
如何在一小时内将查询运行时间从30分钟缩短到30秒
尽管日益复杂的网络攻击令人恐慌,但破坏数据基础设施最快的方式之一并不是充满恶意的。你所需要做的就是将你的摄取过程引入新的内容,通常是在表的架构中。
一个新类型,一个新字段,或者一个完全消失的字段。
以下的查询优化案例并不是从疯狂的Slack消息开始的,这些消息暗示着一个瘫痪的管道。这不是对上游无意添加的字段的回应。这一切都源于数据工程师同事每周都会收到的一个请求:“你能添加这个新字段吗?”
由于这个用例是受到工作的启发,我不能提供关于具体数据和请求的详细信息。不过,我可以告诉你,这是一个作为补充id的字符串字段。在添加这个字段之前,我创建的视图执行时间不到15秒,因为它每天处理的数据量非常小(不到10,000行)。
但这很快增加到了30分钟。
以下是(近似)消耗的时段小时的跳跃表示。
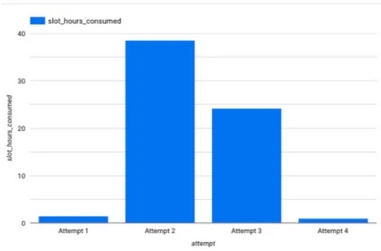
该视图最初由4个源表中的数据组成。它们有一个共同的键将它们联系在一起,这意味着我能够快速准确地创建原始视图。我错误地假设带入新字段将是一个快速的任务。而且,从理论上讲,确实是这样。
只需要3行新代码:
- 外层查询中的一个字段
- 一个新的表引用
- 一个新的JOIN子句(带有键)
-- Pseudo code representation
SELECT *, new_field
FROM (
SELECT
...
-- New row added here
table_5.new_field
FROM table_1
LEFT JOIN table_2 ON table_2.a_id = table_1.a_id
LEFT JOIN table_3 ON table_3.a_id = table_1.a_id
LEFT JOIN table_4 ON table_4.a_id = table_1.a_id
-- New table alias added here
LEFT JOIN table_5 ON table_5.a_id = table_1.a_id
)
GROUP BY ...
-- Adding field to the existing GROUP BY clause
new_field不幸的是,这个源表不小。与其他每天附加少量数据的表不同,这个表代表了一个更大的导出,大约每天500万行左右。根据你对“大”数据的经验,你可能仍然认为这很小。但让我强调一下,我们每天都在附加那么多行。根据历史记录,已经存储了超过10亿行。在大数据的世界里,这仍然不算太大,但当你尝试连接超过3个表时,它可能会使处理变慢,就像我所做的那样。
以前,我使用的是一个标准查询,其中包含几个子查询,深度为2-3层,包含在最终的SELECT子句中,就像你在上面的伪代码中看到的那样。
一旦我看到初始运行时间接近30分钟,我开始考虑采取那些从Learning SQL到StackOverflow都建议的查询优化步骤。
但我很固执,所以我说服自己可以保留我的原始查询结构和参数,只需为所有要查询的内容创建物化视图即可。不幸的是,这很快就变得一团糟,因为我必须先构思,然后提交代码更改,以便生成其余表格。
我很快就感到沮丧,开始调整查询的“内容”,别名所有的表,甚至尝试不同的JOIN类型。对包含多个子查询的查询进行调整就像我匆忙构思的物化视图策略一样混乱,因此我采取了重构的第一步:将子查询转换为CTEs。
-- Pseudo code representation of refactoring
WITH table_1 AS (
SELECT * FROM table_1
),
table_2 AS (
SELECT * FROM table_2
),
table_3 AS (
SELECT * FROM table_3
),
table_4 AS (
SELECT * FROM table_4
),
table_5 AS (
SELECT new_field FROM table_5
)
SELECT
...
