
详解Netflix推荐系统:他们是如何做到这么受欢迎的?
Netflix是当今大多数人电影和电视节目的首选流媒体服务。
然而,大多数人不知道的是,Netflix在上世纪90年代末其实是以订阅模式起步的,那时候他们把DVD直接邮寄到美国人的家中。
在数据爆发的时代,现在Netflix 最想做的,就是向用户推荐下一个内容。 他们唯一想解决的问题,就是“如何尽可能为用户个性化 Netflix?”。 尽管这是一个单一的问题,但它几乎是 Netflix 想做到的终极目标。 推荐被嵌入在了他们网站的每个部分。本文就将为你介绍 Netflix的推荐系统,带你了解背后的技术和逻辑,以及他们是如何做到这么成功的。如果你想了解更多数据分析相关内容,可以阅读以下这些文章:
Netflix等视频平台的人工智能:到底是真人工,还是假智能?
推荐系统,比你更懂你
TikTok如何利用推荐系统,比你更懂你?
大数据告诉你Tiktok为何让人如此上头?

Netflix奖
2000年,Netflix推出了个性化的电影推荐,并于 2006年推出了“Netflix奖”,这是一个机器学习和数据挖掘竞赛,奖金为100万美元。当时,Netflix使用了它独有的推荐系统Cinematch,该系统的均方根误差(RMSE)为0.9525,而它们要求人们超越这一基准的10%。一年后,能够达到或接近这个目标的团队将获得奖金。
一年后的2007年,Progress Prize的获得者用矩阵分解(SVD)和受限玻尔兹曼机(RBM)的线性组合,实现了0.88的RMSE。Netflix在对源代码进行了一些修改后,将这些算法投入生产。值得一提的是,尽管有团队在2009年实现了0.8567的RMSE,但Netflix没有将这个算法投入生产,因为这需要大量工程努力来获得精度的提高。这在现实生活中的推荐系统中是很重要的一点——模型改进和工程工作之间,总是存在着正相关的关系。
流媒体——新的消费方式
Netflix没有采用更精确的算法的一个更重要的原因是,它在2007年引入了流媒体。有了流媒体后,数据量急剧增加。所以,它必须改变推荐系统产生推荐和获取数据的方式。
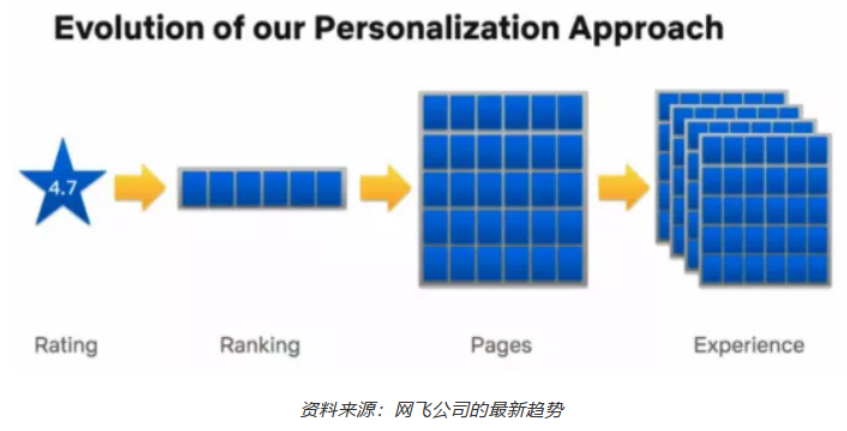
快进到2020年,Netflix已经从邮寄DVD服务转变为拥有1.828亿用户的全球流媒体服务平台。因此,它的推荐系统从预测评分的回归问题,转变成了排名问题,再转变成了页面生成问题,以及最大化用户体验的问题(定义为最大化用户观看时间,即个性化所有可以个性化的内容)。本文想要探讨的主要问题是:Netflix使用的推荐系统是什么?
Netflix的商业模式
Netflix采用的是订阅模式。简单地说,拥有的会员越多,收入就越高。而收入可以被看作是这三个因素的函数:
- 1. 新用户获取率
- 2. 取消率
- 3. 前会员重新加入的比率
Netflix的推荐系统有多重要?
80%的播放时间是通过Netflix的推荐系统实现的,这是一个非常令人印象深刻的数字。此外,Netflix还认为用户体验可以提高用户留存率,从而节省获得用户的成本(从2016年起,估计每年可节省10亿美元的成本)。
Netflix推荐系统
Netflix是如何排名的?
很明显,Netflix使用了一个基于行的双层排名系统,在这里排名是:
- 1. 在每一行中(左边是最强推荐)
- 2. 跨行(最强推荐在顶部)
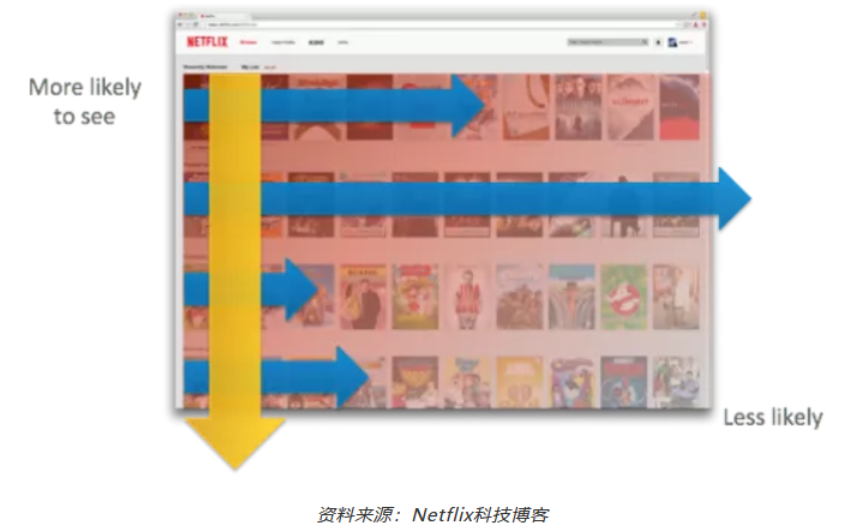
每一行突出显示一个特定主题(如最热门的10个视频, 最受欢迎, 恐怖片等),通常是使用一种算法生成的。每个会员的主页由大约40行,多达75个项目组成,这取决于会员使用的设备。
为什么是行?
它的优势可以从两个方面看:
- 1)用户在看到一行相似的条目时,会更加连贯,然后决定他或她是否对该类别的东西感兴趣;
- 2)对于公司来说,更容易收集反馈,因为向右浏览一行表示感兴趣,而向下滚动(忽略该行)表示不感兴趣(不一定不相关)。
使用了什么算法?
Netflix使用了他们论文中提到的各种排名,但没有具体说明每种模式的架构。以下是对它们的总结:
Personalised Video Ranking (PVR)——这个算法是通用的,它通常根据一定的标准(例如暴力电视节目,美国电视节目,情感剧等)过滤目录,并结合用户功能和人气等辅助功能。

