
用数据科学技术,分析用户产品倾向
在所有商业营销策略中,公司的首要任务始终是为产品吸引正确的受众群体,从而提高销售额、降低营销费用。
本文的数据集用于分析公司理想客户,了解在财务方面对公司产品和服务采取何种行动:https://www.kaggle.com/imakash3011/customer-personality-analysis
如果你想了解更多数据分析相关内容,可以阅读以下这些文章:
数据分析师需要知道的10个Excel函数
新兴报表工具FineReport——商业分析师需要知道的三种报表
数字营销是怎样通过数据分析赚钱的?
三个必备高级分析方法,了解你的客户
为此,今天我将讨论分析数据组的方法,以实现我们的目标,即吸引正确的受众群体。
我们一步一步,实现深入了解
- 1. 导入我们想要使用的库
- 2. 数据设计
- 3. 导入数据集
- 4. 数据清洗
导入我们想要使用的库
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt数据设计
我们的数据集由 29 列、 2240 行的属性组成。
数据属性可以分为以下几类:
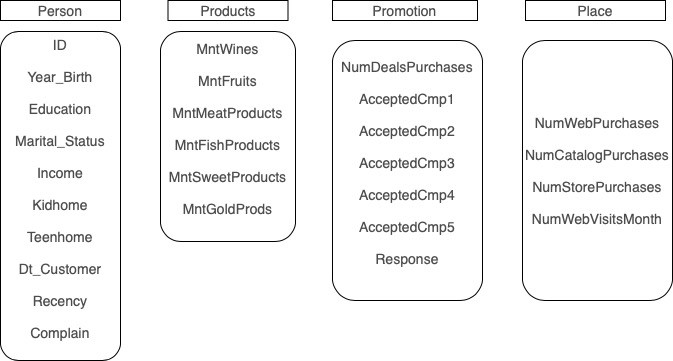
在这篇文章中,我们将把重点放在这 5 个主要因素:
- Education:客户的教育程度
- Marital_Status:客户的婚姻状况
- Income:客户的家庭年收入
- Dt_Customer:客户在公司注册的日期
- MntWines:过去两年在红酒上的消费金额
目标
主要目标是将集群应用至获取某些产品的客户行为。
导入数据集
all_data = pd.read_csv("../input/customer-personality-analysis/marketing_campaign.csv", sep="\t")数据清洗
查看数据信息
all_data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 2240 entries, 0 to 2239
Data columns (total 29 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 ID 2240 non-null int64
1 Year_Birth 2240 non-null int64
2 Education 2240 non-null object
3 Marital_Status 2240 non-null object
4 Income 2216 non-null float64
5 Kidhome 2240 non-null int64
6 Teenhome 2240 non-null int64
7 Dt_Customer 2240 non-null object
8 Recency 2240 non-null int64
9 MntWines 2240 non-null int64
10 MntFruits 2240 non-null int64
11 MntMeatProducts 2240 non-null int64
12 MntFishProducts 2240 non-null int64
13 MntSweetProducts 2240 non-null int64
14 MntGoldProds 2240 non-null int64
15 NumDealsPurchases 2240 non-null int64
16 NumWebPurchases 2240 non-null int64
17 NumCatalogPurchases 2240 non-null int64
18 NumStorePurchases 2240 non-null int64
19 NumWebVisitsMonth 2240 non-null int64
20 AcceptedCmp3 2240 non-null int64
21 AcceptedCmp4 2240 non-null int64
22 AcceptedCmp5 2240 non-null int64
23 AcceptedCmp1 2240 non-null int64
24 AcceptedCmp2 2240 non-null int64
25 Complain 2240 non-null int64
26 Z_CostContact 2240 non-null int64
27 Z_Revenue 2240 non-null int64
28 Response 2240 non-null int64
dtypes: float64(1), int64(25), object(3)
memory usage: 507.6+ KB检查 NuLL 值,并删除这些值
all_data = all_data.dropna()
all_data.info()<class 'pandas.core.frame.DataFrame'>
Int64Index: 2216 entries, 0 to 2239
Data columns (total 29 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 ID 2216 non-null int64
