
2025年人工智能工程师必备的15个Python库
嘿,你是否觉得人工智能领域的发展速度快得让人难以跟上?
别担心,你并不是一个人!
今天,让我们来探讨每位人工智能工程师都需要掌握的15个Python库。
相信我,熟悉这些库会为你构建可靠且可扩展的人工智能应用程序提供巨大帮助。
将这份清单视为人工智能工程的“基础路线图”——这正是那些公司争相招聘的核心技能。如果你想了解更多关于Python的相关内容,可以阅读以下这些文章:
Excel中的Python:将重塑数据分析师的工作方式
5个超棒的Python项目!
数据科学家提高Python代码质量指南
从优秀到卓越:数据科学家的Python技能进化之路
什么是人工智能工程师?
在深入介绍这些库之前,我们先来明确人工智能工程师的角色和职责。
近年来,这个角色已经发生了显著的变化。与从零开始训练模型的数据科学家或机器学习工程师不同,人工智能工程师的重点是将预训练模型集成到实际的应用程序或产品中。
简单来说,这个角色的核心就是让人工智能在现实世界中真正起作用。
是不是听起来很酷?
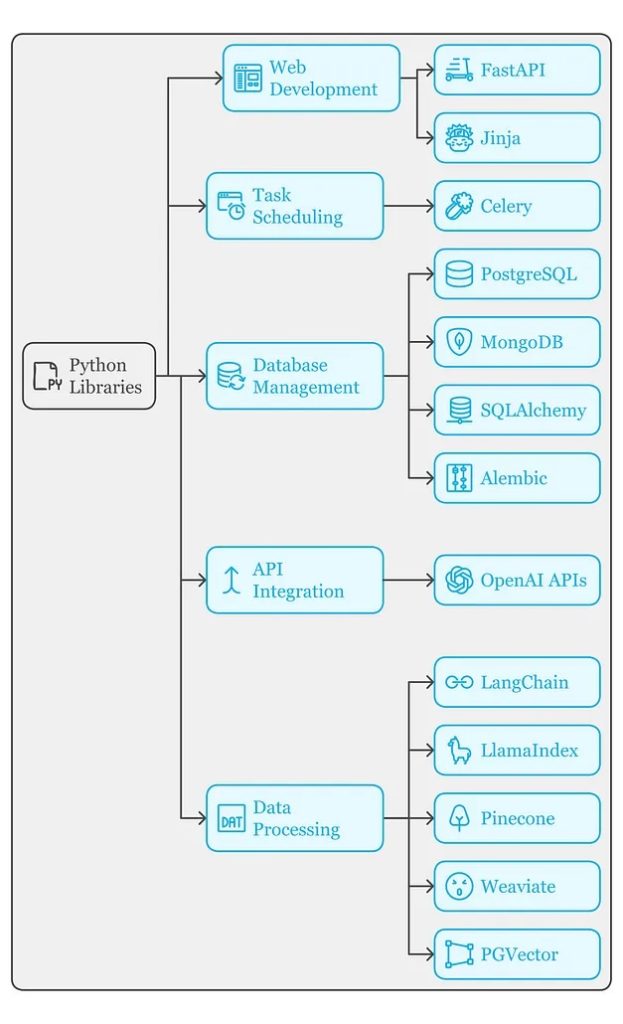
项目初始化
要启动一个人工智能项目,你需要一个坚实的基础。以下两个库可以为你奠定良好的起点:
Pydantic
Pydantic 是数据验证的首选工具,尤其适合处理复杂和不可预测的数据。它能帮你清理并结构化数据,避免系统因数据问题而崩溃。
from pydantic import BaseModel
class User(BaseModel):
name: str
age: int
email: str
user = User(name="rose", age=30, email="rose@example.com")
print(user.dict())Python-dotenv
想要将API密钥等敏感信息从代码库中分离出来?Python-dotenv 可以安全地从 .env 文件加载这些值。
from dotenv import load_dotenv
import os
load_dotenv()
api_key = os.getenv("API_KEY")
print(api_key)后端组件
项目基础搭建完成后,就该考虑后端功能了。以下几个库是值得关注的关键工具:
FastAPI
想要快速构建API?FastAPI 是一个非常棒的选择。它不仅速度快(如其名),而且与 Pydantic 集成良好,支持无缝的数据验证。
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
price: float
@app.post("/items/")
async def create_item(item: Item):
return {"name": item.name, "price": item.price}Celery
需要处理繁重的任务?Celery 提供了强大的任务队列,支持在多个线程或机器之间分发任务。
from celery import Celery
app = Celery('tasks', broker='redis://localhost:6379/0')
@app.task
def add(x, y):
return x + y数据管理
人工智能应用离不开大量数据。以下是管理数据库及相关工具的关键库:
PostgreSQL 和 MongoDB
无论是结构化数据库(如 PostgreSQL)还是非结构化数据库(如 MongoDB),你都需要掌握它们。以下是使用它们的常用库:
PostgreSQL(psycopg2 示例)
import psycopg2
conn = psycopg2.connect(
dbname="example", user="user", password="password", host="localhost")
cursor = conn.cursor()
cursor.execute("SELECT * FROM table")
rows = cursor.fetchall()
print(rows)SQLAlchemy
厌倦了冗长的 SQL 语句?SQLAlchemy 提供了一种更高效的方式来进行数据库操作。
from sqlalchemy import create_engine, Column, Integer, String
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
Base = declarative_base()
class User(Base):
__tablename__ = 'users'
id = Column(Integer, primary_key=True)
name = Column(String)
engine = create_engine('sqlite:///example.db')
Base.metadata.create_all(engine)Alembic
当需要调整数据库结构时,Alembic 可以简化迁移操作,无需直接触碰 SQL。
alembic init migrations
alembic revision --autogenerate -m "add new column"
alembic upgrade head人工智能集成
现在到了最令人兴奋的部分——将 AI 模型集成到您的应用程序中:
OpenAI、Anthropic 和 Google API
这些平台是大型语言模型(LLM)领域的佼佼者。
