
如何在不花一分钱进行A/B Testing?一起来薅资本主义羊毛!
A/B Testing是产品开发过程中不可或缺的一部分,从需求增长的营销人员到设计师都在使用。然而,并不是每个人都有一个合适的A/B测试平台。也许你负担不起一个一年高达10万美元的系统,或者你是一个喜欢自己提取和处理数据的纯粹主义者。无论如何,本指南将揭开这个过程的神秘面纱,一步一步教你如何获得重要的结果。
什么是 A/B Testing?
A/B Testing或统计假设检验基本上是比较某事物的两种版本,以找出哪种效果更好的实验。有趣的事实是: 早在20世纪初,吉尼斯黑啤酒的统计学家威廉·戈塞特 (William Gosset) 就使用了A/B Testing来测试哪种大麦的收益最适合啤酒生产。
它能起到什么作用?
A/B Testing 是一种任何人都可以依据他们的目标而使用的工具。
· 产品经理可以测试定价模型的变化,以提高收入或优化漏斗的一部分(例如,新用户注册和引导流程),以增加转化率。
· 营销人员可以测试图像、CTAs、营销活动或广告中的任何元素,以提高打开率和点击率。
· 产品设计师可以测试设计决策(例如,checkout按钮应该是红色还是蓝色),或者在100%推出之前,使用结果作为新特性的可用性的参考。
所以,在没有合适的测试平台的情况下,如何以正确的方式进行测试? 首先,在进行A/B测试之前,问自己以下这些问题。
可行性——我能做到么?
· 你有足够的用户和数据吗?太小的样本量要么需要长时间运行测试,要么给出不重要的结果。
· A/B测试也需要花费精力来设计、设置和运行。所以问问你自己,你有时间和资源(例如,开发人员来实现) 吗?更多信息请参见步骤4。
· 是否拥有收集数据并将其传输到正确的查询或分析平台的系统?
是否有提取,清理和分析数据的技能?
· 假设你没有专门的测试工具,需要用查询语言(例如:SQL)提取原数据,并以可读格式(例如:Excel)操作和显示数据。
适用性——我应该这样做吗?
这是检验假设或回答问题的最佳(最便宜、最快)方法吗?例如,如果您想知道为什么人们不完成表单,也许在半天的时间内做一些可用性测试要比3周的A/B Testing好。当铲子可以工作时,就不要使用推土机。
A/BTesting 6个简单的步骤
