
使用Amazon Bedrock和LangChain构建一个QA研究聊天机器人
不久前,我尝试构建一个简单的自定义聊天机器人,该机器人完全在我的 CPU 上运行。
结果令人震惊,应用程序经常崩溃。话虽如此,但这并不是一个令人震惊的结果。事实证明,在一台价值 600 美元的计算机上安装一个 13B 参数模型的编程效果就好比让一个蹒跚学步的幼儿爬山一样困难。
这一次,我尝试构建一个研究聊天机器人,通过端到端的项目使用AWS来托管和提供构建应用程序所需的模型。
本文详细介绍了我利用 RAG 构建高性能研究聊天机器人的努力,该机器人利用研究论文中的信息回答问题。如果你想了解更多关于聊天机器人的相关内容,可以阅读以下这些文章:
新的聊天机器人ChatGPT擅长和不擅长的
在新研究的支持下,从ChatGPT获得深入响应的9种技巧
ChatGPT又蠢又没用?请提出正确的问题!
ChatGPT很累,可能正在计划度假(不是开玩笑)
目标
该项目的目标是使用 RAG 框架构建一个 QA 聊天机器人。它将使用arXIV存储库上提供的 pdf 文档中的内容来回答问题。
在深入研究该项目之前,让我们先考虑一下架构、技术堆栈以及构建聊天机器人的过程。
聊天机器人架构
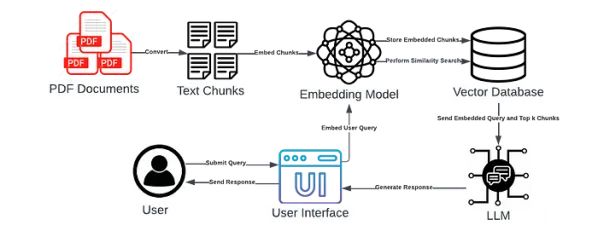
上图说明了 LLM 申请的工作流程。
当用户在用户界面上提交查询时,查询将使用嵌入模型进行转换。然后,向量数据库将检索最相似的嵌入,并将它们与嵌入的查询一起发送给LLM。LLM将使用提供的上下文生成准确的响应,然后将其显示在用户界面上。
技术堆栈
使用架构中显示的组件构建RAG应用程序将需要几种工具。值得注意的工具如下:
1. Amazon Bedrock
Amazon Bedrock是一个无服务器服务,允许用户通过API访问模型。由于它采用按需付费制度,并按使用的代币数量收费,因此对于开发者来说非常方便且具有成本效益。
Bedrock将用于访问嵌入模型和LLM。在配置方面,使用Bedrock将需要创建一个具有访问该服务权限的IAM用户。此外,必须提前授予对感兴趣的模型的访问权限。
2. FAISS
FAISS是数据科学领域的一个流行库,将用于创建该项目的矢量数据库。它可以根据相似性度量快速有效地检索相关文档。它是免费的,这也是非常有用的。
3. LangChain
LangChain框架将有助于创建和使用RAG组件(例如向量存储、LLM)
4. Chainlit
Chainlit库将用于开发聊天机器人的用户界面。它可以使用户用最少的代码构建美观的前端,并提供适用于聊天机器人应用程序的功能。
注意:本文的技术部分将包括 Chainlit 操作的代码片段,但不会涵盖这些操作的语法或功能
5. Docker
为了可移植性和易于部署,应用程序将使用 Docker 进行容器化。
流程
开发LLM应用程序将需要以下步骤。每个步骤都将单独探讨。
- 加载 PDF 文档
- 构建矢量存储
- 创建检索链
- 设计用户界面
- 运行聊天机器人应用程序
- 在 Docker 容器中运行应用程序
第1步 — 加载 PDF 文档

ArXIV是一个存储大量免费开源文章和论文的知识库,涵盖从经济学到工程学等各种主题。应用程序的后端数据将包括来自该知识库的几篇有关LLM的文档。
一旦选择的文档被存储在一个目录中,它们将被加载并使用LangChain的PyPDFDirectoryLoader和RecursiveCharacterTextSplitter转换为文本块。
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import PyPDFDirectoryLoader
def load_pdfs(chunk_size=3000, chunk_overlap=100):
# load the pdf documents
loader=PyPDFDirectoryLoader("PDF Documents")
documents=loader.load()
# split the documents into chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size,
chunk_overlap=chunk_overlap)
docs = text_splitter.split_documents(documents=documents)
return docs第2步 — 构建矢量存储
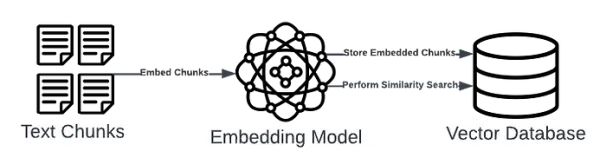
在第一步中创建的文本块将使用亚马逊的Titan Text Embeddings模型进行嵌入。可以通过使用boto3(适用于 Python 的 Amazon SDK)的代码来访问这些模型。Titan模型可以通过Bedrock文档中提供的model_id来识别。
from langchain_community.embeddings import BedrockEmbeddings
from langchain_community.vectorstores.faiss import FAISS
def create_vector_store(docs):
# Set up bedrock client
bedrock = create_client()
bedrock_embeddings=BedrockEmbeddings(model_id='amazon.titan-embed-text-v1', client=bedrock)
# create and save the vector store
vector_store = FAISS.from_documents(docs, bedrock_embeddings)
vector_store.save_local("faiss_index")
return None嵌入的块存储在 FAISS 矢量存储中,该存储在本地保存为“faiss_index”。
第3步 – 加载 LLM

应用程序的LLM将是Meta的13B Llama 2模型。与嵌入模型类似,LLM可以通过亚马逊Bedrock访问。
from langchain_community.embeddings import BedrockEmbeddings
