
数据科学领导者指南:确保每个项目创造商业价值
大多数数据科学家自然会倾向于数据科学中有趣的部分——开发一个技术上先进且复杂的机器学习模型。然而,许多数据科学经理过度关注模型的技术设计,却没有花足够的时间深入理解模型所要解决的业务问题。结果是,尽管项目在技术上取得了成功,但却未能实现预期的业务价值,最终被遗弃在我称之为“数据科学墓地”的地方。作为一个管理大团队的数据科学经理,我埋葬了比我愿意承认的更多项目。然而,这些经历让我学到了许多宝贵的教训,帮助我确保数据科学项目能够真正创造业务价值。在本文中,我将分享四个重要的经验教训,数据科学经理可以利用这些经验来确保项目能够带来明确且有意义的业务影响。如果你想了解更多关于数据科学的相关内容,可以阅读以下这些文章:
所有数据科学家都应该知道的三个常见假设检验
如何开始自己的第一个数据科学项目?
导航数据驱动时代:为什么你需要掌握数据科学基础
数据科学家常见的13个统计错误,你有过吗?
教训一:将项目与公司的业务目标对齐
几乎所有公司都会定期制定和分享战略目标与任务。一个典型的目标可能是“在某个日期前将客户留存率提高X%”。这些目标和任务代表了公司的运营指南针,它们清晰地优先排序了不同的业务领域,并帮助员工判断哪些工作是重要的,哪些不是。因此,团队开展的每一个数据科学项目都应该直接关联到某个具体的业务目标或任务。
实践中的对齐方式
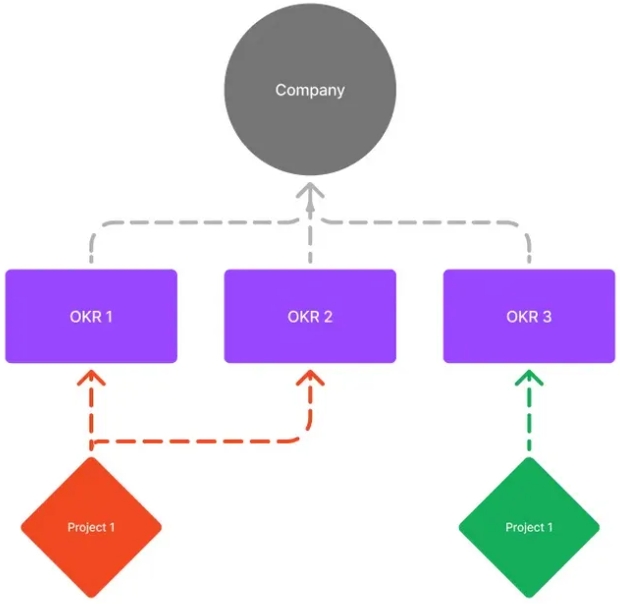
在我的团队中,我们实施了一个确保项目与公司战略优先事项紧密关联的流程。在每个项目周期开始时,团队会一起审查我们现有的任务清单,列出可以利用现有工具和数据完成的工作。我们对这个清单进行两轮筛选——第一轮专注于哪些项目可能对某个具体的公司目标或任务产生影响,第二轮则专注于量化这些项目可能创造的业务价值。通过这一流程,我们有效地优先排列了待办事项清单,确保最具影响力的项目位于清单顶部,而影响较小的项目则排在最后。
这个流程不到一个小时,却能确保团队将时间投入到最有可能为公司目标和利益带来重要价值的项目中。此外,这个流程还帮助提升了团队对公司自上而下传达的目标和任务的理解。这种加深的理解增强了团队在项目过程中做出正确决策的能力,确保我们不会不必要地牺牲业务价值。
教训二:与利益相关者保持有效互动与合作
有效的利益相关者参与对于确保数据科学项目被良好接受并产生影响至关重要。如果没有持续、定期且有效的沟通,数据科学项目最终将偏离其旨在创造的业务价值。因此,经理在弥合数据科学团队与业务部门之间的差距、促进沟通并确保双方保持一致方面扮演着关键角色。
实践中的利益相关者参与
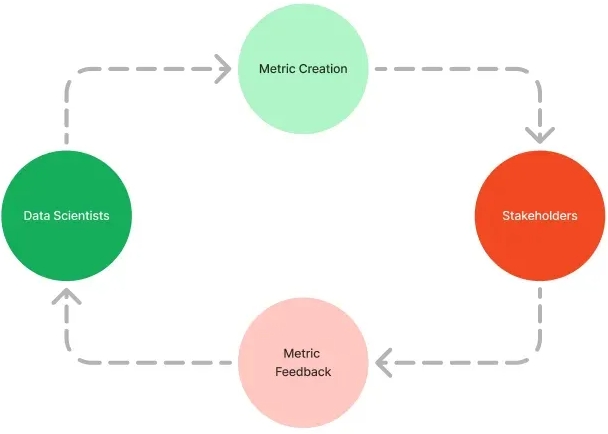
在我目前的工作中,我并没有严格遵循某个利益相关者参与流程。然而,我总结了有效管理利益相关者的四个关键要素:
- 尽早识别利益相关者:数据科学项目通常是更大产品更新或举措的一部分,项目成果可能会影响多个团队——无论是工程团队、产品团队,还是某个专门的业务部门。确保在项目初期就考虑到所有相关利益相关者的观点,有助于开发出适用于问题陈述的解决方案,并创造真正的业务价值。
- 达成成功标准的共识:作为经理,你可以帮助利益相关者了解模型在开发过程中将如何被评估。此外,你还可以帮助他们理解评估模型的指标如何与项目目标和公司目标挂钩。确保所有利益相关者对成功的定义有清晰的理解,这样一旦模型上线,衡量和分享成果的过程就会更加顺畅。达成共识应该是一个合作的过程,通常情况下,利益相关者会帮助数据科学家优化他们的成功指标,使其更好地衡量模型对业务的影响。
- 定期检查:根据我的经验,数据科学家有时会忽视在技术开发过程中与利益相关者的互动,往往只在确认问题陈述或分享最终模型结果时与他们沟通。然而,利益相关者在数据准备、特征工程和结果评估等阶段都可以提供宝贵的见解。不要犹豫,像与数据科学团队合作一样,与利益相关者合作。
- 接受反馈:毫无疑问,在你与利益相关者分享更新和进展时,他们会提出很多意见。很容易将他们的意见视为对技术的不了解或缺乏数据科学经验。然而,实际上,这些利益相关者通常代表着模型最终用户的观点。如果你希望你的模型能够真正为业务带来价值,请认真倾听这些不同利益相关者的意见!
