
不了解数据建模方法? 看这篇就对了
在本篇指南中,我将介绍几种数据建模的方法并解释它们的差异,在什么时候、为什么某一种方法比另一种更好,也会介绍一些你在建模 DWH(Data Warehouse数据仓库)或 EDW(Enterprise Data Warehouse企业数据仓库)时可以使用的工具。如果你想了解更多数据分析相关内容,可以阅读以下这些文章:
Yo!建模前你问自己这个问题了吗??
谨慎建模,小数据也可以用好深度学习
非数据分析员需要理解数据建模的7个理由
想快速学习数据科学?技巧经验都在这儿!
我的故事
我在一家小公司开始了我的 BI(商业智能)职业生涯,这个公司为其他公司提供咨询服务,帮助他们改进流程,或者帮助建立一个 BI 系统,让他们能自己做出商业决定。
那段时间,从大学刚毕业的我是这么想象我的工作内容的:我来到公司,拿设备,有人会向我解释我必须做什么,我还会根据他们的要求开始我的工作。
但我第一天上班时,我拿到了 Ralph Kimball 写的《数据仓库工具包》一书,我的经理让我阅读和学习这本书。所以,我开始阅读并试图理解这本书的内容。我花了一些时间,但不记得具体花了多长时间,但至少需要一周左右的时间才能正确的理解这本书想要传达给我的正确内容。
术语表
你可能会在本文中找到一些需要解释的术语:
- 暂存区(Staging area)——我们在 DWH的同一数据库/机器上的原始/源数据的副本
- 转换区(Transformation area) — 转换之后的暂存数据。准备加载到 DWH。
- 事实表(Fact table) — 基于度量或基于事件的数据。比如销售信息、仓库产品的变动。
- 维度表(Dimension table)– 一个特定事物的所有信息。如所有与产品相关的信息、客户信息。

本文涵盖的方法:
- 金博尔方法论 (Kimball methodology)
- 英蒙方法论 (Inmon methodology)
- 资料库 (Data Vault)
- 数据湖 (Data Lake)
- 数据湖屋(Lakehouse)
金博尔方法论 (Kimball methodology)
我会从这个我最先学到且最容易理解的的技术开始我的分享。
金博尔方法论(Kimball methodology)是由Ralph Kimball 和他的同事创建的(因此而得名)。这种方法被认为是一种由下而上的设计方法。对于一般用户来说,他们可能会更熟悉维度建模(dimensional modeling)。
但是就我个人而言,我更喜欢这个建模,因为它更容易设计和分析。金博尔方法论,目的是回答特定问题或帮助理解特定领域(比如人力资源、销售)。这种方法能够被快速开发,但我们也会失去一些灵活性。通常来说,我们需要重建 DWH(或其某些部分)来更改应用。大多数 BI 报表工具都可以使用这个模型,你还可以快速拖放报表(即 MS SQL Server Analysis Services、Tableau)
金博尔流程 (Kimball flow):
- 从源系统加载数据到暂存区
- 转换数据
- 加载star/snowflake Schema
我将在下面的部分中更详细地介绍 Star 和 Snowflake Schema。
Star Schema
在 Star Schema 中,我们有一个事实表和维度表(带有事实表中的所有Foreign Keys)。简而言之,看起来像这样:
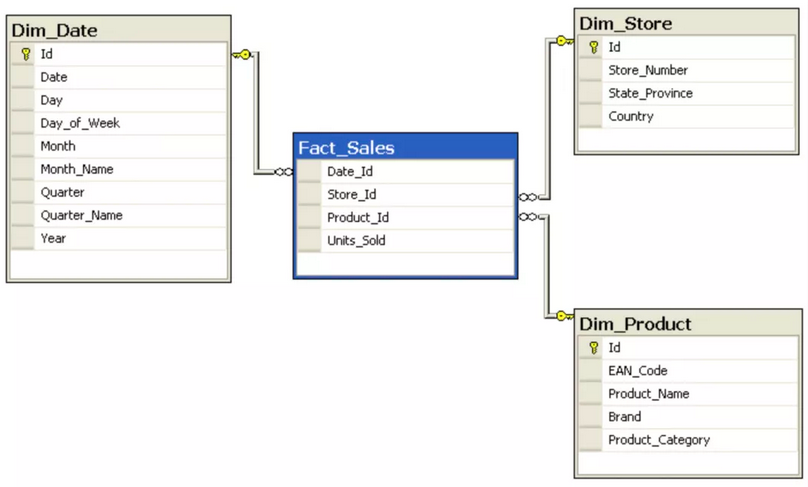
优点:
- 如果我们想对某些维度进行过滤时,速度会更快(不需要多个join)
- 建模简单(无需标准化)
