢
● 必须指定包含目标列信息的所有列
其他插补方法:
1. Stochastic regression imputation
Regression imputation是利用数据集中的其他相关变量建立回归模型,来预测缺失值,stochastic regression imputation则是在此基础上加上一个随机的residual term。
2. Extrapolation and Interpolation
通过一定范围内的已知的数据点来估计缺失值。(注:观测到一定范围内的数据点,extrapolation是估计范围以外的数据点的值,interpolation是估计范围以内的数据点的值)
3. Hot-Deck imputation
从其他相关且相似变量中取值。
总结来说,没有一个最完美的插补策略,每个策略都会更适用于某些数据集和数据类型,但再另一些数据集上表现很差。虽然有一些规则能帮助你决定选用哪一种策略,但除此之外,你还应该尝试不同的方法,来找到最适用于你的数据集的插补策略。
注解sources:
https://www.iriseekhout.com/missing-data/missing-data-methods/imputation-methods/
https://whatis.techtarget.com/definition/extrapolation-and-interpolation
原文作者:Will Badr
翻译作者:Shuang Lu
美工编辑:过儿
校对审稿:Dongdong




