
DataJob入门 — 在 AWS 上构建和部署无服务器数据管道
数据工程师的核心工作包括了构建、部署、运行和监控数据管道。
但在数据和 ML 工程领域工作时,缺少一种工具,用于简化在 AWS 服务(如 Glue 和 Sagemaker)上部署数据管道过程,以及轻松通过 Step Functions 编排数据管道步骤。所以, DataJob诞生了!
在本文中,我将向你演示如何安装 DataJob,通过简单示例给予指导,展示 DataJob 的某些功能。如果你想了解更多数据分析相关内容,可以阅读以下这些文章:
使用Amazon SageMaker和AWS Lambda进行无服务器管道自动化模型训练和部署
DS vs DE:数据科学家与数据工程师的薪资对比
Airflow 101: 隐藏小技巧帮你快速上手!
Amazon商业分析师面试指南
安装DataJob
你可以在 PyPI 中安装 DataJob。DataJob 通过 AWS CDK 配置 AWS 服务,所以一定要安装此服务。如果你想动手实践本文的这个示例,你需要一个 AWS 账户 。
pip install --upgrade pip
pip install datajob
# take latest of v1, there is no support for v2 yet
npm install -g aws-cdk@1.134.0一个简单的示例
该工具包含一个简单的数据管道,由 2 个打印“Hello World”的任务组成,这些任务需要按顺序进行编排。DataJob将这些任务部署到 Glue,并通过阶梯函数(Step Functions)进行编排。
from aws_cdk import core
from datajob.datajob_stack import DataJobStack
from datajob.glue.glue_job import GlueJob
from datajob.stepfunctions.stepfunctions_workflow import StepfunctionsWorkflow
app = core.App()
# The datajob_stack is the instance that will result in a cloudformation stack.
# We inject the datajob_stack object through all the resources that we want to add.
with DataJobStack(scope=app, id="data-pipeline-simple") as datajob_stack:
# We define 2 glue jobs with the relative path to the source code.
task1 = GlueJob(
datajob_stack=datajob_stack, name="task1", job_path="glue_jobs/task.py"
)
task2 = GlueJob(
datajob_stack=datajob_stack, name="task2", job_path="glue_jobs/task2.py"
)
# We instantiate a step functions workflow and orchestrate the glue jobs.
with StepfunctionsWorkflow(datajob_stack=datajob_stack, name="workflow") as sfn:
task1 >> task2
app.synth()我们将上述代码添加至项目根目录下名为 datajob_stack.py 的文件中。此文件包含配置 AWS 服务、部署代码和运行数据管道所需内容。
接着,克隆(Clone)存储库,并回到本例中。
git clone https://github.com/vincentclaes/datajob.git
cd datajob/examples/data_pipeline_simple配置 CDK
要配置 CDK,你需要 AWS 的凭据。如果你不知道如何配置 AWS 凭据,请按照以下步骤操作。
export AWS_PROFILE=default
# use the aws cli to get your account number
export AWS_ACCOUNT=$(aws sts get-caller-identity --query Account --output text --profile $AWS_PROFILE)
export AWS_DEFAULT_REGION=eu-west-1
# bootstrap aws account for your region
cdk bootstrap aws://$AWS_ACCOUNT/$AWS_DEFAULT_REGION
⏳ Bootstrapping environment aws://01234567890/eu-west-1...
CDKToolkit: creating CloudFormation changeset...
✅ Environment aws://01234567890/eu-west-1 bootstrapped.部署
使用包含代码的 Glue 任务,将编排 Glue 任务的 Step Functions 状态机创建 DataJob 堆栈。
cdk deploy --app "python datajob_stack.py" --require-approval never
data-pipeline-simple: deploying...
[0%] start: Publishing
[50%] success: Published
[100%] success: Published
data-pipeline-simple: creating CloudFormation changeset...
