
Facebook和Microsoft数据科学家面试,他们会问这些SQL问题
本文介绍了Facebook 和 Microsoft 面试中较难的 SQL问题之一,它测试你查找和细分用户、以及将聚合表连接在一起的能力。让我们模拟面试回答这些问题。
Facebook 和Microsoft的数据科学职位竞争激烈,职位难求。你在实际工作中处理的所有问题都包含SQL编写。在本文中,我们将逐步解决 Microsoft 和 Facebook 的数据科学面试中的SQL 问题。如果你想了解更多数据分析相关内容,可以阅读以下这些文章:
如何用数据分析优化你的营销策略?
电商零售业是怎么运用数据分析的?
Data in HR Management:商科社科人文科数据分析求职新方向–人力资源管理
如何在电商数据分析中做Customer Segmentation客户细分?
我们还会给你一些建议,帮助你在类似的数据科学面试中回答这些问题。
数据科学 SQL 面试问题
新用户和现有用户
计算新用户和现有用户的比例。输出月份、新用户比例和现有用户比例的比例。
新用户为当月开始使用服务的用户。现有用户是指当月使用服务、并在之前的月份也使用过服务的用户。
假设所有日期均来自 2020 年。
问题链接:https://platform.stratascratch.com/coding-question?id=2028
解决这个问题的5个步骤:
该框架可用于任何数据科学 SQL 面试问题。以下是你在面试或工作中解决问题时应该采取的步骤。
1. 探索数据
- a) 这只适用于工作时间,因为其余大多数时候,没有可操作的 IDEList 假设
2. 列出假设
- a) 列出假设可帮助你缩小解决方案空间,识别边缘情况、并将解决方案限制在假设范围内。
3. 列大纲法
- a) 分步骤写出来,列出大纲。每个步骤都是一个逻辑语句或商业规则。
- b) 与面试官确认这些步骤。通常,如果面试官发现问题,他们会提出来,这对你有好处,因为你可以在编写代码之前就解决问题。
- c) 如果你愿意,你还可以提及问题解决过程中使用的函数。
4. 增量开发
- a) 先按逻辑构建解决方案,并与每个部分进行沟通,这样面试官就知道你在做什么了。
- b) 你的代码需要合乎逻辑、且结构良好。最重要的,是每个“代码块”不要设置超过 1 个逻辑语句或业务规则。代码块可以定义为 CTE 或子查询,因为它是独立的,并且与其余代码分开。
5. 优化代码
- a) 这通常只出现在与面试官的对话中,但在工作中,如果代码重复使用,你通常会重构代码,让项目高效运行。
数据探索
表格架构:

数据集:
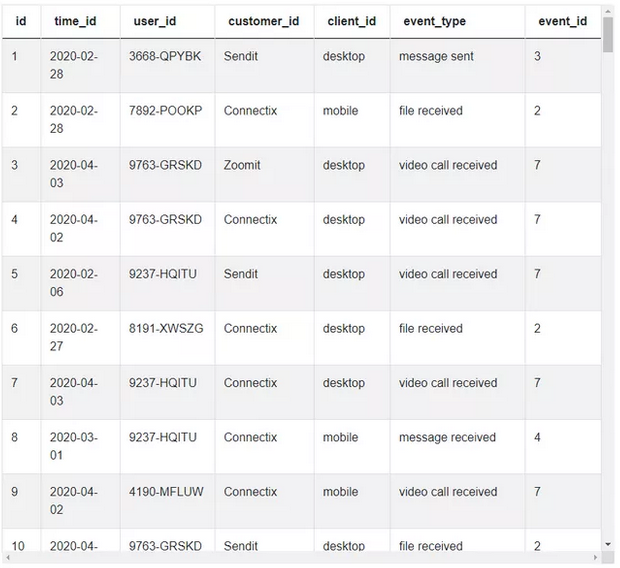
在我们探索数据时,我们可以看到:“time_id”是 YYYY-MM-DD 的形式,因此我们可以从该日期中提取月份,查找在给定月份使用服务的用户。
“user_id”是一个常规的用户列表,用于计算每月使用该服务的用户数量。
‘event_type’指的是服务类型。我们可以忽略此栏,因为我们考虑的是所有服务。在与面试官的假设中确认这一点很重要。如果你正在寻找特定的事件和服务,则需要在你的解决方案中使用此栏。在这里,我们不必这样做,否则解决方案会复杂得多。
假设
- Time_id 表示用户使用服务的时间。所有数据均来自 2020 年。这可以帮我们识别新用户和现有用户;
- User_id 是我们识别用户所需的全部内容;
- 每次用户使用服务时,它都会登录到表中,因此用户会在表中被多次列出;
- Event_type 是指服务类别,但解决方案不需要用到这一栏数据,因为我们考虑的是所有的服务或事件。
列大纲法
在开始编程之前,概述你的方法第非常重要的。将你的方法列出来,好处就是面试官可以确认你的方法是否正确。如果面试官发现你的方法或逻辑有问题,你就可以在编程之前纠正了。
现在,让我们整体过一下这个 SQL 问题的方案:
- 查找新用户,即首次开始使用服务的用户。我可以使用 min() 来查找用户首次使用服务的日期。
- 计算每月所有使用过服务的用户。减去新用户,就会得到现有用户的数量。
- 把每月新用户表和所有用户表join到一起。
