
使用Amazon SageMaker和AWS Lambda进行无服务器管道自动化模型训练和部署
什么是MLOps?
MLOps能够把机器学习模型投入到生产中,并建立起一系列流程和容量来操作、维护生产模型。建立机器学习模型的初始阶段,包括迭代实验和研究阶段,这时,数据科学家会在数据上尝试不同类型的模型,做特征工程,对模型超参数(hyper-parameters)和原型进行微调,来构建候选的模型,让这些模型可以在更大的数据集上进行规模化训练,然后部署到生产中。
大数据应用数据应用学院被评为2016北美Top Data Camp, 是最专业一站式数据科学咨询服务机构,你的数据科学求职咨询专家!3748篇原创内容公众号
MLOps由一组实践组成,通过把模型从实验阶段快速转移到生产阶段、和自动化所有的步骤来减少错误和成本,通过监控模型并提供反馈机制,来捕获新的数据点以重新训练模型。如果你想了解更多数据分析相关内容,可以阅读以下这些文章:
Amazon Sagemaker是什么,怎么用?
Machine Learning知识点:机器学习里的聚类分析技巧
三个月如何搞定机器学习的数学原理?
研究了2000+笔记本,我们总结了最适合机器学习、数据科学和深度学习的电脑
以下是一个企业中成熟MLOps框架的高级组成部分:
- 建立相关管道来协调和自动化模型的训练和部署
- 设置监控系统来识别模型中任何类型的降级
- 建立模型注册表来记录目录和模型版本
- 确定下游系统如何使用模型,并做出适当的架构选择来部署模型:实时推理(real time inference)、批量推理(batch inference)、流预测(streaming predictions)、设备上预测(on-device predictions)
- 根据增加的流量自动扩展模型
- 能够解释模型推理的输出
- 能够追溯产生推理的模型和数据的版本
- 能够快速回滚模型,在不同版本的模型上执行Canary部署和 A/B 测试
- 跨环境(DEV、QA、PROD)移动模型的CICD管道
模型培训和管道部署技术
在本文中,我们会描述一个简单的管道,这个管道可以在 AWS 云上自动训练和部署模型。该管道使用AWS平台上的无服务器技术,可以避免配置EC2、维护和修补实例、处理扩展等。该管道使用 Step Functions 来编排工作流中的各个步骤,使用SageMaker对模型进行培训,使用SageMaker hosting来部署模型的端点。
以下是该管道中主要使用的AWS服务:
- Step Functions — 工作流编排
- SageMaker — 模型的训练和托管
- AWS Serverless Application Model (SAM) — 构建无服务器的应用程序、提供资源框架
- API Gateway —前端SageMaker托管端点,提供监控和安全
- CodeBuild — 构建训练、推理文档的docker图像
- Elastic Container Registry — 存储docker图像
- Lambda — 无服务器计算
- Simple Storage Service — 存储训练、测试和验证数据
- Simple Notification Service —在管道执行期间把成功/失败/错误通知给运营团队
- EventBridge — 无服务器事件总线
- Systems Manager (Parameter Store) —存储管道参数和模型的超参数
高层架构
下图显示了训练、部署机器学习模型管道的高级架构:
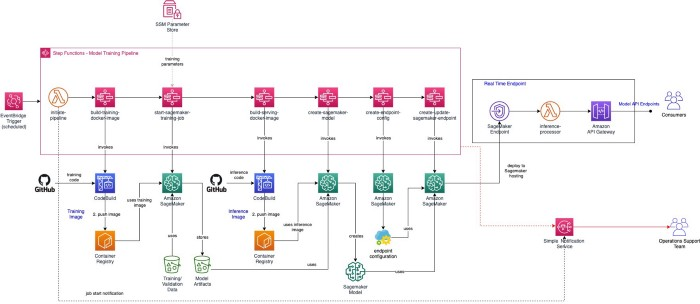
详细步骤
- 触发管道执行:模型的训练和部署 StepFunction ,是通过EventBridge Trigger以一定的节奏(每天/每周/每月)触发的。EventBridge可以根据新训练数据的可用性、模型算法的更改等来改变触发条件,而不是定时执行。‘initiate-pipeline’ 这个lambda函数会向运营团队的SNS主题发送通知,提醒他们培训过程已经开始。此lambda函数可用于进行任何类型的初始设置,比如,为了存储中间数据创建临时工作区、在监视系统中记录执行开始时间、获取数据和代码版本的快照等。