Top-N Video Ranker-类似于PVR,只是它只查看排名的最前面和整个目录。它是通过查看目录排名榜首的指标(如MAP@K, NDCG)进行优化的。

Trending Now Ranker——该算法捕捉 Netflix 推断为强预测因子的时间趋势。这些短期趋势的范围从几分钟到几天不等。这些事件/趋势通常是::
- 1. 具有季节性趋势并不断重复的事件(例如情人节导致情感类视频的增加)
- 2. 一次性、短期事件(如冠状病毒或其他灾难,导致人们短期关注有关这些事件的纪录片)

Continue Watching Ranker -该算法查看会员已经消费但还没有完成的物品,通常情况下:
- 1. 多集的内容(如连续剧)
- 2.可以少量消费的非情节性内容(例如,完成一半的电影,每集情节独立的系列,如《黑镜》)
该算法计算会员继续观看的概率,并包括其他上下文感知信号(如观看后经过的时间、放弃点、观看的设备等)。

在Justin Basilico的演讲中,他介绍了RNN在时间敏感序列预测中的使用,我认为,这个算法中使用了RNN。他设想,Netflix可以根据特定会员过去看过的剧和背景信息,来预测该会员的下一部剧可能是什么。特别是,使用连续时间和离散时间的情况作为输入时,表现最好。

Video-Video Similarity Ranker视频相似性排序-因为你看了xxx,所以推荐给你这些视频。
该算法基本上类似于基于内容的过滤算法。根据会员所消费的物品,算法计算其他类似物品(使用物品-物品相似度矩阵),并返回最相似的物品。在其他算法中,这个算法是不个性化的,因为没有使用其他方面的特征。然而,它又在某种意义上是个性化的,因为它是一个有意识的选择,以显示一个特定项目的类似项目会员的主页。

