
用无监督学习生成吊炸天Spotify播放列表
在本系列之前的博文里(见:https://towardsdatascience.com/tagged/music-by-numbers),我们探索了音乐串流巨头Spotify如何建立算法,仅基于波形就能描述任何歌曲的音乐特征(见:https://developer.spotify.com/documentation/web-api/reference/tracks/get-audio-features/)。
这些算法可以计算一些明显的音乐成分,如歌曲的速度和调子。然而,他们也有更为细微的度量项目:歌曲有多欢快?它冷淡还是高能?它是不是舞曲?
为了展示该工作如何进行,我用一些电子乐内容建立了一个播放列表,从Kendrick Lamar到Black Sabbath,从Beatles到Billie Eilish都含在内,当然也有Despacito。
让我们看看Spotify是怎样用多种音频特征指标给这些歌曲分类的。这些指标的完整描述见:https://towardsdatascience.com/analysing-the-greatest-show-on-earth-e234f611e110。
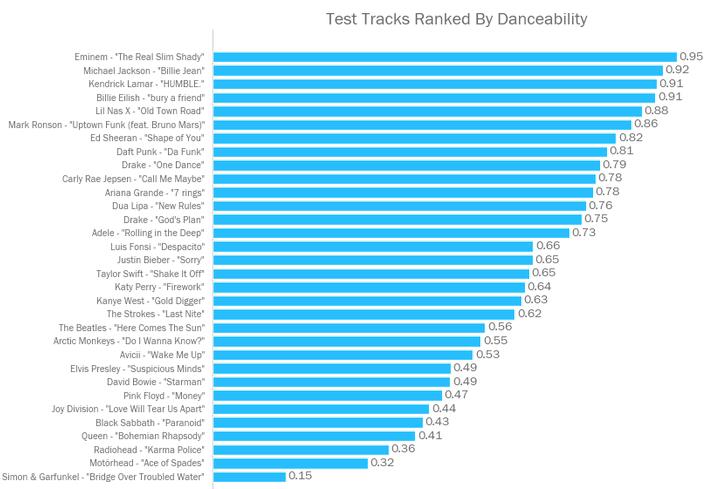
用有稳定、不间断节拍的歌曲被认为是更适合跳舞——因此Rap歌曲如Real Slim Shady和 Humble此项得分较高。
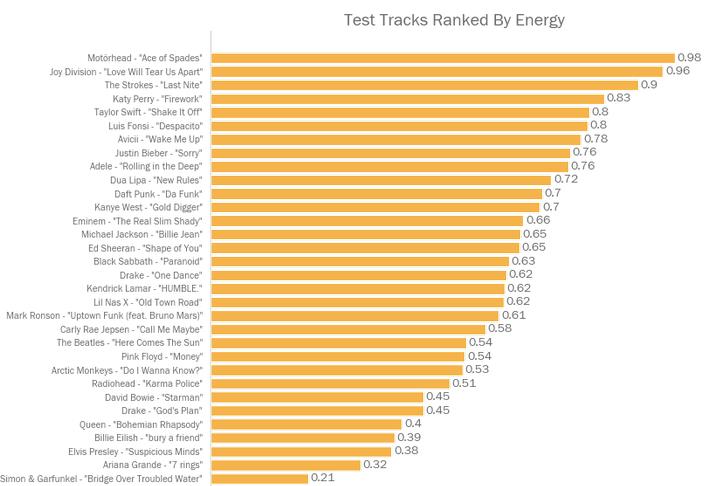
正如我们在前篇博文里注意到的,跳舞性和活力并非像我们预期的那样高度相关。其中Ace of Spades是最有活力的一首歌,凡是去看过Motörhead现场表演的人都不会对这个结果惊讶的。
