
Machine Learning知识点:机器学习里的聚类分析技巧
当我们听说某人是个数据分析师,或是在商业智能领域工作时,这些职业的复杂性会让我们产生一种隐约的敬畏感。然而,这些职位背后的现实情况都是立足于现实生活中的数据分析渠道。
通常,数据一开始都是非结构化、互不相关的。数据分析师的首要任务是,在进行分析之前,先弄清楚数据。
对所有称职的分析师来说,最强大的工具就是数据聚类。今天,我们会给大家简要介绍各种聚类,以及在现实中该如何使用它们。如果你想了解更多数据分析相关内容,可以阅读以下这些文章:
三个月如何搞定机器学习的数学原理?
研究了2000+笔记本,我们总结了最适合机器学习、数据科学和深度学习的电脑
评估机器学习算法的指标
聚类是什么?
聚类是一种机器学习算法,是一种常用的数据分类技术。它属于无监督机器学习算法的范畴,在处理未标记和非结构化的数据时非常有用。
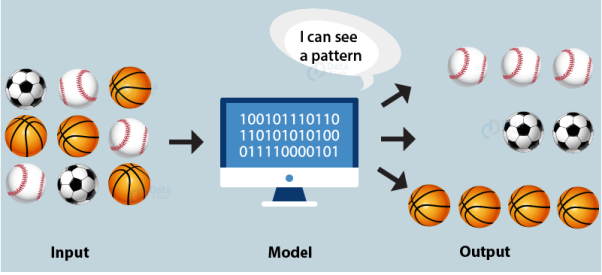
聚类是开始理解非结构化数据的好方法。
在这种算法中,我们通常只处理数据的特征,而没有任何目标标签或类。这些算法不需要人工干预就能发现隐藏的模式或数据分组。它能够发现信息中的相似性和差异性,是探索性数据分析的理想解决方案。
换句话说,聚类是一种数据挖掘技术,根据数据集的相似性或差异性进行分类。根据信息中展示出的结构或模式,它能把原始数据或未分类的数据分组。聚类算法可以分为几种类型,具体来说有排他型(exclusive)、重叠型(overlapping)、分级(hierarchical)和概率型(probabilistic)。
为什么要使用聚类?
目的是把相同属性的项分组在一起。想象一下,你有数百万种化合物,但你看不见,也无法判断它们想要表达的是什么,它们之间有什么相似之处。通过聚类,你可以将这些上百万个聚类,根据它们之间的相似性,分成5或10个聚类,这样你就可以更容易地去分析这5或10个聚类,而不是单独地看每个化合物。
聚类的类型
我们可以根据不同的规则和参数对数据进行分类。从数据值的简单相似性到数据点之间的比较关系,有许多方法可以解决这个问题。对所有聚类技术进行分类的方法如下所示:
- 1. 基于划分的聚类(Partition Based Clustering)
- 2. 分级聚类(Hierarchical Clustering)
- 3. 基于密度的聚类(Density-based Clustering)
在继续讨论实际应用之前,我们先来简要解释一下这些内容。
基于划分的聚类(Partition Based Clustering)
给定一个包含n个对象或数据元组的数据库,分区方法将划分k个数据的分区,其中每个分区代表一个集群。
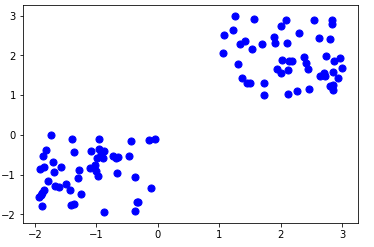
这种聚类方法根据数据的特征和相似性将信息划分为多个组。要生成的集群的确切个数是由数据分析人员指定的。
在分区方法中,当数据库(D)包含多个(N)对象时,分区方法创建用户指定的K个分区,其中每个分区代表一个集群和一个特定的区域。
分级聚类(Hierarchical Clustering)
分级聚类,也称为分级聚类分析(hierarchical cluster analysis),是一种算法,将相似的对象分组为集群组。端点是一组集群,其中每个集群与其他集群不同,每个集群中的对象大致上彼此相似。
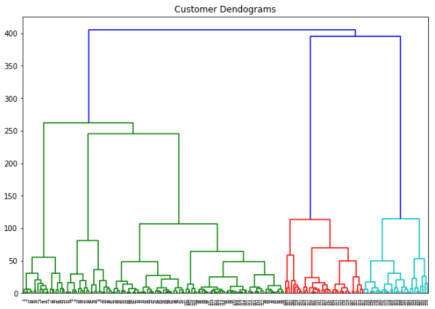
分级聚类首先将每个观察结果作为单独的集群处理。然后重复执行以下两个步骤:
- (1)识别两个最接近的集群
- (2)合并两个最相似的集群
然后一直反复持续这个过程,直到所有集群合并在一起。
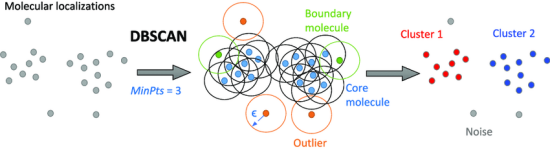
基于密度的聚类(Density-based Clustering)