下面是你考虑运行测试时要经过的6个步骤。这个例子是一家B2C初创企业的注册页面的 A/B Testing,数字是虚构的。
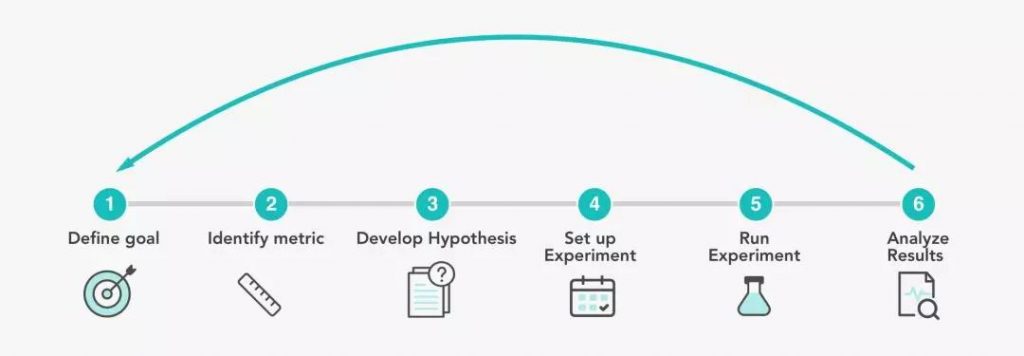
1. 定义一个目标
了解公司更大的业务目标,并确保你的A/B Testing符合这些目标。
· 举个“栗子”:你是X公司的产品经理,这家公司刚刚起步。执行团队已经制定了一个全公司范围内的目标,以提高用户增长。具体来说,该公司希望增加每日活跃用户(DAUs),即过去30天内该网站每天的平均注册用户数。你可以通过提高保留率(重复使用产品的用户的百分比)或增加新用户注册来实现这一点。
· 在研究过程中,你从漏斗分析中注意到,60%的用户在完成注册之前就退出了。所以你相信有一个很好的机会来提高注册页面的注册率。这同时也应该有助于提高DAU。
2. 确定一个度量
你需要确定一个度量标准来衡量新版本是否比原始版本更成功。这通常是某种转化率,但也可以是中间步骤,比如点击率。
· 示例:在本例中,你选择注册率作为度量标准,即注册的新用户数量除以站点的新访问者总数。
3.开发一个假设
你需要开发一个假设来解释正在发生的变化(例如:你想测试什么),结果和原理。
· 例如:比方说当前注册页面有一个图像和一个注册模式。这里有一些你可以测试的东西(例如,表单字段、定位、文本大小),但是图像在视觉上是最突出的,所以你想知道不同的图像是否会导致更好的注册率。
· 一般的假设是“如果注册页面的图像发生了变化,那么更多的第一次用户会注册该产品,因为该形象更好地传达了产品的价值。”
在正式的假设测试中,你需要定义两个假设,以帮助你确定所看到的版本A(原始版本)和版本B(要测试的新版本)之间的结果是自然变化的结果,还是你所更改的结果。
· 零假设(Null Hypothesis)假设A和B的结果没有不同,观察到的差异是由于随机性造成的。我们通常希望拒绝这一点。
· 备择假设(Alternative Hypothesis)是假设B不同于A,你想通过拒绝零假设来推断为真。
决定是单尾检验还是双尾检验。单尾检验允许你检测一个方向上的变化,而双尾检验允许检测两个方向上的变化(正负都有)。因此,单尾测试将帮助您确定B是否优于A,而双尾测试更适合测试两个完整的新设计(当不存在缺省值时),并将告诉您B的性能是否优于或低于A。
· 举例:我们的零假设和备择假设将会是:
· 零假设:新的注册页面(B)的注册率 ≤ 原始注册页面(A)的注册率
· 备择假设:新的注册页面(B)的注册率 > 原始注册页面(A)的注册率
· 我们将使用单尾检验,因为我们更感兴趣的是检测B的改进,而不是知道B什么时候表现得更差。
4. 建立实验
为了使测试有效,我们需要:
· 创建反映要测试的更改的新版本(B)。
提示:您还可以在多变量测试(MVT)中同时测试多个变量,但这只包括分割测试
· 定义对照组和实验组。您想测试哪些用户?所有平台上的所有用户?只有美国现有的网络用户?根据用户类型、平台、地理位置等定义相应的测试人群。然后,确定接受测试的人群中有多少比例是对照组(接受A的那一组),有多少是实验组(接受B的那一组)。一般这个比例是50/50。
· 确保随机性:用户随机获得A和B,这意味着每个用户获得A或B的机会均等。
· 定义显著性水平(α)。这是你接受假阳性(拒绝零假设时正确)风险的水平,通常为α= 0.05或5%。这意味着有5%的时间你可以检测到A和B之间的差异。这实际上是由于自然变化造成的。你的显著性水平越低,你发现由随机性引起的差异的风险就越低。
· 定义一个最小的样本大小。点击 这里有计算样本大小的计算器,可以计算每个版本所需的样本量。由于参数和假设的不同,您将得到略有不同的数字。
有足够大的样本量是重要的,以确保你的结果在统计上是显著的。
· 定义一个时间轴。取每个版本所需的总样本量,除以每天的流量,这将给出运行测试的天数。一般来说,比较好的经验法则是大约1到2周,但可能或多或少取决于其他因素的影响(包括流量规模或业务周期)。
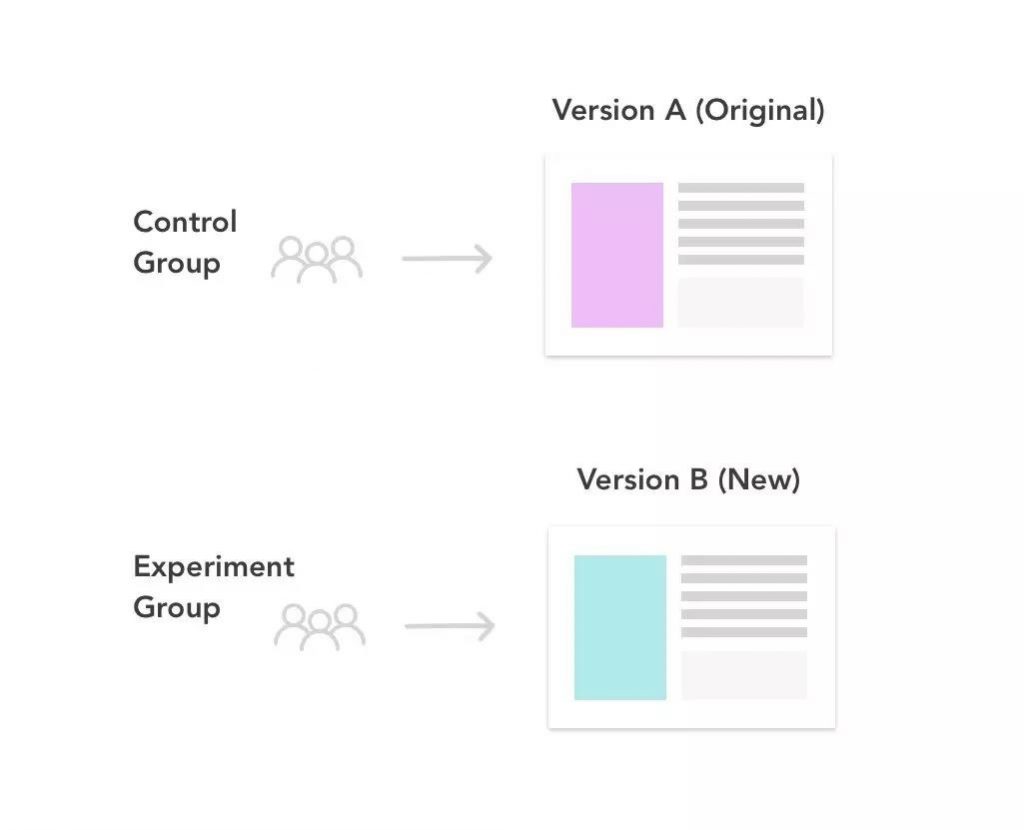
· 举例:
o 创造版本B:
我们会根据现有的注册界面设计一个不同图像的注册界面。
o 定义对照组和实验组:
因为我们对在web平台上注册的新用户很感兴趣,所以我们将根据用户类型和平台进行划分。只有访问浏览器注册页面的新用户才会接触到这个实验。我们还确保随机抽样,这意味着每个用户将有平等的机会收到A或B和随机分配。
o 控制组- 50%的第一次使用web浏览器登录页面的用户将看到原始版本A。
o 实验组- 50%的第一次使用web浏览器登录页面的用户将看到新版本B。
o 定义显著性水平:
我们将采用最佳实践,即显著性水平α= 0.05或5%。