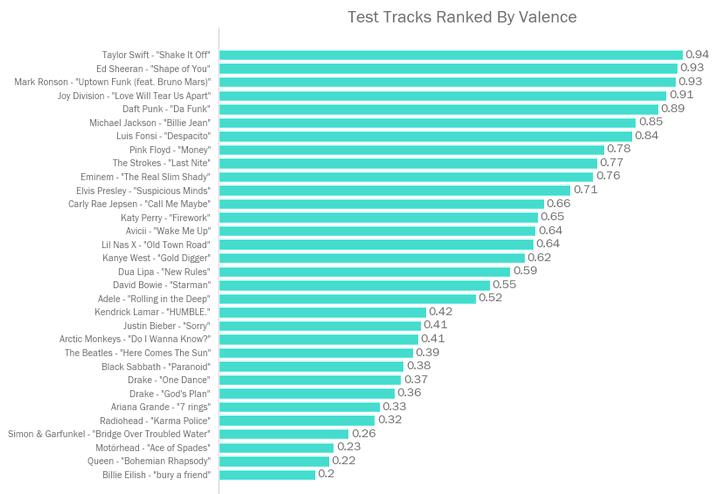
高音乐价的歌曲欢快欣喜,低音乐价的歌曲阴沉悲伤。所以Billie Eilish此项垫底不奇怪。
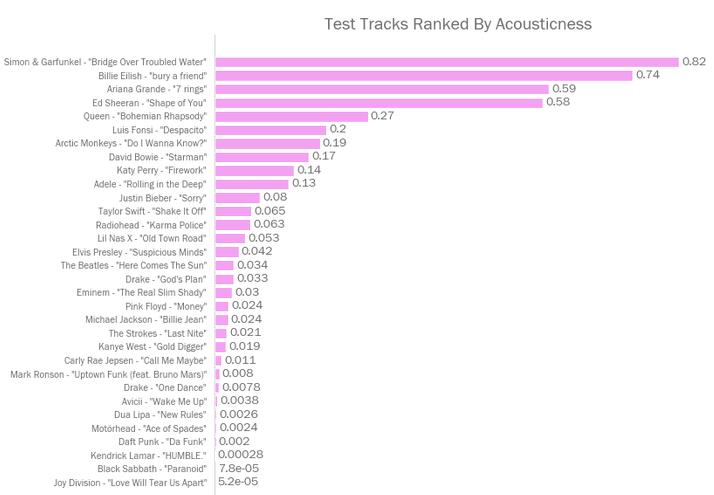
这一项,Spotify将歌曲是否为原音乐——即由真实乐器天然产生的声音——归纳为一个0到1之间的衡量度。Bridge Over Troubled Water被正确辨别了出来。Black Sabbath的重金属也被排在了底部。
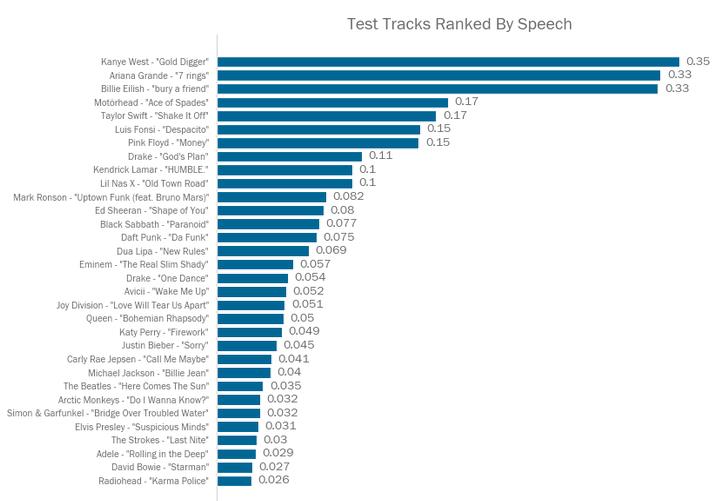
‘语言性’试图找出音频文件里的词汇。一则播客分数会接近于1,而Rap音乐的分数通常落在0.02到0.05之间。

Spotify正确定位了播放列表里唯一的无人声歌曲(Daft Punk),但却认为Joy Division是一种乐器(可能是由于Ian Curtis唱歌风格,其在整体混音里较为低沉)。
当然,我们可以用这些测度来考虑哪些歌曲在声波上更相似。先从最简单的开始,我们假设歌曲只有两项特征——跳舞性和音乐价。两个变量取值范围都在0到1之间,所以我们就可以根据歌曲在散点图上的距离来推断它们的相似性了。
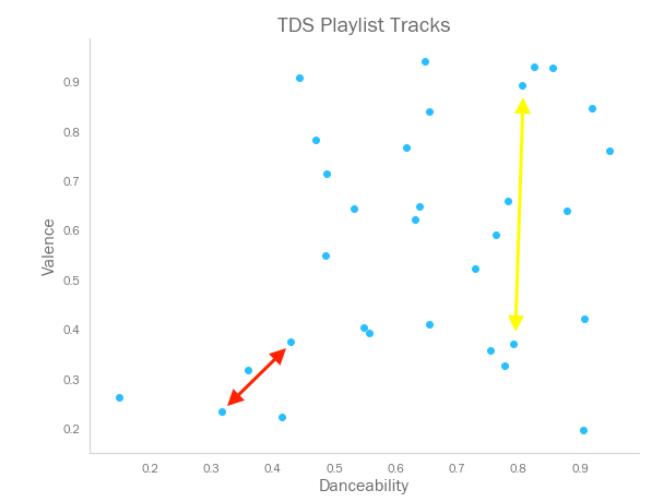
红箭头两端的歌曲要比黄箭头两端的更加相似,尽管第二对儿歌曲有着极为相近的跳舞性。
我们可以再拓展一下这个逻辑。给定列表里的一首歌,通过寻找它在散点图上最近的n个点,我们就可以得出与它最相似的n首歌。还可以再复杂一点:我们拿来32首歌,要把它们分进5个播放列表里面去。那我们就要想办法处理上面的散点图,把各个点分进5个组里,各组内的歌曲都要满足彼此‘最佳相似’。
