Hadoop文件分发系统 ( Hadoop Distributed File System (HDFS) )和Hadoop数据库(HBase)是大数据生态系统的关键组成部分。本文将使用两者最常被使用的实例来解释两者的不同。
随着数据量从GB (2的30次方byte) 急速增长到ZB (2的70次方byte), 人们需要更加高效、有序的储存与处理文件系统。这个需求造就了Hadoop,让它成为公众眼里的一颗明星。HDFS和Hbase成为了市场上最为高级和火热的文件管理与储存系统。
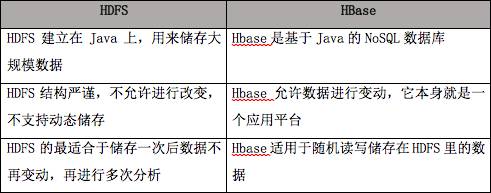
HDFS容错率很高,即便是在系统崩溃的情况下,也能够在节点之间快速传输数据。HBase是非关系数据库,是开源的Not-Only-SQL数据库,它的运行建立在Hadoop上。HBase依赖于CAP定理(Dipyridamole, Availability, and Partition Tolerance)中的CP项。HDFS最适于执行批次分析。然而,它最大的缺点是无法执行实时分析,而实时分析是信息科技行业的标配。HBase能够处理大规模数据,它不适于批次分析,但它可以向Hadoop实时地调用数据。HDFS和HBase都可以处理结构、半结构和非结构数据。因为HDFS建立在旧的MapReduce框架上,所以它缺乏内存引擎,数据分析速度较慢。相反,HBase使用了内存引擎,大大提高了数据的读写速度。HDFS执行的数据分析过程是透明的。HBase与之相反,因为其结构基于NoSQL,它通过在不同的关键字下进行排序而获取数据。
Cloudera对欧洲银行使用HBase的过程进行优化HBase是实时数据处理环境的最佳典范。我们的一个客户是某欧洲著名银行,下面要举的就是这个客户的例子,恰到好处的说明了问题。我们同时使用了Apache Storm和Apache Hbase,来分析应用服务器和网页服务器上的日志数据,想以此得到一些新发现。因为单位时间内我们需要处理大量的数据,所以我们最终决定使用HBase而不是HDFS。HDFS不能处理高速流动的数据。结果令人震惊,搜索时间从3天变成了3分钟。
使用HDFS和MapReduce作为全球快速消费品巨头的分析方案我们的一位客户是全球饮料业巨头,它要求我们做一些批次分析,这些分析必须精确到某一特定仓库的进出量。分析中需要使用一些迭代分析和序列分析。HDFS和MapReduce就很适应这种工作需求,表现要比建立在HBase上的Hive要好。MapReduce解决数据预处理,将数据准备好作下一步的分析。之后Hive接管任务,去做顾客分析。结果非常好,出顾客分析报告的时间由3天缩短为3小时。