
处理不平衡数据的7个小技巧
银行欺诈检测、营销实时竞价或网络入侵检测等领域的数据集有什么共同点?如果你想了解更多关于数据分析的相关内容,可以阅读以下这些文章:
数据分析在Supply Chain方向有哪些应用?
顺利拿到数据分析师OFFER的作品集长什么样?
Excel小能手们,如何让自己数据分析及汇报的能力再上一层楼?
一篇文章带你了解探索性数据分析
在这些领域使用的数据通常只有不到 1% 的罕见但“有趣”的事件(例如使用信用卡的欺诈者、用户点击广告或损坏的服务器扫描其网络)。然而,大多数机器学习算法不能很好地处理不平衡的数据集。以下七种技术可以帮助您训练分类器来检测异常类。
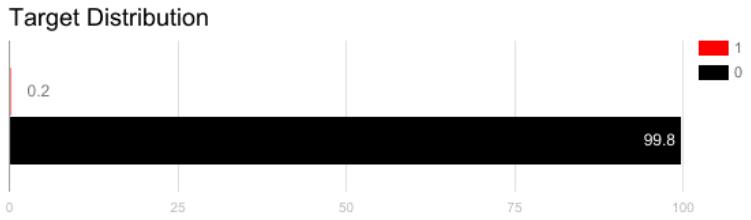
1 使用正确的评估指标
对使用不平衡数据生成的模型应用不适当的评估度量可能是危险的。假设我们的训练数据如上图所示。如果用准确度来衡量模型的优劣,将所有测试样本分类为“0”的模型将具有极好的准确度(99.8%),但显然,该模型不会为我们提供任何有价值的信息。
在这种情况下,可以应用其他替代评估度量,例如:
- Recall(召回率,查全率,击中概率):在所有GroundTruth为正样本中有多少被识别为正样本。
- Precision(查准率):在所有识别成正样本中有多少是真正的正样本。
- F1分数:精确度和召回率的调和平均值。
- MCC:观察到的和预测的二元分类之间的相关系数。
- AUC:真阳性率和假阳性率之间的关系。
2 对训练集重新采样
除了使用不同的评估标准外,还可以致力于获取不同的数据集。从不平衡的数据集中制作平衡数据集的两种方法是欠采样和过采样。
- 2.1.取样不足
欠采样通过减少丰富类的大小来平衡数据集。当数据量足够时,使用此方法。通过保持稀有类中的所有样本,并随机选择丰富类中相同数量的样本,可以检索到平衡的新数据集,用于进一步建模。
- 2.2.过采样
相反,当数据量不足时,使用过采样。它试图通过增加稀有样本的大小来平衡数据集。通过使用例如重复、自举或SMOTE(合成少数过采样技术)生成新的稀有样本,而不是去除大量样本[1]。
请注意,一种过采样方法没有绝对优势。这两种方法的应用取决于它所应用的用例和数据集本身。过采样和欠采样的组合通常也是成功的。
3 正确使用 K 折交叉验证
值得注意的是,在使用过采样方法解决不平衡问题时,应正确应用交叉验证。
请记住,过采样采用观察到的稀有样本,并应用自举技术根据分布函数生成新的随机数据。如果交叉验证是在过度采样之后应用的,那么我们所做的基本上是将我们的模型过度拟合到特定的人工自举结果。这就是为什么交叉验证总是在对数据进行过采样之前进行,就像特征选择应该如何实现一样。只有重复对数据进行重新采样,才能将随机性引入数据集,以确保不会出现过拟合问题。
4 不同过采样数据集的集合