✅ data-pipeline-simple当 cdk deploy 完成时,准备执行已配置好的服务。
执行
datajob execute --state-machine data-pipeline-simple-workflow
executing: data-pipeline-simple-workflow
status: RUNNING
view the execution on the AWS console:
<here will be a link to see the step functions workflow>触发编排数据管道的阶梯函数状态机(Step Functions state machine)。
终端将显示阶梯函数网页链接,以跟进管道运行情况。如果单击此链接,你应该会看到如下内容:
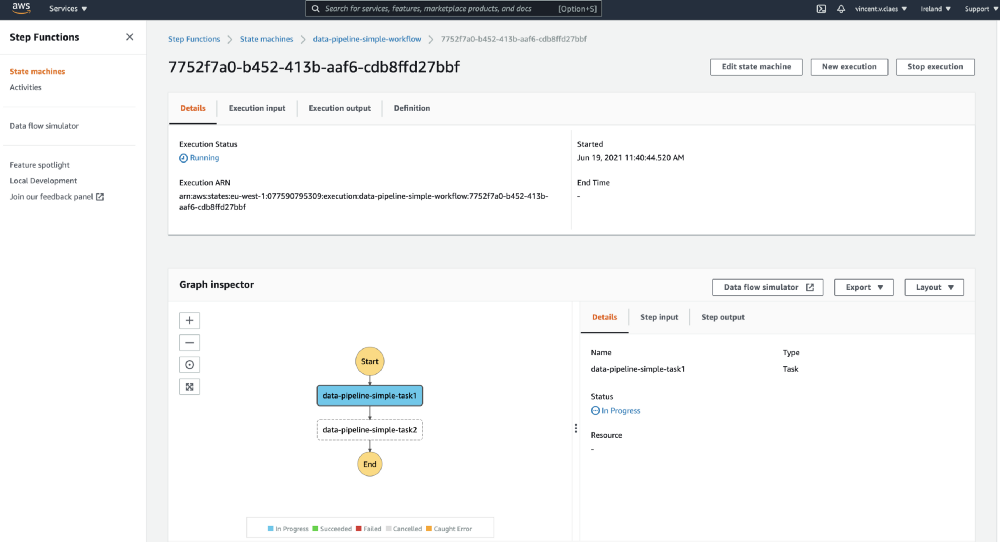
删除
数据管道完成后,将其从 AWS 中删除。这样,你将拥有一个干净的 AWS 账户。
cdk destroy --app "python datajob_stack.py"
data-pipeline-simple: destroying...
✅ data-pipeline-simple: destroyedDataJob 的一些功能
- 1. 使用 Glue Pyspark 任务处理大数据
import pathlib
from aws_cdk import core
from datajob.datajob_stack import DataJobStack
from datajob.glue.glue_job import GlueJob
from datajob.stepfunctions.stepfunctions_workflow import StepfunctionsWorkflow
current_dir = str(pathlib.Path(__file__).parent.absolute())
app = core.App()
with DataJobStack(
scope=app, id="datajob-python-pyspark", project_root=current_dir
) as datajob_stack:
pyspark_job = GlueJob(
datajob_stack=datajob_stack,
name="pyspark-job",
job_path="glue_job/glue_pyspark_example.py",
job_type="glueetl",
glue_version="2.0", # we only support glue 2.0
python_version="3",
worker_type="Standard", # options are Standard / G.1X / G.2X
number_of_workers=1,
arguments={
"--source": f"s3://{datajob_stack.context.data_bucket_name}/raw/iris_dataset.csv",
"--destination": f"s3://{datajob_stack.context.data_bucket_name}/target/pyspark_job/iris_dataset.parquet",
