
如何建立一个全自动的数据漂移检测管道
动机
当生产环境中的输入特征分布与训练数据不同时,就会发生数据漂移,从而导致潜在的不准确性和模型性能下降。
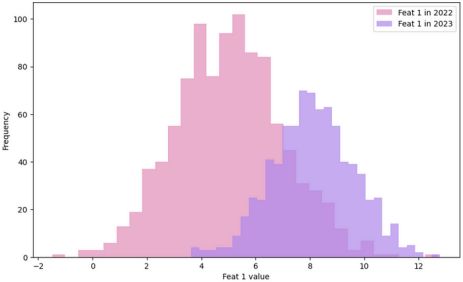
为了减轻数据漂移对模型性能的影响,我们可以设计一个工作流来检测漂移,通知数据团队,并触发模型再训练。如果你想了解更多关于数据科学的相关内容,可以阅读以下这些文章:
数据科学家必备:Git操作指南
从优秀到卓越:数据科学家的Python技能进化之路
每个数据科学家都应该避免的十大统计错误
每个数据科学家都应该知道的12个Python特性!
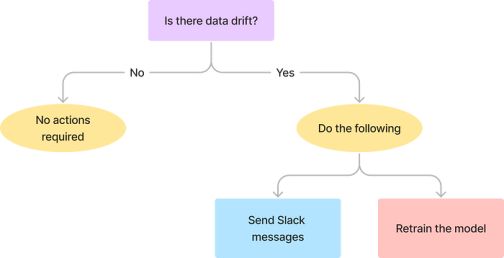
工作流
工作流包括以下任务:
1. 从Postgres数据库中获取引用数据
2. 从网上获取当前的生产数据
3. 通过比较参考数据和当前数据来检测数据漂移
4. 将当前数据附加到现有的Postgres数据库中
5. 当发生数据漂移时,采取如下措施:
- 发送一条Slack消息提醒数据团队
- 重新训练模型更新性能
- 将更新后的模型推送到S3进行存储
此工作流计划在特定时间运行,例如每个星期一上午11点。
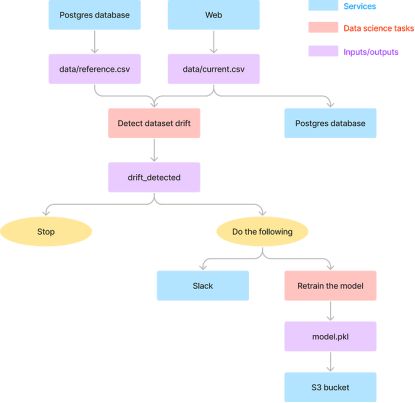
总的来说,工作流包括两种类型的任务:数据科学和数据工程任务。
粉红色方框表示的数据科学任务由数据科学家执行,涉及数据漂移检测、数据处理和模型训练。
由蓝色和紫色方框表示的数据工程任务由数据工程师执行,涉及与数据移动和发送通知相关的任务。
数据科学任务
检测数据漂移
为了检测数据漂移,我们将创建一个Python脚本,它接受两个CSV文件” data/reference. CSV “(引用数据)和” data/current. CSV “(当前数据)。
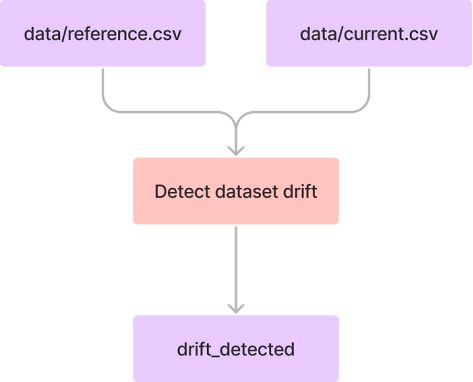
我们将使用一个开源的机器学习可观察性平台Evidently(evidentlyai.com),将参考数据作为基准,与当前的生产数据来进行比较,如果检测到数据集漂移,“drift_detected”输出将为True,否则,它将为False。
from evidently.metric_preset import DataDriftPreset
from evidently.report import Report
from kestra import Kestra
data_drift_report = Report(metrics=[DataDriftPreset()])
data_drift_report.run(reference_data=reference, current_data=current)
report = data_drift_report.as_dict()
drift_detected = report["metrics"][0]["result"]["dataset_drift"]
if drift_detected:
print("Detect dataset drift")
else:
print("Detect no dataset drift")
Kestra.outputs({"drift_detected": drift_detected})完整的代码:
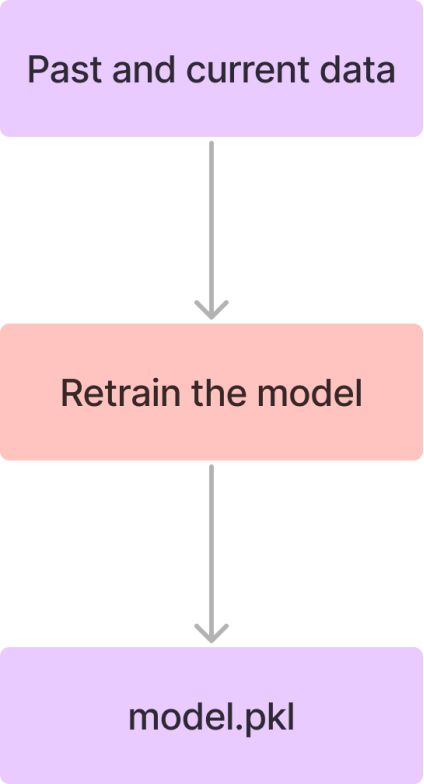
重新训练模型
接下来,我们将创建一个负责模型训练的Python脚本。该脚本将过去和当前的组合数据作为输入,并将训练好的模型保存为“model.pkl”文件。