- 构建训练图像:我们将使用原生Step Function与CodeBuild服务的集成,来启动Codebuild 作业,该作业会从Github的存储库中检出模型训练代码,在有/没有GPU的情况下拉取相应的 AWS提供的基础训练图像 (TensorFlow/PyTorch/MXNet)支持,构建训练代码的 docker 图像,并将其推送到 Elastic Container Registry (ECR)。
- 启动模型培训作业:我们会用带有StepFunctions的本地SageMaker集成来启动一个SageMaker培训作业。使用本机集成可以减少启动、完成任务和处理错误所需的编码量。SageMaker培训作业从ECR中提取最新(或特定版本)的培训图像,并使用S3中的培训数据,运行模型培训作业。我们可以使用SSM Parameter Store向管道公开训练特定的参数。
- 把模型部署到SageMaker Hosting:一旦训练作业成功完成,SageMaker会把模型工件存储到S3 中。我们可以根据用例的要求,把模型部署为实时端点或批量转换作业。如果消费应用程序需要低延迟的动态进行实时数据预测,那么就应该把这个模型部署为API。
- 实时端点—构建服务图像:在step函数中包含一个触发CodeBuild作业的步骤,该作业会从代码存储库(Github)中提取模型推理的应用程序,构建推理代码的docker图像,并将其推送到 Elastic Container Registry (ECR)。
- 实时端点—创建SageMaker模型:在step函数中包含一个调用SageMaker的步骤,使用上一阶段的docker图像和经过训练的模型工件,来创建一个“SageMaker 模型”对象。
- 实时端点—创建端点:管道会创建SageMaker的端点配置(包括实例数量、实例类型、流量路由等)。端点配置和SageMaker模型对象,被用于在SageMaker托管实例上部署端点。
- 实时端点—推理:SageMaker端点以API网关为前端,由lambda推理处理器支持。消费者会向API网关发出推理请求。lambda会对请求进行预处理,并移交给SageMaker进行推理。lambda会处理推理,并通过API网关将其返回给消费者。
- 错误通知:管道执行期间的任何故障都会给要分类、解决问题的运营支持团队发送错误通知(电子邮件)。而工作流中的每个步骤都可能产生错误,失败并触发随后的通知。所以,我们必须确保step函数的任何步骤、或分支中的任何失败都将导致整个管道失败,才能确保收到通知。
- 管道部署环境:模型训练和部署管道,会通过CICD管道部署到各种环境(DEV/STAGE/PROD)。在推到更高的环境之前,CICD管道会进行管理,确认模型是经过了适当测试,并且指标是可接受的。对于敏感或对外的模型,我们建议在CICD管道中设置手动批准阶段。另外,还可以使用Canary部署等高级部署策略,来确保模型在所有流量上线之前,在一组特定消费者间使用。
本文中,我们简要描述了AWS上成熟的自动化培训和部署管道。在后续的文章中,我们会从AWS平台的角度提供更多关于MLOps其他方面的细节,比如模型监视、模型注册、自动伸缩等。
请继续关注这个系列的更多信息!你还可以订阅我们的YouTube频道,观看大量数据科学相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Jayant Raj
翻译作者:Lea
美工编辑:过儿
校对审稿:Jiawei Tong
原文链接:https://raj-jayant.medium.com/serverless-pipelines-for-automated-model-training-and-deployment-using-amazon-sagemaker-step-f2aaf002a190