这听起来像聚类算法。这次我们可以采用‘分层聚集聚类’,即HAC。简单来说,HAC开始先把各个点都看成一个独立的簇类。然后将距离最近的两个簇合并——注意,这个语境下‘距离’的定义发生了变化。HAC算法会反复合并最近的簇,直到所有的数据点都进入同一个簇为止——这是该算法的自然结论。
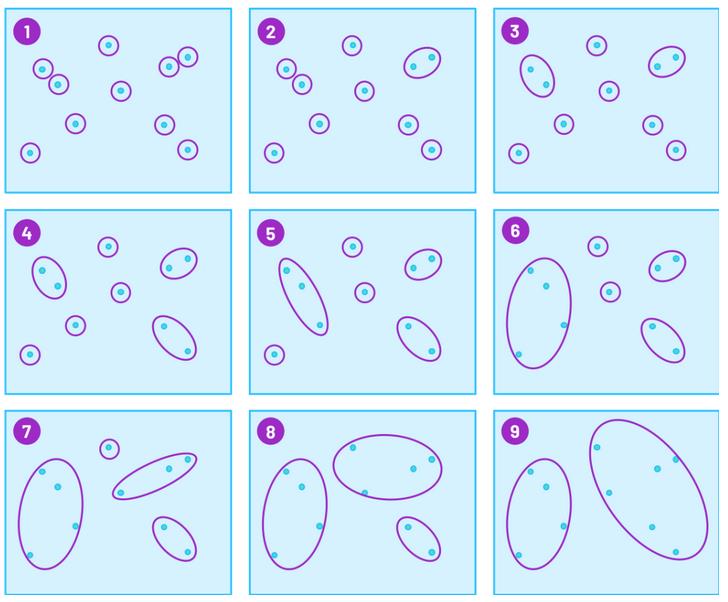
正如上文所说,算法对两个簇类之间距离的定义是可变的。Scikit-learn在HAC包内提供了3种这样的‘关联标准’。
- Ward(默认项):选取两个簇类进行合并,使得所有簇类间的方差增长最小。总体上,该方法会使各个簇类的大小相当。
- Average:将所有点间的平均距离最小的两个簇合并。
- Complete(或最大关联):将各个点间的最大距离最小的两个簇合并。
由于HAC需要处理距离——不论该距离是否是抽象的——我们在把数据喂给聚类算法之前,得对其进行标准化缩放。这可以确保我们的结果不向某个特征单位偏斜。例如,音乐速度一般是每分钟70到180拍之间,但是大部分其它变量的值都在0和1之间。不做缩放的话,两首速度大不相同的歌就总会距离很远,就算它们在其它指标上很相似。
使用Scikit-Learn进行标准化和HAC十分直接:

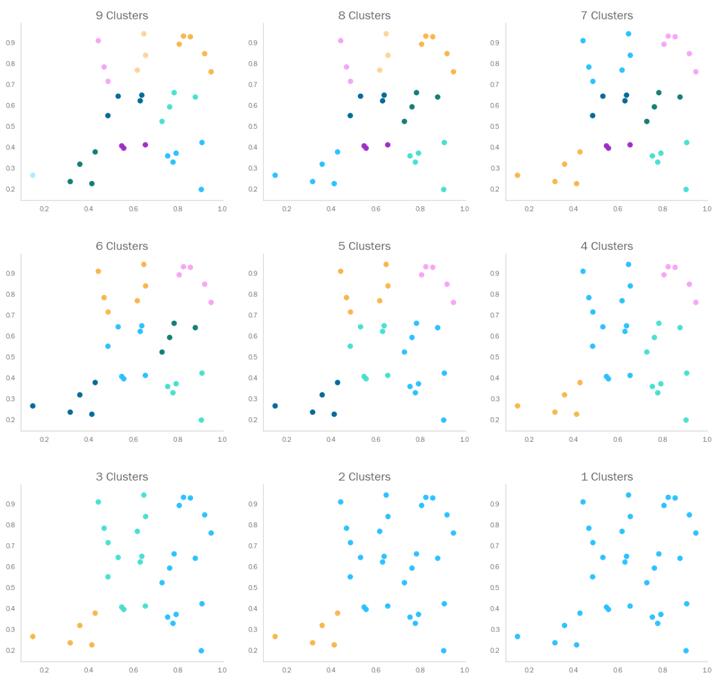
让我们对播放列表应用HAC吧——记住,此时我们仍然限制在二维,即横轴上的跳舞性和纵轴上的音乐价。我们可以看到,下面散点图里不同颜色的数量在随各个簇的合并而减少。