o 定义一个时间轴:
假设我们的注册页面平均每天的首次用户流量为10,000/天。我们计算出每个变异的最小样本量约为100,000。这意味着每天只有5000名用户将收到每个版本。所以我们需要做这个实验100,000/ 5000 = 20天。
5. 运行实验
· 沟通预期的实验开始和结束日期,为您的团队或其他利益相关者设定期望。
· 执行质量控制——这经常被忽视,但很重要。
无论你是什么角色,都要学习如何自己进行基本的QA。
1. 与工程师确认实验设置参数正确。
2. 如果有测试查询来检查数据,请对操作环境进行测试查询。或者,您也可以检查实验第一天的数据。
3. 数据清理应包括检查:
(1) 完整性——空值、空格和丢失的数据可能是无害的,或者是错误实现的标志。
(2) 准确性——确保正确的用户操作触发了正确的事件,所有预期的字段和字段值都将进入。
4. 当它预计要上线时,检查一下它是否真的上线了。
5. 最后, 不要偷看结果!早期查看结果会使统计意义失效。为什么? 详情查阅这里。
6. 分析结果- 有趣的最后部分
· 收集和分析数据
您将需要提取数据并计算之前为版本A、B和差异定义的衡量参数。如果总体上没有区别,您可能还希望按平台、资源类型、地理位置等进行细分(如果适用的话)。您可能会发现版本B在某些方面表现得更好或更差。
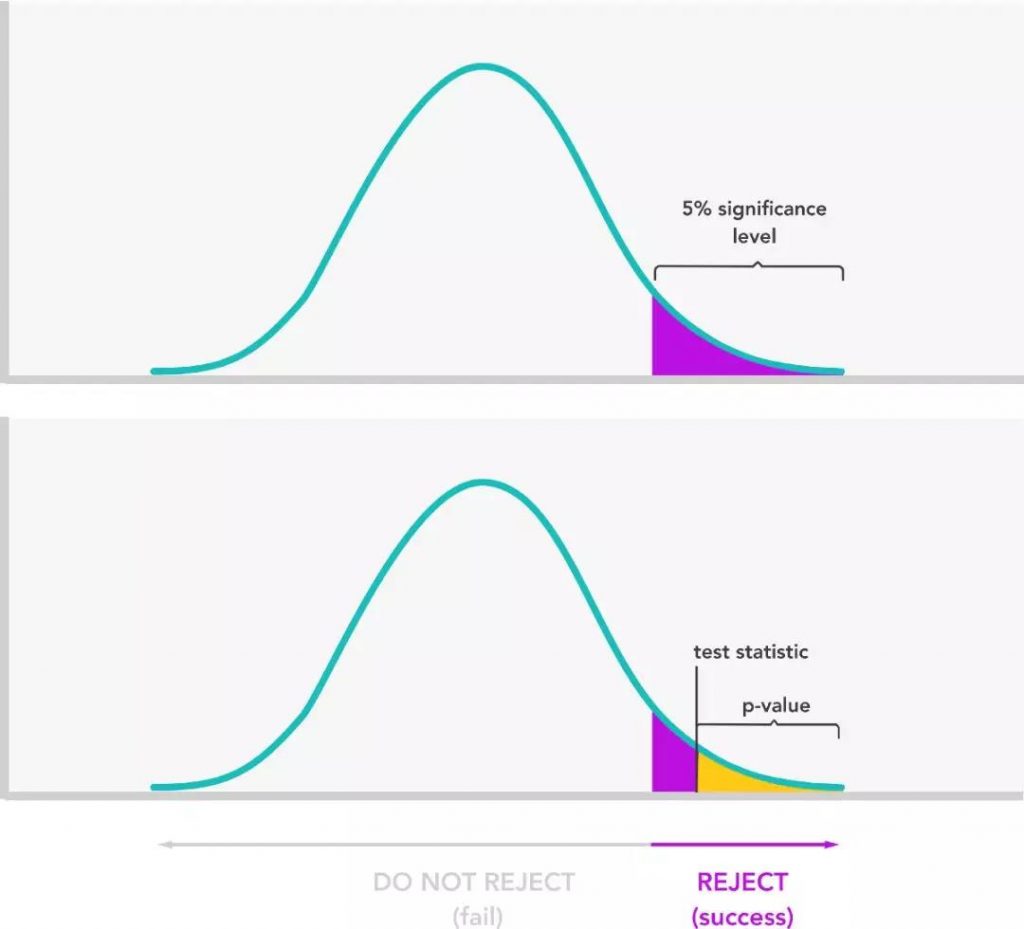
· 检验统计显著性
这种方法背后的统计理论在这里得到了更好的解释,但基本思想是找出A和B之间结果的差异是由于您所做的更改,还是由于随机性/自然方差。这是通过将测试统计数据(以及结果的P值)与您的显著性水平进行比较来确定的。
提示:你也可以认为统计学意义的信心水平只是1-α。最佳实践通常是将置信度设置为1-0.05 =0.95或95%。这意味着如果你重复测试100次,你会看到95次的结果。显著性水平和置信水平均可用于确定统计显著性,但本例使用显著性水平。
确定重要性的基本步骤是:
1. 计算测试统计量。测试统计量是我们用来比较A和b之间的结果的值。它说明了我们在结果之间看到的差异以及数据中的可变性。通常使用Z统计或T统计作为测试统计量,这取决于您对实际总体样本的了解。请阅读更多关于何时使用Z统计或T统计的信息,尽管如果样本量很大,这两种方法实际上没有什么区别.