def train_model(X_train: pd.DataFrame, y_train: pd.Series, model_params: DictConfig):
y_train_log = np.log1p(y_train)
model = Ridge()
scorer = metrics.make_scorer(rmsle, greater_is_better=True)
params = dict(model_params)
grid = GridSearchCV(model, params, scoring=scorer, cv=3, verbose=3)
grid.fit(X_train, y_train_log)
return grid
model = train_model(X_train, y_train, config.model.params)
joblib.dump(model, "model.pkl")完整的代码:
https://github.com/khuyentran1401/detect-data-drift-pipeline/blob/main/src/train/train_model.py
推送到GitHub
在完成这两个脚本的开发后,数据科学家可以将它们推送到GitHub,允许数据工程师在创建工作流时使用它们。
在这里查看这些文件的GitHub仓库:
GitHub – khuyentran1401/detect-data-drift-pipeline
数据工程任务
流行的编排库(如Airflow、Prefect和Dagster)需要修改Python代码才能使用它们的功能。
当Python脚本紧密集成到数据工作流中时,整个代码库可能会变得更加复杂和难以维护。如果没有独立的Python脚本开发,数据工程师可能需要修改数据科学代码来添加编排逻辑。
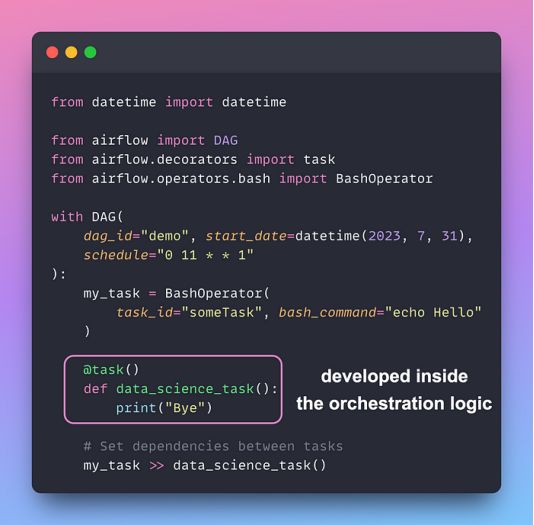
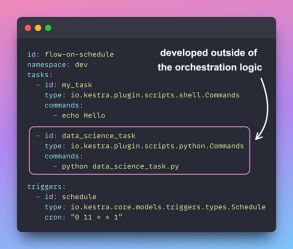
另一方面,Kestra是一个开源库,它允许你独立开发Python脚本,然后使用YAML文件将它们无缝地合并到数据工作流中。
这样,数据科学家可以专注于模型处理和训练,而数据工程师可以专注于处理编排。
因此,我们将使用Kestra来设计一个更加模块化和高效的工作流程。
克隆detect-data-drift-pipeline存储库以获取Kestra的docker-compose文件,然后运行:
docker compose up -d导航到localhost:8080以访问和探索Kestra UI。
按照以下说明配置本教程所需的环境。
在开发目标流之前,我们通过创建一些简单的流来熟悉Kestra。
从Python脚本访问Postgres表
我们将创建一个包含以下任务的流:
- getReferenceTable:从Postgres表导出CSV文件
- saveReferenceToCSV:创建可由Python任务访问的本地CSV文件
- runPythonScript:使用Python读取本地CSV文件
为了在saveReferenceToCSV和runPythonScript任务之间实现数据传递,我们将把这两个任务放在同一个工作目录中,方法是将它们封装在wdir任务中。
id: get-reference-table
namespace: dev
tasks:
- id: getReferenceTable
