
推荐系统,比你更懂你
在过去的几十年中,随着 Youtube、Amazon、Netflix 和许多其他网络服务的兴起,推荐系统在我们的生活中占据了越来越多的位置。 从电子商务(向买家推荐他们可能感兴趣的文章)到在线广告(向用户推荐正确的内容,匹配他们的偏好),推荐系统如今在我们的日常线上生活中是不可避免的。
一般来说,推荐系统是一种算法,旨在向用户推荐相关项目(项目是要观看的电影、要阅读的文本、要购买的产品或其他任何取决于行业的内容)。
我想大家都会同意,现在网络购物几乎可以模拟实体店的购物体验了,就像实体店的销售人员会根据我们的偏好给出建议、指导我们购买合适的产品。
不可否认的是,我已经不止一次地发现,不管是在Amazon还是服装网站上,还是在Netflix等流媒体网站上,它们推荐的东西我都很喜欢,这很诡异。但同时这也意味着,他们的推荐真的做的很好!

“Netflix奖”是Netflix举办的一项公开竞赛,目的是去发现预测用户对电影评分的最佳算法。该奖项得出的结论之一是,提出合理推荐很简单,但要改进它们却非常困难。
因此,如果你想要构建一个应用程序来提供非常成功的推荐,都需要什么?
本文会探讨一些传统但又很成功的推荐系统方法——协同过滤和基于内容的推荐。本文还会重点介绍每种方法的缺点,以及应该如何去克服它们。如果你想了解更多数据分析相关内容,可以阅读以下这些文章:
TikTok如何利用推荐系统,比你更懂你?
Machine Learning知识点:机器学习里的聚类分析技巧
三个月如何搞定机器学习的数学原理?
研究了2000+笔记本,我们总结了最适合机器学习、数据科学和深度学习的电脑
介绍
什么是“推荐问题”?
问题是指,要找到一个效用函数,根据用户过去的行为、与其他用户的相似度、与其他商品间的相似度、内容描述等,来评估用户对商品的喜爱度。
推荐方法的简要总结:
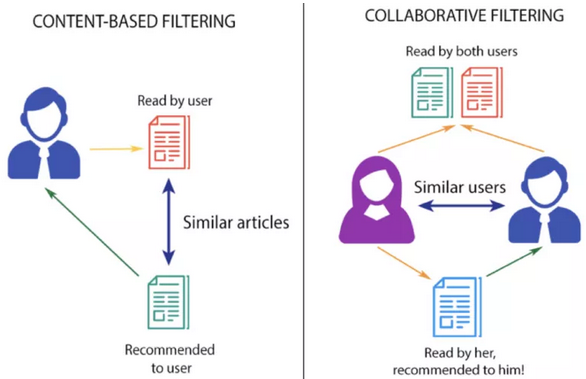
- 1、协同过滤(Collaborative Filtering):根据用户的过去行为来推荐项目。
这是是一种不可知的算法,也就是说,不管算法是否尝试推荐电影,书籍,还是产品,都不需要考虑太多关于该领域的知识。这种方法的两个子类型是:
— 基于用户的方法(User-based approach):寻找与目标用户相似的用户,并推荐他们喜欢的内容
— 基于项目的方法(Item-based approach):寻找与用户先前喜欢的项目相似的项目
- 2、基于内容的方法(Content-based Approach):与协同过滤几乎相反;她并不重视用户过去的行为,而是根据项目特征或描述来推荐新项目。
- 3、个性化学习排名(Personalised Learning to Rank):把推荐视为排名问题(同时运用协同过滤和基于内容的方法)
- 4、人口统计方法(Demographic Approach):根据用户特征推荐新项目
- 5、社交推荐(Social Recommendations):基于信任(利用用户之间的现有关系)
- 6、混合方法(Hybrid Approach):就是把上述任何方法组合起来使用
数据挖掘推荐
推荐可以理解为一般的数据挖掘问题,如下所示:

把推荐当成数据挖掘问题。
意外发现
大多数推荐系统推荐的商品在所有的用户中都很流行,并且与用户日常消费的商品很相似。结果,用户收到的是她/他已经熟悉或者无论如何都会去找的推荐,导致满意度很低。为了克服这个问题,推荐系统应该:
- 启用意外发现-用户不知道他/她想寻找的东西
- 推荐一些新奇的、相关的、但意想不到的东西,比如,一些偶然发现的东西
- 把用户的喜好扩展到邻近地区
协同过滤可以提供可控的偶然发现——它知道在推荐中参与了多少相邻用户。
什么有效,什么重要:
任何人在开始构建推荐系统之前,都希望从自己知道的一些有效事物开始。虽然,这在很大程度上取决于领域和特定问题,但可以肯定的是,协作过滤就是最好的隔离方法。也可以混合使用其他方法来改善结果、解决诸如冷启动等问题。
什么重要:
- 数据预处理:异常值去除、去噪、去除全局效应(如:单个用户的平均值)
- 使用矩阵分解、SVD进行智能降维
- 组合不同方法
协同过滤(CF)
如上文所述,协同过滤是一种与其推荐项目完全无关的方法。它完全适用于用户的过去行为。
CF的组成:
- 包含‘m’个用户的列表和‘n’个项目的列表
- 每个用户都有一个带有相关意见的项目列表。意见可以是:- Explicit详细、清晰明了的(像评分表一样)– Implicit隐私保密的(如购买记录等)。
值得注意的是,明确的评级可能会很嘈杂而且带有偏见——比如:提到一部奥斯卡获奖纪录片,用户可能想给它一个5星评级。但并不意味着用户想要被推荐更多的纪录片。

另外,获取详细数据要难得多。如果你想要获取大数据,隐式方法是可行的,因为它更容易获得,而用户不需要采取任何额外步骤。
- 正在执行CF预测任务的活跃用户
- 衡量用户之间相似度的指标
- 选择邻近子集的方法
- 预测活动用户当前未评级项目的评级方法
协同过滤的基本步骤:
- 1. 确定目标/活跃用户的评级
- 2. 根据相似度函数(邻域形成)识别与目标或者活跃用户最相似的用户
- 3. 确定相似用户喜欢的产品
- 4. 生成目标用户对每种产品的评级预测
- 5. 根据预测评分表,推荐一组排名靠前的产品
协同过滤的优势:
- 不需要相关领域的知识
- 帮助用户发现新的兴趣-意外发现
- 非常简单的方法,并在大多数情况下能产生足够好的结果
协同过滤的缺点:
- 需要大量可靠的用户反馈数据点来引导
- 要求产品的标准化(需要用户购买完全相同的产品——对于像亚马逊这样拥有大型商品目录的网站来说非常困难)
- 假设先前的行为决定了当前的行为,不考虑“上下文”知识的话存在很大弊端。比如,一个用户在搬家时一次性购买家具之后,其实就不希望再被推荐更多的家具了。
所以,这种方法存在一些局限性或缺点,比如下面的“冷启动”问题。
个性化CF vs非个性化CF:
- CF推荐比较个性化,是因为它们基于相似用户的评级进行“预测”。所以,每个目标用户的邻居区域都不一样。
- 非个性化推荐,是平均所有用户推荐,然后生成一个基于协作的推荐。
在推荐中你尝试的第一基准、或第一种方法应该是最受欢迎的选择。如果你基于CF的推荐没有更受欢迎,那你可能就做错了。

基于用户的CF:
首先,找到与目标用户相近的邻近用户,然后根据其邻近用户的加权,对目标用户进行计算预测。
目标用户与邻近用户之间的相似度可以通过Pearson关联计算。也可以根据用户的不同相似度给邻近的用户分配权重。
但是,使用邻居子集,会限制用户数量,有时候还会导致一些邻居用户可能没有对产品进行评级。这会导致数据的稀缺。如果空间维数很大,这种情况会经常发生。就会迫使我们使用一个大的邻域,而邻域较大又会导致计算效率的低下。
最邻近的协同过滤(Nearest Neighbour CF)面临的挑战:
- 稀疏性
- 推荐的准确性(可能较差)
- 可扩展性
- 爱好相似但很少评分的用户之间关联性不强
稀疏问题:
- 通常,对于大型产品集,用户只对其中很小一部分进行评级。
- 比如——亚马逊上有数百万本书。假如两位读者各买了100本书,那么他们买到同一本书的概率是0.01。
- 标准CF的用户数量必须是产品目录的十分之一。
可扩展性问题:
- 最邻近算法要求计算量,随着客户数量和商品数量的增长而增长
- 最坏情况下的复杂度是‘mn’(其中‘m’是客户数量,‘n’是产品数量)
解决方案——矩阵分解(Matrix Factorization):