from langchain_community.vectorstores.faiss import FAISS
def create_vector_store(docs):
# Set up bedrock client
bedrock = create_client()
bedrock_embeddings=BedrockEmbeddings(model_id='amazon.titan-embed-text-v1', client=bedrock)
# create and save the vector store
vector_store = FAISS.from_documents(docs, bedrock_embeddings)
vector_store.save_local("faiss_index")
return None一个值得注意的参数是温度,它会影响模型输出的随机性。由于该应用程序设计用于研究,为了将随机性降至最低,将温度设置为0。
第4步 – 创建检索链
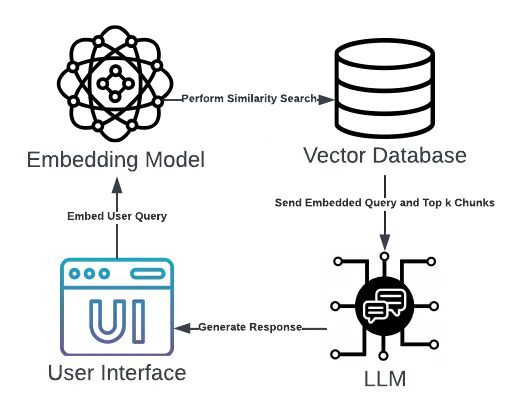
在LangChain中,“chain”是一个包装器,它以特定的顺序促进一系列事件。在此 RAG 应用程序中,链将接收用户查询并从向量存储中检索最相似的块。然后,该链会将嵌入的查询和检索到的块发送到加载的 LLM,后者将使用提供的上下文生成响应。
from langchain.llms.bedrock import Bedrock
from langchain.memory import ChatMessageHistory, ConversationBufferMemory
from langchain.chains import RetrievalQA, ConversationalRetrievalChain
# load llm
llm = create_llm(bedrock_client=bedrock_client)
# load embeddings and vector store
bedrock_embeddings=BedrockEmbeddings(model_id='amazon.titan-embed-text-v1', client=bedrock_client)
vector_store = FAISS.load_local('faiss_index', bedrock_embeddings, allow_dangerous_deserialization=True)
# create memory history
message_history = ChatMessageHistory()
memory = ConversationBufferMemory(
memory_key="chat_history",
output_key="answer",
chat_memory=message_history,
return_messages=True,
)
# create qa chain
qa_chain = ConversationalRetrievalChain.from_llm(llm,
chain_type='stuff',
retriever=vector_store.as_retriever(search_type='similarity', search_kwargs={"k":3}),
return_source_documents=True,
memory=memory)该链还包含ConversationBufferMemory,它允许聊天机器人保留先前查询的内存。这使得用户能够提出后续问题。
另一个值得注意的是检索器的超参数k,它指定应从向量存储中获取的嵌入数量。对于此用例,我们将k设置为3,这意味着LLM应用程序将使用3个嵌入来为每个查询提供上下文。
第 5 步 — 构建用户界面
到目前为止,应用程序的后端组件已经开发完成,接下来是前端的工作了。 Chainlit 可以轻松地为 LangChain 应用程序构建用户界面,因为现有代码只需要使用额外的 chainlit 命令进行修改。
Chainlit用于创建建立链的函数。
import chainlit as cl
@cl.on_chat_start
async def create_qa_chain():
# create client
bedrock_client = create_client()
# load llm
llm = create_llm(bedrock_client=bedrock_client)
# load embeddings and vector store
bedrock_embeddings=BedrockEmbeddings(model_id='amazon.titan-embed-text-v1', client=bedrock_client)
vector_store = FAISS.load_local('faiss_index', bedrock_embeddings, allow_dangerous_deserialization=True)
# create memory history
message_history = ChatMessageHistory()
memory = ConversationBufferMemory(
memory_key="chat_history",
output_key="answer",
chat_memory=message_history,
return_messages=True,
)
# create qa chain
qa_chain = ConversationalRetrievalChain.from_llm(llm,
chain_type='stuff',
retriever=vector_store.as_retriever(search_type='similarity', search_kwargs={"k":3}),
return_source_documents=True,
memory=memory
)
# add custom messages to the user interface
msg = cl.Message(content="Loading the bot...")