2. 使用测试统计量计算p值。p值是A和B版本之间的结果差异完全由偶然因素造成的概率。很低的p值,比如1%,意味着A和B的差异不太可能是偶然的。这是根据测试统计数据计算出来的。你可能还记得在大学统计课上从表格中查找p值,但幸运的是,现在有在线计算器可以帮你做到这一点。
3. 将p值与显著性水平进行比较。
· 如果p值<显著性水平,我们可以拒绝原假设,并有证据支持备择假设。
· 如果p值≥显著性水平,则不能拒绝原假设。
示例:
收集和分析数据
因为我们想要能够比较A和B的注册率,所以我们想要收集关于FTUs的数量以及在20天内成功注册的FTUs数量的数据。
点击链接查看示例数据:https://gist.github.com/lisamxu/db6041895a0b96481f4f5b107b1c2101

表格显示了版本A 和 B 新用户注册率的对比
很好!看起来B的表现要比A好。但是在我们下结论之前,我们需要检查显著性。
检查统计显著性
我们会使用T检验,因为我们并不知道总体统计。如果你对总体和总体统计(例如,均值和方差)一无所知,你最好使用t统计,如果你知道可以用Z统计。
1. 计算t统计
我在这里使用了一个在线计算器,它也向你展示了公式和原始计算。
t统计量= 2.3665
2. 计算假定值
你可以使用p值计算器或Excel T测试公式TTEST,它将返回p值。记住,这是一个单尾双样本检验,显著性水平为0.05。
P值= 0.0115
3.将p值与显著性水平进行比较。
p值是0.0115 < 0.05
结果是显著的!
这告诉我们只有~1.15%的几率注册率的不同结果是偶然的结果。因此,我们可以推断出另一种选择(即B的注册率确实比A高)是正确的。
总结结论
你已经看了结果并检查了其显著性。A/B测试可以通过以下方式结束:
对于大多数测试,新版本的性能与原始版本相同或更差。
1. 控制A没有区别。排除可能导致无效测试的原因(例如,测试的结果不准确或不具备显著性),新版本的表现较差的原因可能是:
· 价值支柱的糟糕消息传递/品牌塑造
· 没有吸引力的价值支撑
· 糟糕的用户体验
在这个场景中,您可以深入研究数据或进行用户研究,以了解为什么新版本的性能不如预期。这将反过来帮助您进行下一次测试。
2. 版本B获胜。A/B测试支持您的假设,即版本B比版本A的性能更好。很好!在共享结果后,您可以将实验扩展到100%。关注成功和之后的背线度量是很好的。
在我们的示例中,我们得出结论,版本B的注册率确实高于版本A,因此我们将向所有用户推送版本B。然后我们将在未来几周监测注册率和DAU的增长。
把一切都包起来
不管你的测试是否成功,都要把每一个实验当作一个学习的机会。利用你所学到的知识来帮助你建立下一个假设。例如,您可以在前面的测试基础上进行构建,或者将精力集中在另一个领域进行优化。你所能测试和实现的可能性是无限的。
附:资源
A/B testing 的模板:Z statistic and T-test
T and Z 统计计算器:点击这里
原文作者:Lisa Xu
翻译作者:Haolin Kong
美工编辑:过儿
校对审稿:冬冬
原文链接:https://towardsdatascience.com/how-to-a-b-test-without-spending-a-dime-60c4112f8f4e