两点间距离可以在二维中定义,当然在三维中也可以。下图展示了当我们加入第三个维度‘活力’之后,HAC算法所建立的4个簇。
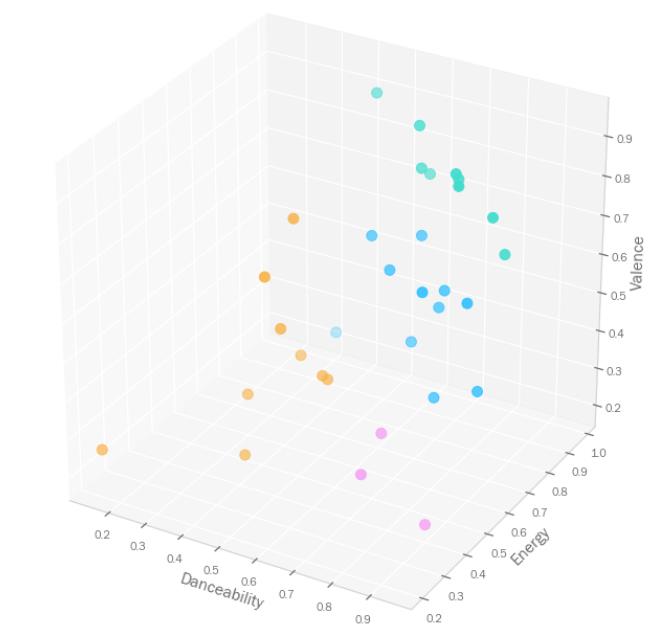
接下来我们可以继续增加维度,计算点间距离的方法是一样的,只不过我们不能在格框里面展示结果了。然而我们可以通过树状图来观察结果。下图中从左到右就是不同歌曲被连接为更大簇类的过程。
注意,图中的水平距离表示两个连接起来的簇有多近,长线意味着歌曲间的距离更远。若我们想建立n个簇类,那就可以用树状图来实现。只需要画一条直线,竖直穿过图上的合适区域,与其相交的横线数量就是你建立的簇类数量。
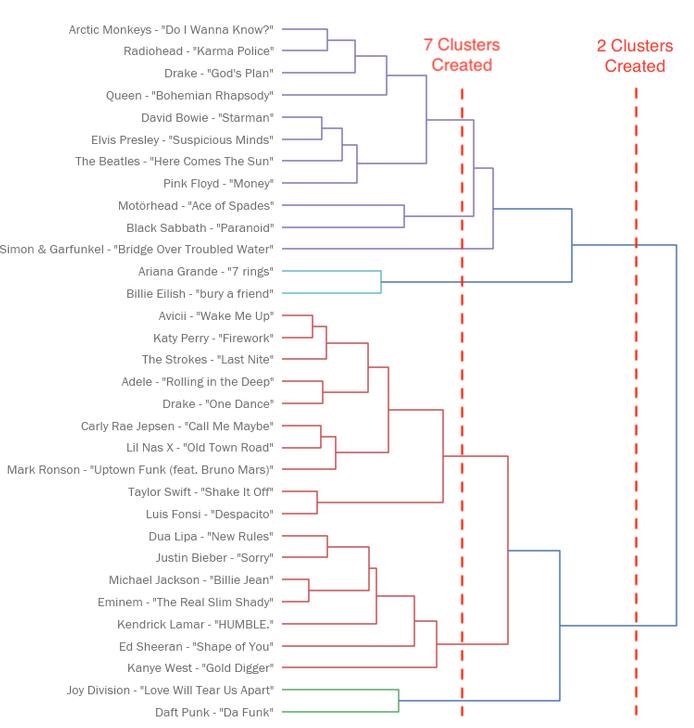
可以满意地说,该聚类分析得出了一些有趣的结果。Arctic Monkeys和Radiohead显然是对好床伴,Dua Lipa和Justin Beiber也是,还有Motörhead和Black Sabbath。Bowie、The Beatles、Pink Floyd和Elvis Presley听起来也是合理的一组,但是Michael Jackson和Eminem就是个比较奇怪的组合了。不过总的来说,Spotify的这些指标再加上HAC,在给歌曲分组方面确实表现不错。
原文作者:Callum Ballard
翻译作者:Siyu Hao
美工编辑:过儿
校对审稿:Dongdong
原文链接:https://towardsdatascience.com/generating-spotify-playlists-with-unsupervised-learning-abac60182022