await msg.send()
msg.content = "Hi, Welcome to the QA Chatbot! Please ask your question."
await msg.update()
cl.user_session.set('qa_chain' ,qa_chain)它还用于创建使用链来生成响应并将其发送给用户的函数。
import chainlit as cl
@cl.on_message
async def generate_response(query):
qa_chain = cl.user_session.get('qa_chain')
res = await qa_chain.acall(query.content, callbacks=[cl.AsyncLangchainCallbackHandler(
stream_final_answer=True,
)])
# extract results and source documents
result, source_documents = res['answer'], res['source_documents']
# Extract all values associated with the 'metadata' key
source_documents = str(source_documents)
metadata_values = re.findall(r"metadata={'source': '([^']*)', 'page': (\d+)}", source_documents)
# Convert metadata_values into a single string
pattern = r'PDF Documents|\\'
metadata_string = "\n".join([f"Source: {re.sub(pattern, '', source)}, page: {page}" for source, page in metadata_values])
# add metadata (i.e., sources) to the results
result += f'\n\n{metadata_string}'
# send the generated response to the user
await cl.Message(content=result).send()Chainlit的装饰器是必要的部分。on_chat_start装饰器定义了在聊天会话开始时应该运行的操作(即设置链),而on_message装饰器定义了在用户提交查询时应该运行的操作(即发送响应)。
此外,代码中还使用了async和await命令,以便任务被异步处理。
最后,由于LLM应用程序是为研究而设计的,生成的响应将包含从向量存储中检索的嵌入的来源。这使得生成的响应可引用,并因此在用户眼中更加可信。
第 6 步 — 运行聊天机器人应用程序
所有聊天机器人工作流程的组件都已创建,可以运行和测试应用程序。使用Chainlit,可以通过简单的一行代码启动会话:
chainlit run <app.py>
聊天机器人现在已经启动运行!它在会话开始时显示了代码中提供的消息。
让我们用一个简单的查询来测试一下:

提交查询时,响应既简洁又易于理解。此外,它还包括用于生成响应的 3 个向量嵌入的来源,包括文档名称和页码。
为了确保聊天机器人保留先前查询的记忆,我们可以提交一个跟进查询。

在这里,我们要求提供“另一个示例”,但不提供有关所需示例的附加信息。由于机器人会保留内存,因此它知道查询引用的是预训练的 LLM。
总体而言,该应用程序的性能令人满意。无法在文章中展示的一个方面是运行聊天机器人所需的计算需求显着降低。由于 AWS 拥有嵌入模型和 LLM,因此不存在因 CPU 使用率过高而导致崩溃的风险。
第 7 步 – 将应用程序容器化
尽管聊天机器人已启动并运行,但还剩下一步。 LLM 应用程序仍然需要使用 Docker 进行容器化,以便更轻松地进行移植和版本控制。
容器化的第一步是开发 DockerFile。
# Use the official Python image as base
FROM python:3.9.13
# Set the AWS_DEFAULT_REGION environment variable
ENV AWS_DEFAULT_REGION=us-east-1
# Define build arguments for access key and secret access key
ARG AWS_ACCESS_KEY_ID
ARG AWS_SECRET_ACCESS_KEY
# Set the AWS credentials environment variables
ENV AWS_ACCESS_KEY_ID=$AWS_ACCESS_KEY_ID
ENV AWS_SECRET_ACCESS_KEY=$AWS_SECRET_ACCESS_KEY
# Set the working directory inside the container
WORKDIR /app
# upgrade pip and install poetry
RUN pip install --user --no-cache-dir --upgrade pip && \
pip install --user --no-cache-dir poetry==1.4.2
# Copy the requirements file into the container at /app
COPY requirements.txt .
