
Data Scientist是怎样做Outlier Detection的?
今天我们来学习一个很重要的话题:Data Scientist是怎样做Outlier Detection的?主要会介绍到Outlier产生的原因,有哪些技术方案和方法可以帮助我们检测?会带大家一起demo几个项目,用不同的方法检测Outlier在不同的领域的应用。如果你想了解更多关于数据科学的相关内容,可以阅读以下这些文章:
职场转型与进阶:多年非Data相关工作经验,如何转行数据科学家?
初级与高级数据科学家有什么区别?
如何明确和解决模糊的数据科学问题?
构建数据科学管道的 4 个步骤
什么是Outlier?

Outlier可以理解为在一个数据集里作为一个现象的Observation,这个Outlier是一系列数据当中和别的数据没有完全匹配成一个规律,也可以认为Outlier离正常的数据集分布的距离比较远。
Outlier大概分为哪几种类型?
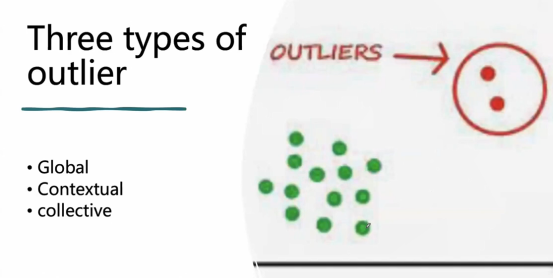
基本上来讲包括三种类型:Global、Contextual、Collective。

首先Globa Outlier就是说,有一个点,从全局来讲和其他正常的点都有很大的距离,这个时候可以相对容易的找到这种现象,也就是怎么去评估这个点和别的点的差别。

第二种Contextual Outlier是一种基于上下文的情况,是在特定环境下的比较,它的主要问题就是怎样去定义上下文。

如上图这种,我们可以理解为Collective Outlier,在日常的数据分析中,这几种现象都会发生,都是在分析Outlier时候的重要步骤,需要理解Outlier产生的原因以及作用的类型。

那么有哪些技术可以帮助我们处理Outlier?上图片中列举了四种技术类型。
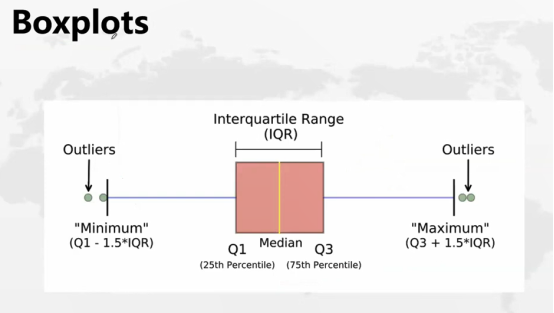
Minimum:Q1-1.5*IQR
Maximum:Q3+1.5*IQR
这两个值在统计中是常用的,而Minimum或Maximum之外的数据被称为异常值。
另一种方法是标准差。如果样本服从正态分布,左右会产生长尾,这些数据也可以称之为异常值。这就是统计中单变量的数据分布。

异常值还有其他方法,特别是多变量、复合型的Outliers,可以将异常检测视为分类器问题,使用现有的数据训练模型,比如KNN、RF、GBDT、SVM、XGBoost等。但是这种方法仍有一些挑战,比如不平衡数据的分类,在做无监督机器学习时,二分类算法中类别所占数据1:1,可以更好地学习正反两种数据的规律,但是并不是所有案例中的数据都是1:1的。

无监督机器学习中的数据是没有label的,其中使用最多的算法是聚类。如果是正常的数据,彼此距离较近,但是异常值据距离一簇数据中较远。常见的算法有IsolationForest、DBACAN、Local Outlier Factor(LOF)等。

LOF是定义距离某点最近的第k个点的距离和点的第k距离,据此划定可达距离(RD),再计算点的局部可达密度(LRD)。根据下图了解具体内容:

图中黑点是数据点,异常值使用红圈圈出来,左下方和右上方有两簇点。首先定义某一个点到k个邻点的距离,计算每个点的这个距离,然后计算距离范围内点的密度,如果是一个点距离簇较远,且同周边邻点的距离是相对稀疏的,那么该点就是一个异常值。
下面来看Semi-Supervised的方法,也可以把它叫做混合型方法。混合型方法的主要思路是一部分用supervised的方法,一部分用unsupervised的方法,unsupervised的方法是可以提供一些簇就是正常的数据集;然后再使用supervised的方法构建一个特定的模型去检测非正常的情况。
在Deep Learning里面也是可以检测outlier非正常的情况。包括AE(AutoEncoder)、VAE(Variational AutoEncoder)、GAN等方法。
我们主要讲了处理outlier的几种方法,包括一个变量的和多个变量组合的,看了outlier一些不同的类型,还要注意产生的原因。以及一些常见的方法包括统计的方法、机器学习和深度学习等方法。
感谢阅读,本文我们主要讲了处理outlier的几种方法。你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
Recap 作者:数据应用学院
美工编辑:过儿
校对审稿:Miya
公开课回放链接:https://www.youtube.com/watch?v=QNoLsHWODEI&t=47s