FROM
table_1 LEFT JOIN table_2 ON table_1.a_id = table_2.a_id
LEFT JOIN table_3 ON table_1.a_id = table_3.a_id
LEFT JOIN table_4 ON table_1.a_id = table_4.a_id
LEFT JOIN table_5 ON table_1.a_id = table_5.a_id
GROUP BY
...你猜怎么着?
一点用都没有。
我的意思是,它对可读性肯定有帮助,但对性能没有帮助。这让人很恼火,因为把查询改写成CTE应该会自动减少执行时间吧?
虽然CTE可以帮助减轻一些初始处理负荷,但我的问题仍然是我需要连接的数据范围。我需要将多个较小的表连接到一个相当庞大的数据源。
因此,我没有修改更多代码,而是采取了可能是最重要的查询优化步骤:我考虑了我的基础数据。我考虑了它的固有范围及其与其他数据的关系。
当我在脑海中拼凑这些关系时,我意识到我的流程中存在大量冗余。
- 尽管我们追加了表1,但它本质上是一个映射表,不需要全部引用
- 表2-4也只是逐日追加少量记录
- 由于导出的性质,表5中的字段不会逐日变化,因此没有理由调出所有记录
所有这些思考都让我意识到一个关键问题:对于这些表中的任何一个,我只需要最近一天的数据。因此,我对每个表都使用了日期过滤器:
-- Pseudo code representation of refactoring
WITH table_1 AS (
SELECT * FROM table_1
WHERE DATE(update_date) = CURRENT_DATE()
),
table_2 AS (
SELECT * FROM table_2
WHERE DATE(update_date) = CURRENT_DATE()
),
table_3 AS (
SELECT * FROM table_3
WHERE DATE(update_date) = CURRENT_DATE()
),
table_4 AS (
SELECT * FROM table_4
WHERE DATE(update_date) = CURRENT_DATE()
),
table_5 AS (
SELECT new_field FROM table_5
WHERE DATE(update_date) = CURRENT_DATE()
)
SELECT
...
FROM
table_1 LEFT JOIN table_2 ON table_1.a_id = table_2.a_id
LEFT JOIN table_3 ON table_1.a_id = table_3.a_id
LEFT JOIN table_4 ON table_1.a_id = table_4.a_id
LEFT JOIN table_5 ON table_1.a_id = table_5.a_id
GROUP BY
...而执行时间回落到几秒钟(见尝试4)
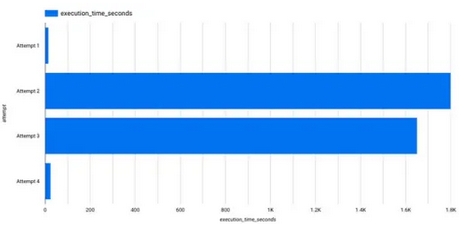
但仍然存在一个悬而未决的问题。虽然在最终输出中我得到了我期望的大部分行(少于50个不同的记录),但我的视图却遗漏了一些重要数据,因此导致报告不足。起初,我在视图定义中开始排除故障,但即使使用CTE,也很难辨认。
于是,我打开了一个单独的标签页,里面只有我想连接的两个表。经过几分钟的实验,我发现问题不在于数据,甚至也不在于连接键。我的问题在于JOIN子句中表别名的顺序。
请记住,最佳做法是将较大的表放在连接的左侧。
最后一个问题解决后,我对数据的性能和准确性又恢复了信心。
我经常看到有人抽象地介绍查询优化技巧。说(或写)“将查询转换为CTE”或避免“CROSS JOIN”很容易。但是,正如我希望我已经证明的那样,盲目尝试其中一个技巧并不是解决优化问题的万灵药。
实际上,最好的查询优化方法是极简主义。问问自己:我可以处理的最少行数是多少,以便数据及时而准确?
感谢阅读!你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Zach Quinn
翻译作者:Qing
美工编辑:过儿
校对审稿:Jason
原文链接:https://medium.com/learning-sql/how-i-reduced-my-querys-run-time-from-30-min-to-30-sec-in-1-hour-01c19efa7ed0