1 Year_Birth 2216 non-null int64
2 Education 2216 non-null object
3 Marital_Status 2216 non-null object
4 Income 2216 non-null float64
5 Kidhome 2216 non-null int64
6 Teenhome 2216 non-null int64
7 Dt_Customer 2216 non-null object
8 Recency 2216 non-null int64
9 MntWines 2216 non-null int64
10 MntFruits 2216 non-null int64
11 MntMeatProducts 2216 non-null int64
12 MntFishProducts 2216 non-null int64
13 MntSweetProducts 2216 non-null int64
14 MntGoldProds 2216 non-null int64
15 NumDealsPurchases 2216 non-null int64
16 NumWebPurchases 2216 non-null int64
17 NumCatalogPurchases 2216 non-null int64
18 NumStorePurchases 2216 non-null int64
19 NumWebVisitsMonth 2216 non-null int64
20 AcceptedCmp3 2216 non-null int64
21 AcceptedCmp4 2216 non-null int64
22 AcceptedCmp5 2216 non-null int64
23 AcceptedCmp1 2216 non-null int64
24 AcceptedCmp2 2216 non-null int64
25 Complain 2216 non-null int64
26 Z_CostContact 2216 non-null int64
27 Z_Revenue 2216 non-null int64
28 Response 2216 non-null int64
dtypes: float64(1), int64(25), object(3)
memory usage: 519.4+ KB正如我们所见,在删除 NaN 后,我们得到了 2216 个条目,而不是最开始的 2240 个条目
但是,有些值和它的数据类型不兼容,例如:
- 1. Education,即分类数据,其数据类型为对象。
- 2. Dt_Customer 必须是 DateTime 字段。
重命名列为更直观的名称
all_data = all_data.rename(columns={
'MntWines': 'Amount_Wines',
'MntFruits': 'Amount_Fruits',
'MntMeatProducts': 'Amount_Meat',
'MntFishProducts': 'Amount_Fish',
'MntSweetProducts': 'Amount_Sweet',
'MntGoldProds': 'Amount_Gold'
})解析客户在公司注册的日期 (Dt_Customer)
all_data['Dt_Customer'] = pd.to_datetime(all_data['Dt_Customer'])目前,Dt_Customer 的数据类型为 DateTime
7 Dt_Customer 2216 non-null datetime64[ns]将数据转换为更简单的类别
例如,如果我们查看 Education 字段值,我们将查看可以轻松将数据分为 3 大类的人员:
- Basic 和 2n Cycle 被视为一类(本科生)。
- 毕业被视为一类(毕业生)。
- 硕士和博士被视为一类(研究生)。
all_data['Education'].value_counts()
Graduation 1116
PhD 481
Master 365
2n Cycle 200
Basic 54
Name: Education, dtype: int64更改之后,我们可以轻松将其应用其中:
all_data["Education"]=all_data["Education"].map({
"Basic" : "Undergraduate",
"2n Cycle" : "Undergraduate",
"Graduation" : "Graduate",
"Master" : "Postgraduate",
"PhD" : "Postgraduate"
})
all_data['Education'].value_counts()
Graduate 1116
Postgraduate 846
Undergraduate 254
Name: Education, dtype: int64找到每个客户的注册天数
all_data['Enrolled_Time'] = '01-01-2015' #assuming we are starting counting from the new year