DBSCAN密度聚类(Density-Based Spatial Clustering of Applications with Noise)是一种著名的数据聚类算法,通常用于数据挖掘和机器学习。DBSCAN根据距离的长短(通常是欧几里得距离)把相互距离最小的点分组在一起。它还能将在低密度区域的那些点标记为异常值。
个案研究:K-Means聚类算法(K Means Clustering Algorithm)
K-Means是一种非常受欢迎的迭代聚类算法。它的目的是将一个数据集划分为多个组,每个数据点只能属于某一个聚类,目的是在每次迭代中寻找到局部极大值。这个算法大致分为五个步骤:
步骤0:找到一个适当的方法来可视化你的数据。你可以选择任意2到3个与图表相关的特征。我们将通过分割图中所示的数据来对数据进行聚类(分区)。
步骤1:选择集群数(k) —- 集群数k =3
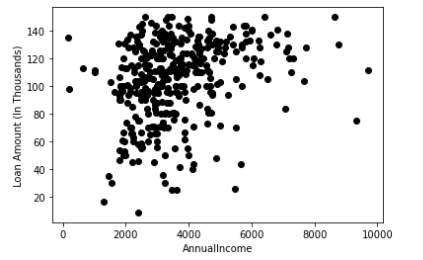
一个示例数据集,绘制了根据人们各自的收入批准给他们的贷款金额
步骤2:为每个集群选择一个随机的矩心(起始值)
步骤3:将所有点分配到它最近的聚类矩心
步骤4:不断重复,直到矩心不再变化,也就是说,将每个数据点都分配到了最近的集群
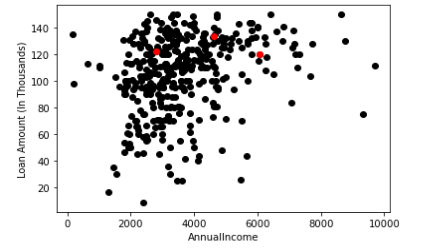
上图红色的点表示我们正在迭代的各个聚类矩心。我们选择K = 3,是因为我们假设数据能被充分地分为3类。
步骤5:重复步骤3和步骤4,直到每个K个聚类中心都得到稳定的解(K的计算改动变得足够小)。
当这个差值为0时,我们就可以停止了,然后,我们把收到的集群可视化。
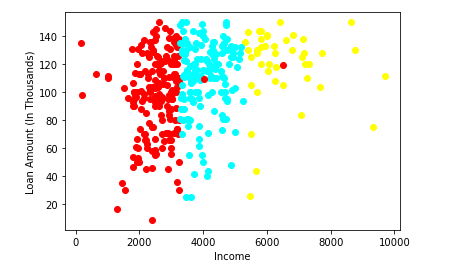
上图是每个K(=3)的位置均值的最终结果。数据点是根据这些结果被分类到的3个类别中的颜色的。
K- means聚类算法在概念上是非常简练的,我们在所有问题中对K的决定都会影响这种方法对数据进行分类的方式。
应用
接下来,我们来看看在集群和其他技术协同工作下,帮助改善日常生活的一些有效方式。
1. 识别假新闻
假新闻并不是一种新的现象,但是在我们这个时代却变得越来越多。
问题在于:由于社交媒体等技术创新,假新闻得以快速产生和传播,这个问题在2016年美国总统竞选期间受到了强烈关注。在这次竞选中,“假新闻”这一词被引用的次数前所未有。
聚类的作用:获取假新闻文章的内容,语料库,检查所使用的词,然后对它们进行聚类。这些聚类有助于算法判断哪些新闻是真实的,哪些是假的。某些词汇通常出现在耸人听闻的标题式文章中。如果你在一篇文章中看到高比例的特定词汇时,这篇文章就很有可能是假新闻。
2. 识别欺诈或犯罪活动
在这个场景中,我们将重点关注出租车司机的欺诈行为。当然,该技术还被用于多个其他场景。
问题在于:你需要调查欺诈驾驶行为。你面临的挑战是,如何辨别哪些是真的,哪些是假的?
聚类的作用:通过分析GPS记录,算法能够对相似的行为进行分组。根据这些群体的特征,你就可以把他们分成真实的和欺诈的两类。
3.市场营销和销售
在市场营销中,个性化和定向投放是一项大业务。
这是通过观察一个人的具体特征,并与他们分享和他们类似的人取得反馈的活动来实现的。
问题在于:如果你是一家试图从营销投资中获得最佳回报的企业,你就必须以正确的方式瞄准目标用户。如果你做错了,就有可能进行不了任何推广,或者导致更坏的结果,损害客户的信任度。
聚类的作用:聚类算法能够将具有相似特征和购买可能的人聚在一起。一旦你有了这些分组,你就可以用不同的营销计划在每个组运行测试,有助于你以后更好地向他们传递信息。
聚类技术的世界是广阔的,我们也会在以后的文章逐步探索有效的方法。感谢你的阅读!你还可以订阅我们的YouTube频道,观看大量数据科学相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Aparna Singh
翻译作者:过儿
美工编辑:过儿
校对审稿:Jiawei Tong
原文链接:https://medium.com/develearn/an-introduction-to-clustering-techniques-feef8378c25d