- 缺点:
- 我们需要更多空间来存储事实表中的所有维度foreign keys。
- 为事实表添加维度键更费力(如果文件很大,更新将需要更多时间)
Snowflake Schema
Snowflake Schema是具有更多层的星型模式。例如,我们在商店维度中有一个地址。我们可以使用 address_PK 创建一个地址维度,它将指向 dim_shop。Snowflake Schema的简化视图如下:
优点:
- 减少在现有维度上添加附加层或分组的麻烦
- 更少的存储空间
缺点:
- 更难过滤数值(可能需要更多join)
我并不是说哪种建模比另一种更好;这一切都取决于用例、可用资源和最终目标。在选择时,我们要权衡所有选项,并考虑是否要向维度添加更多分组,稍后是否要添加更多原子层(使用维度表的foreign keys更新事实表)。
英蒙方法论 (Inmon methodology)
我没有在实际中使用过这个方法,所以这是一个更理论性的概述。
这种方法是由 Bill Inmon 创建的,被人们认为是一种自上而下的方法。我们必须有一个完整的概念,并根据 3NF(标准形式)对其进行建模,这使得这种方法比 Kimballs 更复杂。这种方法的缺点是,你需要熟练的人员来设计此数据模型,并将所有主题领域集成到其中。与 Kimballs 相比,英蒙方法论需要更多的时间来运行,但同时更容易维护,而且它更像是一种企业级方法。
英蒙流程(Inmon Flow):
- 将数据从源加载到暂存区
- 将数据添加到兼容3NF的 EDW(企业级数据仓库)
- 在 EDW 之上构建数据集市
要将这些所有公司/业务领域数据进行比较,我们需要建模。以我的个人经验为一个例子,我的第一个项目来自一个零售客户。我们用Star Schema在 Kimball 上做了一个模型,因为我们知道客户的需求和他们的数据问题。如果客户想在他们的 DWH上有更多的集成,比如join某些天工作的员工,库存管理,那这时候Inmon approach会更加适用。
在我看来,如果一家公司很小,而且他们只想跟踪和改进某个元素——通常来说,采用 Kimballs 的方法会更容易、更快。
资料库 (Data Vault)
从小公司跳槽到大公司对我带来了深远的影响。这帮助我更好地理解到了,有时我们需要一个更好、更简化的 EDW。在那时,我开始使用 Data Vault。我认为,它是 Kimballs Star Schema 和 Inmons 方法论的结合,且两全其美。
接下来,我将分享Data Vault 的几个最重要的组件。
Hubs
Hub 是所有不同实体的集合,比如对于帐户中心,我们有一个account、account_ID、load_date、src_name。因此,我们可以跟踪记录加载最初的数据来自何处,以及是否需要从业务密钥中生成代理密钥。
Links
链接是不同hubs之间的链接。也就是说,我们有员工,他们属于各个团队。团队和员工有不同的hub,所以我们可以有 team_employee_link,它会带有 team_employee_link、team_id、employee_id、load_date、src_name。
Satellites
他们会缓慢改变特定实体属性的维度。例如,我们有一个产品作为一个实体。我们有多个产品信息栏,包括名称,价格等等。因此,我们要将这些信息作为一个缓慢变化的维度加载,其中包含信息 product_id、open_date、close_date、is_deleted、product_name、product_price。通过捕获所有更改,可以帮助我们重新创建数据快照,并查看它是如何演变的。