all_data['Enrolled_Time'] = pd.to_datetime(all_data.Enrolled_Time)
all_data['Enrolled_Days_Amount'] = (all_data['Enrolled_Time'] - all_data['Dt_Customer']).dt.days我们可以做一些绘图
plt.figure(figsize=(20, 7)) #width:20, height:7
plt.bar(all_data['Year_Birth'], all_data['Enrolled_Days_Amount'], color ='purple',
width = 0.8)
plt.xlabel("Year of Birth")
plt.ylabel("Number of Enrolled Days")
plt.show()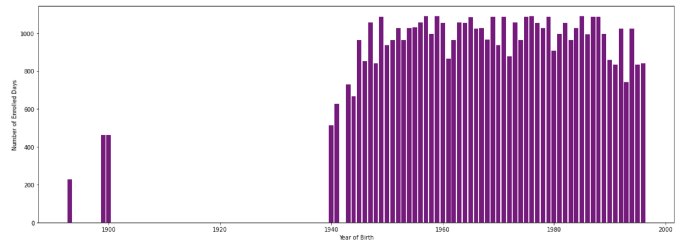
标准化数据
这一步将帮助我们消除对具有较高值的较高字段与较小字段的偏差,因此我会标准化数据,重新缩放数据的概念,使其均值为 0,标准差为 1(单位方差)。
for i in all_data.select_dtypes(exclude='object').columns:
all_data.loc[:, i] = StandardScaler().fit_transform(np.array(all_data[[i]]))把数据建模成不同的集群
选择集群数量
#taking into consideration the (income) and (amount of wine)
X=all_data.iloc[:, np.array([4, 9])].values
wcss=[]
for i in range(1,11):
kmeans = KMeans(n_clusters=i, init ='k-means++', max_iter=300, n_init=10,random_state=0 )
kmeans.fit(X)
wcss.append(kmeans.inertia_)
plt.plot(range(1,11),wcss)
plt.title('The Elbow Method Graph')
plt.xlabel('Number of clusters')
plt.ylabel('WCSS')
plt.show()
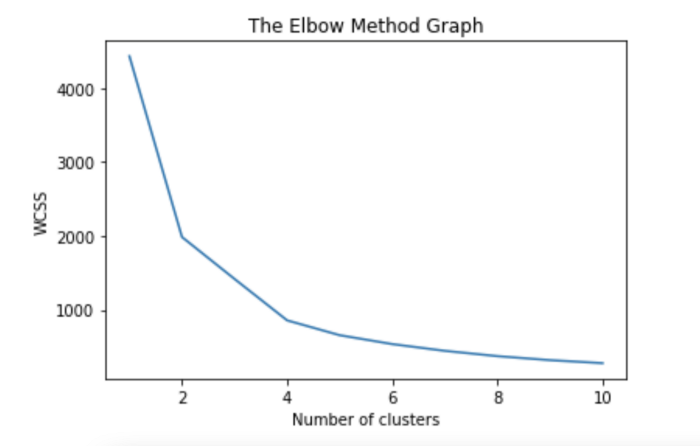
#we will take 5 clusters
kmeans = KMeans(n_clusters=5, init =’k-means++’, max_iter=300, n_init=10, random_state=0 )
y_kmeans = kmeans.fit_predict(X)
plt.scatter(X[y_kmeans==0, 0], X[y_kmeans==0, 1], s=2, c='red', label ='Cluster 1')
plt.scatter(X[y_kmeans==1, 0], X[y_kmeans==1, 1], s=2, c='blue', label ='Cluster 2')
plt.scatter(X[y_kmeans==2, 0], X[y_kmeans==2, 1], s=2, c='green', label ='Cluster 3')
plt.scatter(X[y_kmeans==3, 0], X[y_kmeans==3, 1], s=2, c='cyan', label ='Cluster 4')
plt.scatter(X[y_kmeans==4, 0], X[y_kmeans==4, 1], s=2, c='magenta', label ='Cluster 5')
plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], s=100, c=’yellow’, label = ‘Centroids’)
plt.title(‘Clusters of Customers’)
plt.xlabel(‘Income’)
plt.ylabel(‘Amount of Wine’)
plt.show()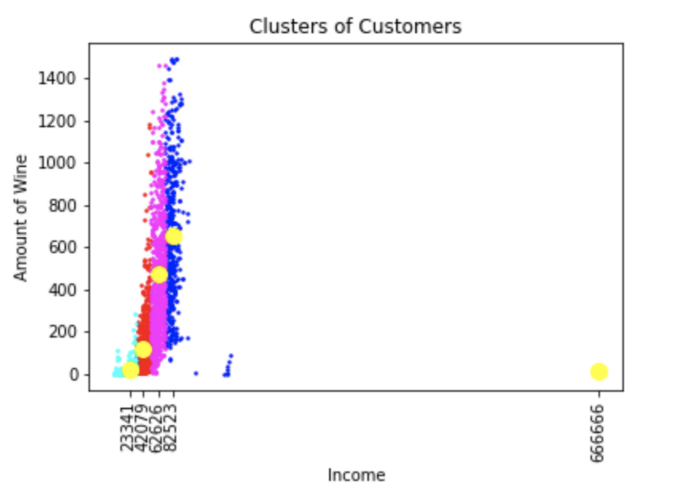
黄点是每个集群的质心
最后,我们可以从以上用例中得出一个结论,随着客户收入的增加,在红酒上的支出也会增加,除了有些异常值(例如收入为 666666 的人)。这部分人的收入更高,同时支出也更高。
感谢您的阅读,让我们一起进步!你还可以订阅我们的YouTube频道,观看大量数据科学相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Amjad EI Baba
翻译作者:Lia
美工编辑:过儿
校对审稿:Jiawei Tong
原文链接:https://medium.com/@amjad.baba913/applying-data-analysis-regarding-customers-personality-53ffabd338eb