教训三:通过明确的指标衡量成功
为了确保数据科学项目能够产生真正的业务价值,必须建立明确的成功指标。没有明确的成功指标,即使是技术上最为先进的模型也可能变得无关紧要、未被充分利用,或者无法推动预期的结果。
实践中的明确指标设定
在我的职业生涯早期,我经常为如何定义成功指标而苦恼。我很难在复杂的损失函数和我们试图创造的业务价值之间建立联系。因此,我想分享一些我在定义成功指标时常常遇到的陷阱,并讨论如何在实践中避免这些陷阱。
- 过度关注技术指标:模型训练过程中,人们往往会倾向于关注准确率或F1分数等技术指标。这些指标对于数据科学家构建强大的模型至关重要,但不应单独使用。例如,如果项目的目标是提高客户留存率,那么即使模型的准确率再高,如果上线后客户留存率没有变化,该模型在实践中也可能毫无用处。因此,在为项目定义成功指标时,确保这些指标既涵盖技术性能,也能反映模型对关键绩效指标的影响,以捕捉你希望创造的业务价值。
- 忽略利益相关者反馈:正如我之前提到的,利益相关者经常会提供有价值的反馈,帮助优化指标,使其更好地与业务目标对齐。忽视这些反馈可能导致模型性能与其为公司创造真正价值的能力之间产生错配。因此,尽早与利益相关者合作,共同定义合适的指标,并持续与他们分享这些指标。
- 指标定义过于复杂:在我看来,越简单越好。没有必要跟踪过多的不同指标,也不需要用复杂到需要一个小团队才能理解其变化原因的方式来定义指标。我的建议是保持简洁。你的指标应该易于沟通。不要害怕只专注于一两个能够抓住你试图解决的问题本质的指标。
教训四:持续监控和验证性能
在本文开头,我们讨论了确保每个数据科学项目与公司目标对齐的重要性。然而,如果没有适当的监控,你将永远无法知道模型是否真正产生了价值。更具体地说,持续监控模型的表现与既定指标的对比,是确认你的数据科学项目按预期运行并随着时间推移持续产生价值的关键步骤。
实践中的监控
在实践中,监控工作经常被忽视。很多时候,人们容易将时间花在解决其他问题上,忽略了监控功能的建立。然而,监控其实可以很容易实现。以下是我们在当前工作中采取的一些实际步骤:
- 早期考虑监控:在制定数据科学项目计划时,监控应该始终被包括在内。在我团队承担的每个项目中,我们都会在项目计划中明确分配时间来建立监控功能。将其视为必须完成的工作,而不是可选项,这样在项目结束前就能确保它得到实施。
- 专注于已定义的成功指标:监控并不意味着报告所有模型指标。相反,监控框架应专注于已商定的成功指标,这些指标应与模型、问题陈述和公司目标有明确关联。由于这些指标应该已经与相关利益相关者共享并经过验证,因此量化模型创造的价值将非常简单。
- 自动化定期性能检查:与其手动且零星地监控模型结果,不如设置自动化系统来收集所需信息,并以所需方式组织这些监控。当我提到这一点时,很多人以为需要跨职能团队的努力来建立复杂的系统,实时监控预测结果。然而,有一些工具可以帮助实现简单版的同样功能。例如,GitHub Actions 就是一个很好的选择——只需设置一个Python脚本来获取所需数据,并使用Actions定时执行该脚本。该脚本可以将数据发送到数据库以便开发仪表板,或简单地发送到电子表格。关键是,这几乎不需要任何团队外部的支持,只需团队中的数据科学家贡献他们的部分工作即可。
通过数据科学项目实现真正的业务价值不仅仅需要技术专长。作为数据科学经理,你的职责是确保项目不仅在技术上成功,还能与公司的战略目标对齐,并持续产生可衡量的成果。在你未来的数据科学旅程中,我鼓励你将这些实践融入到你管理团队的方式中。
感谢你的阅读!感谢阅读!你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/。
原文作者:Zachary Raicik
翻译作者:过儿
美工编辑:过儿
校对审稿:Jason
原文链接:https://towardsdatascience.com/a-data-science-leaders-guide-to-ensuring-every-project-drives-business-value-ed92c6b3606c