除了这些最基本的实体,我们还有Satellite Links, Transactional Links.。这里我不会详细介绍这些;如果你想了解更多信息,你可看看 Dan Linstedts 网站或维基百科。
数据湖 (Data Lake)

在我还是只有简单的数据背景时,我遇到了一个叫数据湖的术语。数据湖存储了我们拥有的所有信息(结构化和非结构化)。如今,像大数据、数据湖这样的术语越来越受到关注。在我开始处理大量不同类型的数据之前,我不明白为什么我们需要存储这么多不同类型的数据。如今,数据是现在和未来的黄金。根据我对所有数据驱动型公司的了解,数据湖几乎是这些公司的必备条件。这些公司会尽可能多地存储然后进行分析,并寻找启发。
以原始格式的方式存储多源的数据是有其自身的成本的。
如果你不密切关注并妥善管理数据湖,那么这个数据湖可能会变成“数据沼泽”。
在我看来,数据湖是创建 EDW 之前的附加层。你会有数据工程师不断将原始数加载入数据湖。并在这之上构建 EDW。同时,分析师也可以通过根据预处理和清理过的数据来开展工作。
数据湖屋 (Lakehouse)
Databricks 公司在 2020 年 1 月末引入了这个术语。原理是,我们会直接在源数据上开展所有事情。大多数 ML/AI 工具更适合非结构化数据(如文本、图像、视频、声音)。将这些数据处理到 DWH 或 Data Lake 需要一些时间,并且大部分的时间内会超过预期。
我对这种方法目前保持怀疑态度。Lakehouse就像创造了一个巨大的数据沼泽,让人们淹没在其中。太多未经管理、清理的数据可能会导致并产生错误的假设,且不会成为大公司的真实数据来源。目前为止,虽然流媒体不是什么特别大的事,但我认为,我们还是需要等Lakehouse这个方法发展地更加成熟。但是,如果你是一家科技创业公司,而且想要在竞争中遥遥领先并使用前沿技术,你可以尝试用用这种方法,但这只是我的假设。

总结
在我看来,所有这些方法论都会长期共存。这一切都取决于每个公司和它自身的特点!
如果公司是一家中小型企业,那么老派的数据仓库方法就足够满足你的需求,这时,为什么要去选可能不会为你带来更多利润的东西呢?
如果是大型企业,且你想保持竞争力并为客户提供优质服务,那么数据湖可能是必不可少的。在我看来,你仍然需要创建一个预处理层,这将会成为数据报告的某种真实来源,且具有更多的聚合/清理数据。在我看来,这里最适合的是 Star 或 Snowflake Schema。这两个方法将使我们能够更快地寻找一些常见的模式和趋势。如果我们需要深入研究,而 DWH/Datamart又 过于聚合——那我们可以选择去数据湖检查原始数据。
或者,也许你的员工非常精通技术,而你是一家下一代科技初创公司,你想通过在使用前沿技术的同时,提供洞察力来击败竞争对手——那也许,你需要一个Lakehouse。不幸的是,我目前还没有看到Lakehouse真正成功适用的案例,不清楚要如何把Lakehouse与旧方法结合在一起工作,从而进行更清晰、更流畅的分析。
感谢你的阅读!希望本文让你对数据建模有了更深入的了解。你还可以订阅我们的YouTube频道,观看大量数据科学相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Tomas Peluritis
翻译作者:Lia
美工编辑:过儿
校对审稿:Jiawei Tong
原文链接:https://towardsdatascience.com/guide-to-data-warehousing-6fdcf30b6fbe