},
)
with StepfunctionsWorkflow(datajob_stack=datajob_stack, name="workflow") as sfn:
pyspark_job >> ...- 2. 部署独立管道
在CDK中指定一个阶段作为上下文参数,部署一个独立管道。经常用到的有dev, prod,…
cdk deploy --app "python datajob_stack.py" --context stage=dev- 3. 并行编排 Step Function 任务
为了加速数据管道,您可能希望并行运行任务。DataJob可以帮助你执行此操作!我借用了 Airflow 的概念,您可以使用运算符 >> 协调不同的任务。
with StepfunctionsWorkflow(datajob_stack=datajob_stack, name="workflow") as sfn:
task1 >> task2
task3 >> task4
task2 >> task5
task4 >> task5DataJob 计算哪些任务可以并行运行,从而加快执行速度。
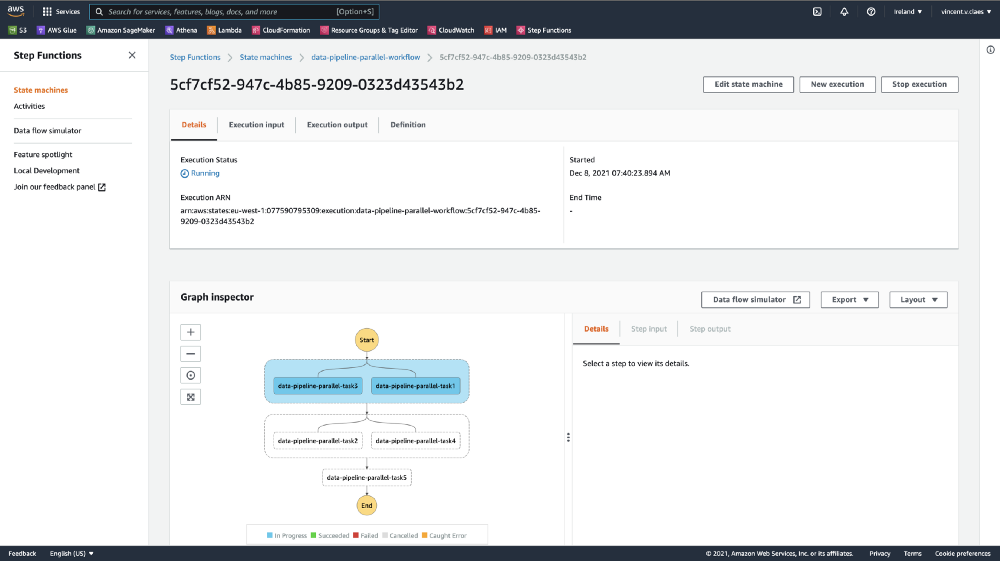
部署并触发后,你将在步骤函数执行中看到并行任务。
- 4. 失败/成功时通知
在 StepfunctionsWorkflow 对象的构造函数中,提供带有电子邮件地址的参数notification。这会创建一个 SNS 主题,该主题将在失败或成功时触发,同时收件箱会收到通知。
with StepfunctionsWorkflow(datajob_stack=datajob_stack,
name="workflow",
notification="email@domain.com") as sfn:
task1 >> task2- 5. 将项目打包为Wheel文件,并将其发送到 AWS
将项目及其所有依赖项发送到 Glue。通过在 DataJobStack 的构造函数中指定 project_root,DataJob 将在你的 project_root 的 dist/ 文件夹中查找Wheel文件(.whl 文件)。
current_dir = str(pathlib.Path(__file__).parent.absolute())
with DataJobStack(
scope=app, id="data-pipeline-pkg", project_root=current_dir
) as datajob_stack:- 6. 添加 Sagemaker,创建 ML Pipeline
通过 Glue、Sagemaker 和 Step 函数,可以查看 GitHub 存储库上端到端机器学习管道的新示例。
感谢你的阅读!你会尝试这个新工具吗?请在评论中告诉我您的想法。你还可以订阅我们的YouTube频道,观看大量数据科学相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Vicent Claes
翻译作者:Lia
美工编辑:过儿
校对审稿:Jiawei Tong
原文链接:https://towardsdatascience.com/datajob-build-and-deploy-a-serverless-data-pipeline-on-aws-18bcaddb6676