# Install all dependencies specified in requirements.txt
RUN pip install --no-cache-dir -r requirements.txt
# Copy the current directory contents into the container at /app
COPY . .
# expose port 8000
EXPOSE 8000
# Command to run the application
CMD ["chainlit", "run", "app.py"]在这个Dockerfile中,我们以Python镜像为基础,定义了从AWS获取访问密钥ID和密钥访问密钥的参数,在容器中安装requirements.txt文件,将当前目录复制到容器中,并运行chainlit应用程序。
从这里开始,一切都很简单。构建docker镜像只需要一行命令:
docker build --build-arg AWS_ACCESS_KEY_ID=<your_access_key_id> --build-arg AWS_SECRET_ACCESS_KEY=<your_secret_access_key> -t chainlit_app .上面的命令构建了一个名为 chainlit_app 的图像。它包含 AWS 访问密钥 ID 和 AWS 密钥作为参数,因为它们需要通过 API 访问 Amazon Bedrock 中的模型。
最后,应用程序可以在 Docker 容器中运行:
docker run -d --name chainlit_app -p 8000:8000 chainlit_app 
该应用程序现在正在端口 8000 上运行!由于应用程序在本地运行,因此聊天机器人将托管在http://localhost:8000上。
让我们通过提交查询来看看 RAG 组件(包括 AWS Bedrock 模型)是否仍然可以运行。
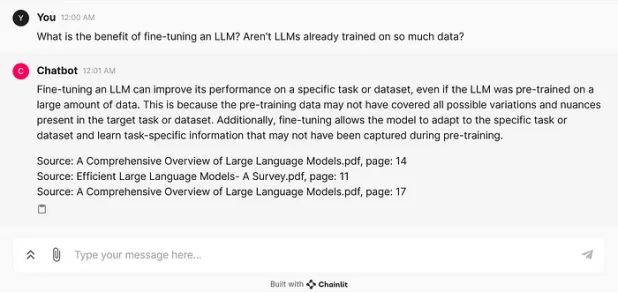
它的工作原理正如预期的那样!
未来步骤
当前的聊天机器人能够以较低的成本和较高的性能响应查询。然而,该应用程序仍在本地运行,并使用默认参数。因此,仍然可以采取措施进一步提升聊天机器人的性能和可用性。
1. 执行严格的测试
LLM 应用程序似乎效果良好,响应简明准确。然而,该工具仍需要经过严格的测试才能被认为可用。
测试主要是为了确保最大限度地提高反应准确性,同时最大限度地减少误差。
2. 实施高级RAG技术
如果聊天机器人无法回答特定类型的问题或始终表现不佳,则值得考虑使用先进的 RAG 技术来改进工作流程的某些方面,例如从矢量数据库中检索内容。
3. 完善前端
目前,该工具使用 Chainlit 提供的默认前端。为了使工具更美观、直观,可以进一步自定义 UI 设计。
此外,还可以通过提供超链接来改进聊天机器人的引用功能(即识别响应的来源),以便用户可以立即转到包含他们所需信息的页面。
4. 部署到云端
如果需要向更大的用户群提供此应用程序,下一步将是将具有 Amazon EC2 和 Amazon ECS 等服务的云平台将其部署在远程服务器中。从而使许多云平台实现高可扩展性、可用性和性能,由于该工具利用了 AWS Bedrock,所以优先利用 AWS 旗下的其他资源。
结论
在从事这个项目时,我对数据科学领域的进步感到震惊。仅仅在 5 年前,利用生成式人工智能的 NLP 应用程序还很难构建,因为它需要大量的时间、金钱和人力。
到了2024年,只需一个人、一点代码和最少的费用就可以构建这样的工具(到目前为止,整个项目的成本不到1美元)就能构建出来。这让人不禁思考未来几年可能会发生什么。
对于对该项目的代码库更感兴趣的人,请访问 GitHub 存储库:
anair123/使用 AWS 和 Llama-2 构建研究聊天机器人 (github.com)(https://github.com/anair123/Building-a-Research-Chatbot-with-AWS-and-Llama-2)
非常感谢你的阅读!
参考资料:
Stehle, J., Eusebius, N., Khanuja, M., Roy, M., & Pathak, R. (n.d.). Getting started with Amazon Titan text embeddings in Amazon bedrock … https://aws.amazon.com/blogs/machine-learning/getting-started-with-amazon-titan-text-embeddings/
感谢阅读!你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Aashish Nrai
翻译作者:诗彤
美工编辑:过儿
校对审稿:Jason
原文链接:https://towardsdatascience.com/building-a-qa-research-chatbot-with-amazon-bedrock-and-langchain-677fbd19e3c1