成功推广模型的最简单方法是使用更多的数据。问题是,开箱即用的分类器(如逻辑回归或随机森林)倾向于通过丢弃稀有类进行泛化。一个简单的最佳实践是构建n个模型,使用稀有类的所有样本和丰富类的n个不同样本。假设您想要集成10个模型,你将保留例如1.000个稀有类案例,并随机抽样10.000个丰富类案例。然后,你只需将10000个案例分成10个块,并训练10个不同的模型。
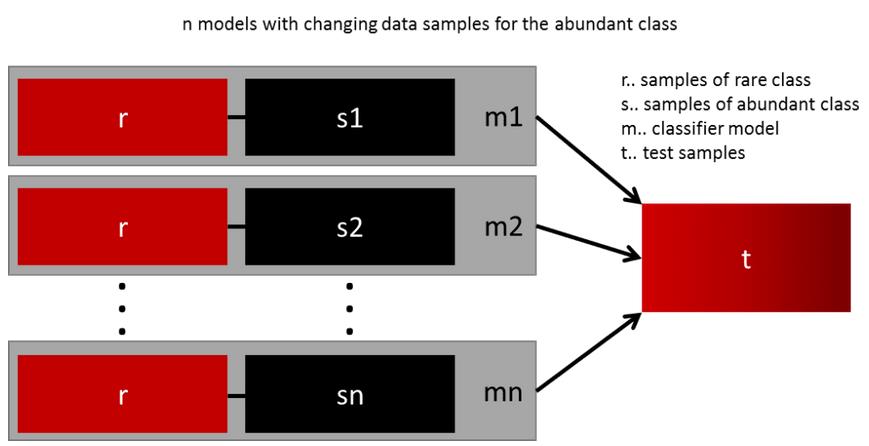
如果你有大量数据,这种方法非常简单,并且可以完全水平扩展,因为您可以在不同的集群节点上训练和运行模型。集成模型也倾向于更好地泛化,这使得这种方法易于处理。
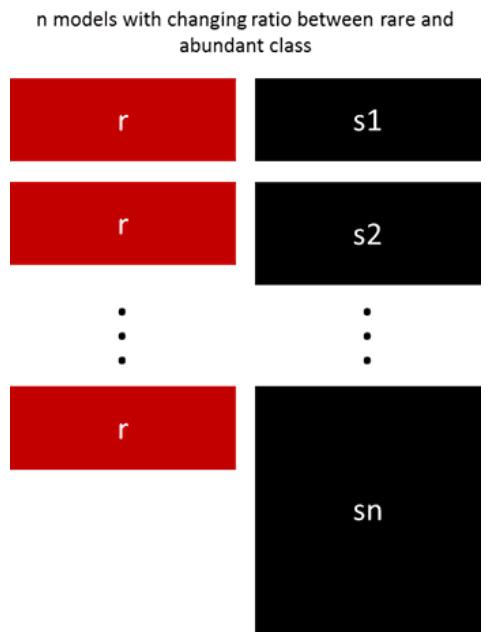
5 不同比率的过采样
前面的方法可以通过调整稀有类和丰富类之间的比率来进行微调。最佳比率在很大程度上取决于所使用的数据和模型。但是,与其在集合中以相同的比率训练所有模型,不如尝试集合不同的比率。因此,如果训练了10个模型,可能有一个模型的比例为1:1(稀有:丰富),另一个模型为1:3,甚至2:1。根据使用的模型,这可能会影响一个类获得的权重。
6 集群丰富类
Sergey 在 Quora [2] 上提出了一种优雅的方法。他建议不要依赖随机样本来覆盖训练样本的多样性,而是将丰富的类聚类到 r 个组中,其中 r 是 r 中的案例数。对于每个组,仅保留中心点(簇的中心)。然后仅使用稀有类和 medoids 对模型进行训练。
7 设计你的模型
之前的所有方法都专注于数据并将模型保持为固定组件。但实际上,如果模型适用于不平衡数据,则无需重新采样数据。如果类没有太多倾斜,著名的 XGBoost 已经是一个很好的起点,因为它在内部注意它训练的包不失衡。但话又说回来,数据被重新采样,这只是秘密发生的。
通过设计一个代价函数来惩罚稀有类的错误分类而不是丰富类的错误分类,可以设计许多自然泛化有利于稀有类的模型。例如,调整 SVM 以惩罚稀有类的错误分类,其比例与该类未被充分代表的比例相同。
最后的话
这不是唯一的技术列表,而是处理不平衡数据的起点。 没有适合所有问题的最佳方法或模型,强烈建议尝试不同的技术和模型来评估最有效的方法。尝试有创意并结合不同的方法。同样重要的是要意识到,在许多领域(例如欺诈检测、实时投标)中,类别不平衡,“市场规则”在不断变化。因此,请检查过去的数据是否可能已经过时。
感谢阅读。你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
[1] arxiv.org/pdf/1106.1813.pdf
原文作者:Ye Wu & Rick Radewagen
翻译作者:Chuang Zhang
美工编辑:过儿
校对审稿:过儿
原文链接:https://www.kdnuggets.com/2017/06/7-techniques-handle-imbalanced-data.html