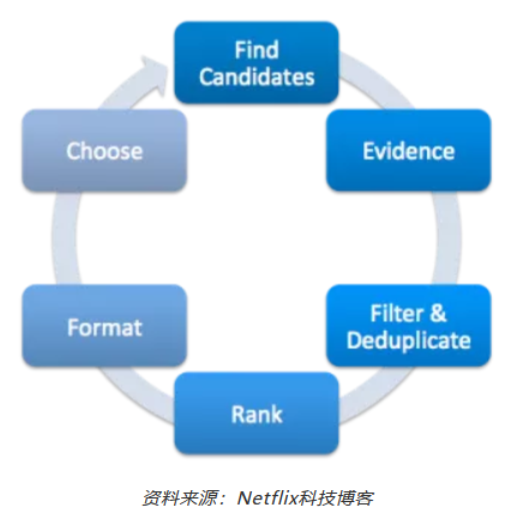
行生成的过程
上面的每一个算法都经过如下图所示的行生成过程。例如,如果PVR正在研究浪漫题材的视频,它将找到适合这一类型的候选用户,并同时有证据来支持一行的呈现(例如,用户之前看过的浪漫电影)。
根据我的理解,这个证据选择算法是合并(或一起使用)在上面列出的其他排名算法中,以创建一个更有条理的项目排名列表(见下面Netflix的模型工作流图片)。
这种证据选择算法会使用“Netflix在页面左上角显示的所有信息,包括Netflix奖关注的预测星级、剧情简介、有关该视频的其他信息,如奖项、演员阵容或其他元数据;以及Netflix用于支持用户界面中的行和其他地方的建议。”
这五种算法中的每一种都经过如下图所示的相同的行生成过程。
页面的生成
在算法生成出候选行(已经在每个行向量中排序)之后,Netflix该如何决定要显示这10000行中的哪一行?
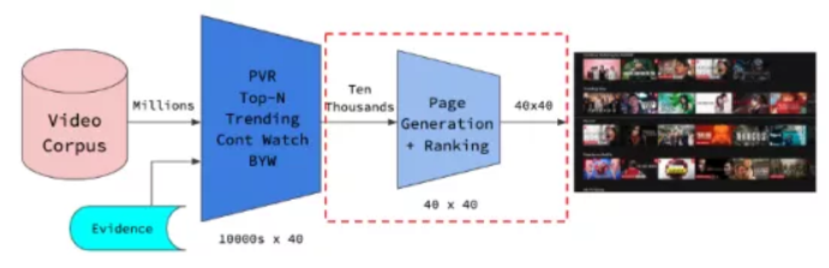
过去,Netflix使用基于模板的方法来解决页面生成的问题,也就是说,为了争夺宝贵的屏幕空间。这是一项不仅注重准确性,而且同时提供多样性、可访问性和稳定性的任务。其他考虑包括了硬件功能(使用的是什么设备)和哪些行/列在第一眼和滚动时可见。
这意味着,Netflix想要准确地预测用户在这个过程中想要看什么,但又不忘记他/她可能想要继续观看暂停的视频。与此同时,它希望通过提供一些新鲜的东西来突出其目录的深度,或许还想研究用户所在地区目前的趋势。最后,当用户与Netflix有过一段时间的互动,并且习惯了以某种方式浏览页面时,稳定性是很有必要的。
有了所有这些需求,你就会明白为什么基于模板的方法在一开始就可以很好的工作,因为在任何时候都可以满足一些固定的标准。然而,在提供良好的会员体验方面,有了许多规则,所以Netflix自然就成为了最优的网站。
那么我们如何处理这个行排序问题呢?
基于行的方法
基于行的方法用现有的推荐或学习排序方法,对每一行进行评分,并基于这些分数对它们进行排名。这种方法可能相对较快,但缺乏多样性。用户可能会看到一个与他/她的兴趣相匹配的页面,但行与行之间可能非常相似。那么我们如何融合多样性呢?
阶段性方法
对于行上升方法的改进是用阶段性方法,其中,每一行都像上面的方法一样打分。但是,将按顺序从第一行中选择行,每当选择一行时,将重新计算下一行,以考虑它与前一行以及已为页面选择的前一项的关系。这是一个简单而贪婪的阶段方法。
我们可以通过使用k行前瞻法来改进这个问题,在计算每一行的得分时,我们考虑接下来的k行。然而,这两种方法都不能得到全局最优解。
机器学习方法
Netflix使用的解决方案和方法是机器学习,他们的目标是通过使用他们为用户创建的主页的历史信息(包括他们实际看到了什么,他们如何互动,他们播放了什么)来训练一个模型,从而创建一个评分功能。
当然,还有许多其他功能和方法可以表示算法主页中的特定行。它可以简单到使用所有元数据(作为嵌入)并聚合它们,或按位置为它们建立索引。不管使用什么功能来表示页面,主要的目标都是生成假设的页面,并查看用户将与哪些项进行交互。然后使用页面指标完成评分,例如Precision@m-by-n和Recall@m-by-n(它们是Precision@k和Recall@k的改编,但在二维空间中)。

以上就是本文全部内容!希望能帮助你对推荐系统的原理和技术有所了解。你还可以订阅我们的YouTube频道,观看大量数据科学相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:David Chong
翻译作者:过儿
美工编辑:过儿
校对审稿:Jiawei Tong
原文链接:https://towardsdatascience.com/deep-dive-into-netflixs-recommender-system-341806ae3b48