熟练掌握它们的 API,深入研究相关文档,并探索诸如函数调用或结构化输出等高级特性,将帮助你更高效地构建 AI 应用。
import openai
openai.api_key = "your-api-key"
response = openai.Completion.create(
engine="text-davinci-003",
prompt="Write a Python function to add two numbers.",
max_tokens=100
)
print(response.choices[0].text.strip())Instructor
如果你希望从模型中获得更结构化、可靠的输出,Instructor 是一个不错的选择。
它可以与多种模型搭配使用,并且无缝支持高级数据验证。
from instructor import Instructor
instructor = Instructor(api_key="your-api-key")
response = instructor.get_response(prompt="What is the capital of France?", model="text-davinci-003")
print(response)LangChain 和 LlamaIndex
无论你是否热衷,这些框架确实让处理大型语言模型变得更加简单。
它们抽象化了复杂的任务,例如提示管理和嵌入生成,使入门变得轻松。
from langchain.chains import LLMChain
from langchain.llms import OpenAI
llm = OpenAI(temperature=0.7)
chain = LLMChain(llm=llm)
response = chain.run("What is 2 + 2?")
print(response)矢量数据库
许多 AI 应用依赖于上下文存储来实现高效的检索功能。以下是一些推荐的选择:
松果(Pinecone)、Weaviate 和 PGVector
这些工具非常适合存储嵌入并执行相似度搜索。如果你已使用 PostgreSQL,PGVector 还提供了无缝的集成支持。
import pinecone
pinecone.init(api_key="your-api-key", environment="us-west1-gcp")
index = pinecone.Index("example-index")
index.upsert([("id1", [0.1, 0.2, 0.3])])
result = index.query([0.1, 0.2, 0.3], top_k=1)
print(result)可观察性
仅仅构建一个 AI 应用程序是不够的——您还需要能够实时监控它的运行状态:
LangFuse 和 LangSmith
这些平台可以帮助你跟踪 LLM 调用的关键元数据,包括延迟、成本和输出质量。它们就像 AI 系统的“黑匣子”,为调试提供了重要信息。
from langfuse import LangFuse
langfuse = LangFuse(api_key="your-api-key")
langfuse.log_interaction(prompt="What is 5 + 5?", response="10", latency=0.3)针对高级需求的专用工具
以下是三个专门解决特定挑战的工具:
DSPy
“编程,而不是提示”。
DSPy 可以在微调 AI 响应时节省大量时间,并优化提示效果。
from dsp import PromptOptimizer
optimizer = PromptOptimizer()
optimized_prompt = optimizer.optimize("Write a poem about space.")
print(optimized_prompt)PyMuPDF 和 PyPDF2
如果你的应用需要从 PDF 或文档中提取数据,这些库是非常好的起点。
如需更强大的功能,还可以探索诸如 Amazon Textract 之类的服务。
import fitz
doc = fitz.open("example.pdf")
for page in doc:
print(page.get_text())Jinja
Jinja 是一个强大的模板引擎,非常适合创建动态的提示逻辑。它简单高效,能够在复杂的提示管理中发挥关键作用。
from jinja2 import Template
template = Template("Hello {{ name }}!")
print(template.render(name="Raj"))总结
以上介绍的15个库构成了一个全面的工具栈,能够帮助你构建可靠、可扩展且高效的人工智能应用程序。
无论你是刚刚入门,还是希望进一步提升技能,掌握这些工具都将使您在人工智能工程领域中脱颖而出。
如果这些内容引起了你的兴趣,赶快深入研究这些库并尝试动手实践吧!
相信我,你会为自己所能创造的成果感到惊讶!
感谢阅读!你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/。
原文作者:Manpreet Singh
翻译作者:过儿
美工编辑:过儿
校对审稿:Jason
原文链接:https://medium.com/ai-simplified-in-plain-english/every-ai-engineer-should-know-these-15-python-libraries-in-2025-b83726ecc86d





