当我们想起大数据时,我们往往想到互联网:几十亿的社交网络用户,上百万的移动手机的传感器,成千上万维基百科的编辑条目等等。随着科技创新的发展,海量数据也可能来自被植入大脑的相机终端。分布式计算领域取得的新进展正在改变神经科学家获取及处理数据的方式,而这个过程,同时也改变着我们对计算的看法。
大脑由许多神经元组成:一只苍蝇或一条斑马鱼有数十万的神经元,老鼠有数百万,而人类,有数十亿的神经元。它的功能取决于神经元的活动,以及它们之间相互通信的模式。长期以来,神经活动的记录范围被限制在几个神经元内,但是新近取得的进展使得同时监测数千个神经元成为可能,在某些生物体中(如斑马鱼),甚至可以监测到整个大脑的反应。
目前许多的监测方法都基于光学:通过基因工程的改造,动物的神经元能在活跃时发亮。我们在它们进行各种行为的时候,通过特殊的显微镜可以捕获这些行为模式的图像取得数据。目前,这些数据达到了每小时TB的量级,给数据的分析和理解带来了巨大的挑战:大量数据清理、整合以及数据分析工作。例如,我们需要通过不同的方法来查看每个数据集:将神经反应与动物行为或实验方案相关联,或者通过大量的相关行为进行模式识别。和传统数据方法不同的是,这种探索式的数据分析模式让我们从来不知道答案 – 有时我们甚至不知道从哪里开始。
这让我们对探索大数据的技术有了更高的要求,尤其在交互性和灵活性方面。过去的数据分析局限在单一的工作站上,比如在一台高配置的机器上运行Matlab,十分限制数据的规模的发展,而分布式计算解决方案打破了这一局限,在数据规模上拥有更大的优势。
1. Spark基于内存的集群运算使其能在数秒钟或数分钟内将大型数据集分解,进行并行查询,从而加速数据探索过程
2. Spark提供兼容Scala, Java和Python的API,更灵活直观。尤其是Python的API,使我们将Spark与现有的各种用于科学计算(NumPy,Scipy,scikit-learning)和数据可视化(purinethol,seaborn,mpld3)的python工具相结合。
以Spark作为大规模计算的平台,我们正在开发一个完全基于Python、模块化、面向用户的开源代码库-Thunder,用于分析时间空间数据。
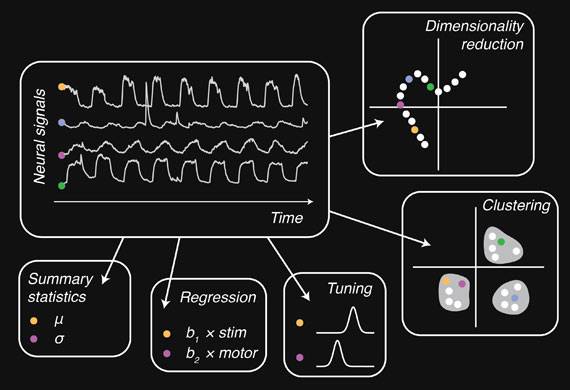
许多探索性数据分析都曾用于发现神经数据的模式,包括从多个神经元或记录通道中获取的时间序列数据。资料来源:大规模集群计算绘制大脑活动
我们的许多分析通过将大脑反应与外部世界的属性相关联来创建大脑的统计“地图”。例如一条斑马鱼表现出向不同方向移动的模式,我们就可以通过捕获每个神经元的响应,计算出神经元响应与不同方向的映射关系。这很像投票偏好的统计地图:人们投票给候选人,神经元投票给不同的方向。在另一个案例里,我们比较了动物对游泳的神经元反应,发现大部分大脑在动物游泳时反应剧烈,但有些部分的神经元反应却发生在不游泳的时候 – 这些神经元的功能仍然是一个谜。
顶部:方向选择性的全脑图。每个神经反应已经基于响应最大的移动视觉刺激的方向着色。底部:全脑低维动态嵌入。每个迹线表示在单个刺激的呈现之后,大脑中的活动如何演变。在左下角,颜色表示刺激的方向,而右侧的颜色表示时间的流逝。资料来源:大规模集群计算绘制大脑活动
虽然地图映射是静态的,但由于神经元的活动随着时间的推移而变化,我们的数据实际上是动态的,使得数据量非常庞大。尽管现在有一系列关于降低维度的算法,能将高维时间序列数据转化为记录关键动态属性的低维数据,但很多需要遍历整个数据集的分析依然依赖于分布式计算。
我们相信神经科学和数据科学之间的影响是相互作用的。从长期目标来看,我们一方面希望能通过使用分布式计算技术来发现神经编码的原理。大多数神经科学家都同意大脑是一个高效的计算引擎:比起笔记本电脑,大脑消耗更少的电力,却可以在几毫秒内识别一个对象,导航一个充满障碍的环境,并协调精密的运动计划。另一方面,我们相信理解神经编码的原理将反过来刺激人工智能的进步。事实上,所谓的神经网络,包括最近兴起的深层信念网络,都是模拟了大脑的架构:它们由很多神经元组成,这些节点相互传递信号。这些网络在部分领域,比如图像和语音识别方面,做的非常出色。
然而,这些神经网络和真正的大脑之间仍然存在着很大的差距。例如,在大部分的人工神经网络里,每个节点只是重复一样的行为,而大脑的活动非常多样化。它们由成千上万的神经元组成,每个神经元具有不同的形态,功能,连接方式以及交流形态。真正生命体的神经元并不是为了解决特定的任务而独立存在,它们相互关联(例如人脸识别),并快速的与不断变化的世界进行动态的交互。这种神经元的多样性的作用以及生物计算的基本原理仍然是一个谜,但是大量的绘制整个神经系统的活动,系统的描绘神经元形态和连接图谱有助于加速我们对大脑活动的理解。
从短期来看,神经科学研究和计算,数据挖掘及人工智能领域的相互影响也存在。一方面,神经科学家收集的海量数据不仅在数据量,更在数据的复杂度上影响了其他领域的数据规模。另一方面,相似的数据特性使神经科学领域在引领着数据科学和机器学习的发展的同时也从中获益,进一步促进自身的发展。例如,神经科学的映射分析和大型卫星图像数据或地理统计数据分析就非常类似。另外,我们的数据是大量的时间序列数据,其数据结构与网站产生的实时用户信息,或者从我们家里甚至身体中收集的实时传感信号也非常类似。
无论神经科学或是数据科学领域,科学家们都在各个方面面临着相同的挑战:数据预处理,分布式存储,模式发现算法及可视化。我越来越相信,这些领域的专家可以并且应该团结在一起,共同迎接这些挑战。
原文作者Jeremy Freeman,撰文于09/08/2014