在降维空间中,用潜在模型去捕获用户和项目之间的相似性。
矩阵分解(MF)的基本思想,不是用矩阵来表示稀疏空间中的项目,而是用主题将空间压缩成更小的东西。
基于项目的协同过滤:
在这种方法中,我们仍然对物品一无所知,而是基于用户的行为去推荐。这意味着,如果相同的用户喜欢两种不同类型的物品,我们也认为这些物品是相似的。
算法:
- 查看目标用户已评级的项目
- 计算它们与目标项目的相似度
- 相似度只根据其他用户过去的评分来计算
- 选择“k”个最相似的项目
- 通过对目标用户对最相似项目的评分进行加权平均来计算预测
项目相似度计算:
相似度可以是—余弦相似度、可以是基于相关性的相似度、也可以是调整后的余弦相似度。
协同过滤的限制:
- 冷启动问题:系统无法对尚未收集到足够信息的用户或项目做出任何推论。
- 流行偏见:很难向有独特品味的人推荐产品,因为CF倾向于推荐流行商品(尾端的商品不会获得太多数据)
冷启动问题:
- 新用户问题:为了做出准确的推荐,系统必须首先从评分中了解用户的偏好。有几种技术可以解决这个问题。大多数使用混合方法,将基于内容的方法与CF结合来解决这个问题。
- 新项目问题:新项目会定期添加到推荐系统中。直到有相当数量的用户对新项目进行了评分后,系统才能够推荐它。解决这个问题的方法是采用基于内容的策略或“探索新道具”策略。
基于内容的方法:
- 纯粹基于内容的系统,仅分析用户过去评分过的项目内容而建立的个人资料,为用户提供推荐
- 推荐关于项目内容的信息,而不是基于用户的意见和互动
- 使用机器学习算法,根据内容的特征描述,从示例中归纳出用户偏好的模型
内容是什么?

- 它可以是明确的属性或特征,如类型、年份、演员等
- 它也可以是使用NLP的文本内容(标题、描述、目录等)
- 它还可以分析音频和视频信号
基于内容的方法的优势:
- 不需要其他用户的数据
- 无冷启动或稀启动问题
- 能够向用户推荐品味独特的产品
- 能够推荐新的和不受欢迎的项目
- 能否通过列出导致项目被推荐的内容特征来提供推荐项目的解释
基于内容的方法的缺点:
- 要求内容可以被编码为有意义的特性
- 有些项目不适合简单的特征提取方法(例如:电影,音乐)
- 即使是文本,信息检索技术也不能考虑多媒体信息
- 用户的品味必须表现为这些内容特征的一个可学习的功能
- 很难利用其他用户的质量判断
- 很难实现偶然性
- 容易过拟合(鸽子洞pigeon hole)
- 这种方法的效果只会达到描述的程度
结论
搜索的时代已经结束了。推荐时代万岁!本文简要介绍了推荐系统的世界。它探索了更传统的建立推荐系统的方法。
虽然简单,但是协作过滤已经一次又一次地被证明可以提供非常好的结果。将它与其他方法(如基于内容的方法)结合起来,你将最终拥有一个出色的系统,它可以比用户本人更了解用户!感谢你的阅读!希望本文能让你更了解推荐系统的技术和应用。你还可以订阅我们的YouTube频道,观看大量数据科学相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Chantal D Gama Rose
翻译作者:Lea
美工编辑:过儿
校对审稿:Jiawei Tong
原文链接:https://prianjali98.medium.com/recommender-systems-know-your-users-better-than-they-know-themselves-4568eef3d4ad