- 通过将新用户数除以所有用户数来计算比例。计算现有用户的比例就是1与新用户比例的差。
增量开发
现在,你的方案应该具有以下步骤。编写代码,并在现有代码的基础上构建,然后检查每次添加逻辑时,查询是否都会运行。以下为详细步骤:
- 计算新用户数量
- 计算所有用户数量
- 连接表格
- 计算用户比例
让我们一步一步来。
1. 查找新用户,即首次开始使用服务的用户。
我们可以通过从每个用户的’ time_id ‘列中找到最小日期来找到新用户,从而找到他们开始使用服务的日期。
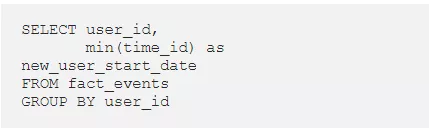
2. 从日期中提取月份,然后计算唯一的用户数,来计算每月新用户数。
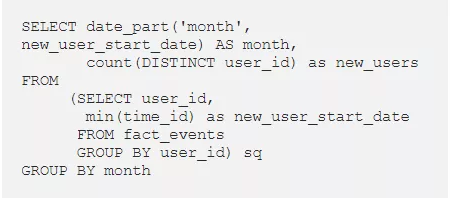
要聚合每月用户,我们可以使用 date_part() 函数,并从“time_id”中提取月份。所有数据均来自 2020 年这一点是有用的,因为我知道所有月份也都来自 2020 年。如果我们在这个数据集中有来自不同年份的数据,则不能使用 date_part() ,因为来自不同年份的月份会混合在一起。我们必须使用 to_char() 函数并按 MM-YYYY 聚合数据。
3. 计算每个月的所有用户数(现有和新用户)
我们需要减去新用户数,得到现有用户数。
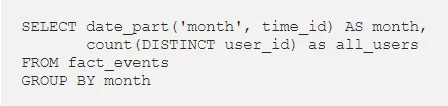
4.按月将两张表连接在一起
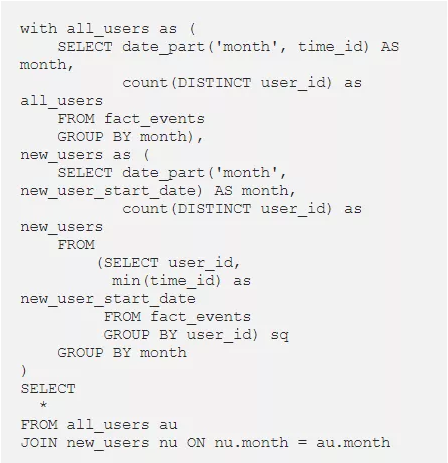
5. 计算用户比例
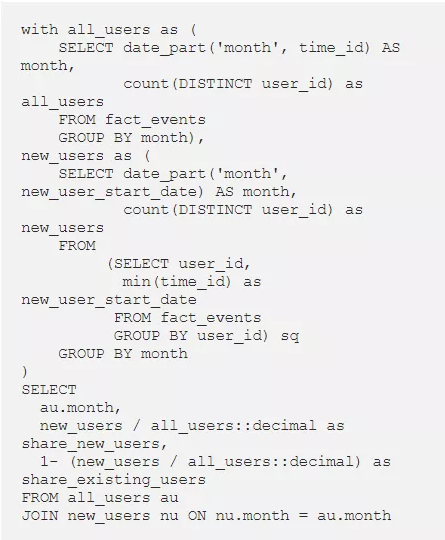
如果我们运行此查询,我们就可以得到每月新用户和现有用户比例。
输出结果:
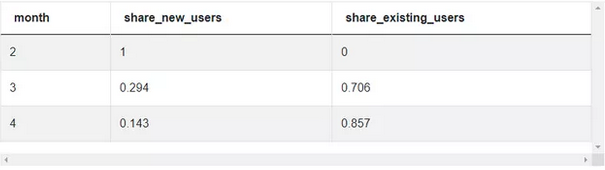
这里需要注意的是,现有用户的计算可以通过从新用户的比例中减去 1 得到。此外,在执行除法之前,请记住将计算转换为小数或浮点的数据类型。
优化
有一个问题经常出现,那就是是否有方法可以优化我们的代码。面试官是在测试你的SQL理论,所以,即使没有办法优化代码,你也应该说点什么。
看一看我们的解决方案,是没有办法进一步优化这段代码的。
有的时候,你可以使用 case 语句省略join函数,但这在我们的方法中是无效的,因为我们需要确定整个数据集的最小日期,但case 语句会逐行进行。因此,你需要一个子查询或 CTE 来执行该操作。
你还需要执行相同的子查询/CTE 操作,来查找每月所有用户,因此我们无法优化该部分代码或两个子查询的join函数。
即使没有办法优化代码,但你仍然展示了一些关于SQL的知识,面试官将通过这方面评估对你对SQL理论的了解。
结论
这是一个非常硬核的数据科学SQL面试问题,因为你想要找到用户第一次使用服务的时间。并不是所有候选人都知道使用 min() 函数来识别新用户。你还需要使用高级 SQL 函数从日期字段中提取日期组件,例如月份,这让问题变得更加复杂。但在数据科学中,学习如何操纵数据是很有必要的,因为大多数分析都有数据部分。
这道数据科学中 SQL 面试问题,是通过使用框架来组织你的想法,因为其中的步骤非常多。一旦你成功列出假设,比如知道所有日期都是 2020 年,并且你的解决方案考虑了所有的服务问题,那这个问题就会变得更容易解决。你需要做的就是以合乎逻辑的步骤组织你的方法,简短地答出,并编写出代码。
在编程之前,练习构建框架并组织你的想法,那么在回答复杂问题时,你就会感觉轻松地多。
你可以关注我们的 Youtube 频道:观看更多数据科学相关讲座。https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Nathan Rosidi
翻译作者:Lia
美工编辑:过儿
校对审稿:Jiawei Tong
原文链接:https://towardsdatascience.com/facebook-and-microsoft-data-science-sql-interview-questions-175a3e0fdf43





