
马东:搞定机器学习, 最多三分钟。
数据科学界,一大难点, Machine Learning 深深折磨着每一位数据科学人儿。但身边又总有学表(chui) 论 (bi) 数据模型,所以我又要来送助攻了。让我们一起来 3 分钟入门ML,轻松学建模,融入学术圈,提高学表鉴定能力,一起快乐崇拜。
本次建模数据由
建模竞赛Kaggle的公开资源数据库赞助
https://www.kaggle.com/uciml/autompg-dataset
记住这个网站,别说我没给你资源
但你们可能缺的不是资源
是自己找数据建模的动力
我们收集了关于汽车的基本信息数据,并通过这些信息建立一个线性回归模型,从而预测汽车的耗油量 (MPG),使用的语言是 Python。
建模的第一步就是导入数据并进行探索性资料分析 (Exploratory Data Analysis)。比如,看一下数据都有哪些变量,变量之间的关系是什么样子的。在这一步经常会通过散点图来进一步判断和确认变量之间的关系。
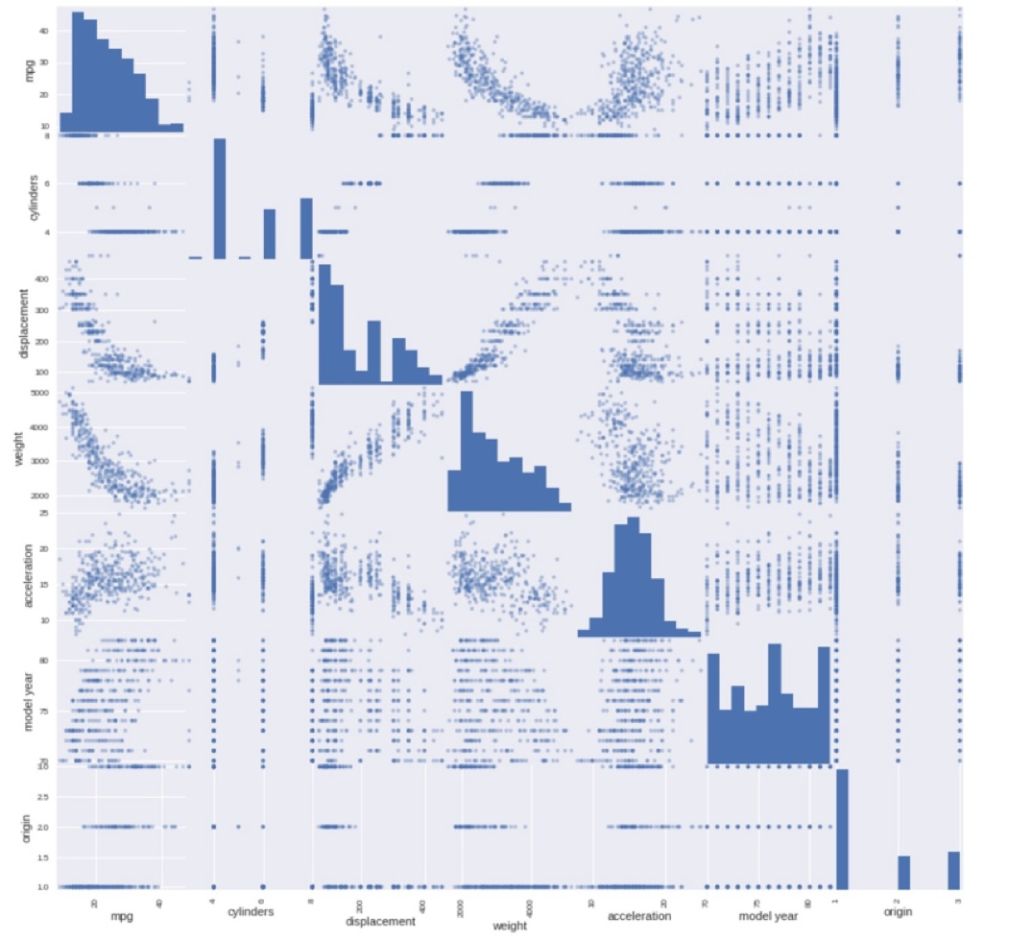
从上图👆我们可以看出,有些变量和油耗之间有着比较明显的线性关系,那下一步,我们就要用这些变量建模来找到具体的影响系数,同时观察两个变量之间是否存在线性关系。
在建模之前,先讲几个概念。数据建模时存在两个极端: Underfitting 和 Overfitting。Underfitting 就是我们建立的模型不太符合已有的数据,从下图👇中来看,我们的数据完美错过了我们的建立的线。而Overfitting 就是过于符合已有的数据,几乎每一点都要在线上了。
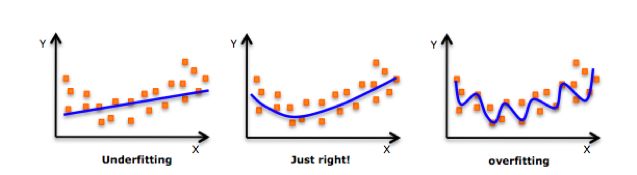
这两种情况都会导致将模型用于新的数据时,预测结果会不准确。所以理想的结果是,建立处于两者之间的模型。为了达到这个目的,就要将数据分为两部分,一部分训练模型 (training set),一部分检测模型 (test set)。
通过上面的描述,我们对数据选取我们认为有影响的变量并分组数据,然后就要开始建模了。我们将所有自变量放在一起建立 Linear Regression 来确定他们对因变量MPG 的线性影响关系,并得出它们的影响系数 (coefficients)。
建立好模型后,就要对其进行评测。主要依据就是计算预测值与真实值的差距。用到的公式叫 Mean Square Error(MSE)。

这个公式主要逻辑就是将预测值与真实值的差平方相加后取平均值,经过计算得到 MSE 只有 3,所以模型还算比较准确。接下来就可以用得到的模型来预测我们设定的数据啦。
Machine Learning 的入门就是这么简单,但一旦深入了解,你就会发现它的复杂和美妙。在坑底的我,已经给你开了这扇门,你什么时候来找我玩呀?
原文作者:Elliot Saslow
翻译作者:创作小废物
美工编辑:喝豆奶的Narcia
校对审稿:卡里
原文链接:https://blog.goodaudience.com/training-your-first-machine-learning-model-4974b25b0d58