type: io.kestra.plugin.jdbc.postgresql.CopyOut
url: jdbc:postgresql://host.docker.internal:5432/
username: "{{secret('POSTGRES_USERNAME')}}"
password: "{{secret('POSTGRES_PASSWORD')}}"
format: CSV
sql: SELECT * FROM reference
header: true
- id: wdir
type: io.kestra.core.tasks.flows.WorkingDirectory
tasks:
- id: saveReferenceToCSV
type: io.kestra.core.tasks.storages.LocalFiles
inputs:
data/reference.csv: "{{outputs.getReferenceTable.uri}}"
- id: runPythonScript
type: io.kestra.plugin.scripts.python.Script
beforeCommands:
- pip install pandas
script: |
import pandas as pd
df = pd.read_csv("data/reference.csv")
print(df.head(10))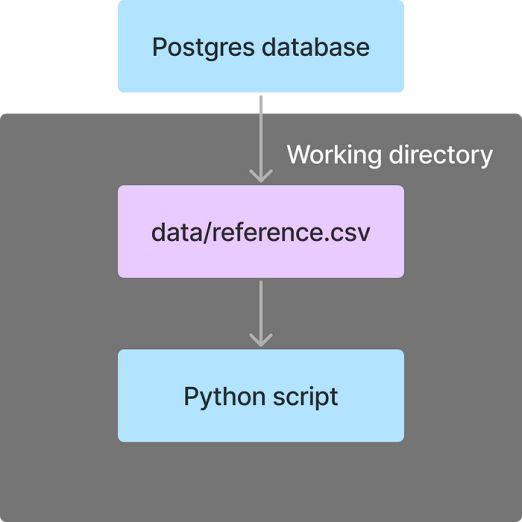
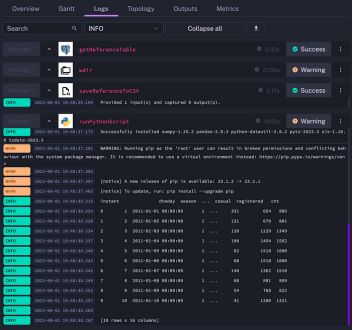
执行流程将显示以下日志:
输入参数化流程
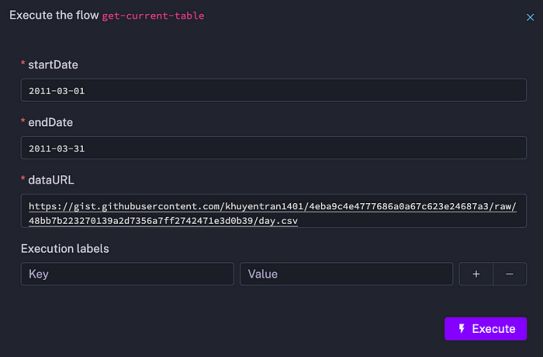
让我们创建另一个可以使用输入参数化的流。该流将具有以下输入:startDate、endDate和dataURL。
getCurrentCSV任务可以使用{{input .name}}表示法访问这些输入。
id: get-current-table
namespace: dev
inputs:
- name: startDate
type: STRING
defaults: "2011-03-01"
- name: endDate
type: STRING
defaults: "2011-03-31"
- name: dataURL
type: STRING
defaults: "https://raw.githubusercontent.com/khuyentran1401/detect-data-drift-pipeline/main/data/bikeride.csv"
tasks:
- id: getCurrentCSV
type: io.kestra.plugin.scripts.python.Script
beforeCommands:
- pip install pandas
script: |
import pandas as pd
df = pd.read_csv("{{inputs.dataURL}}", parse_dates=["dteday"])
print(f"Getting data from {{inputs.startDate}} to {{inputs.endDate}}")
df = df.loc[df.dteday.between("{{inputs.startDate}}", "{{inputs.endDate}}")]
df.to_csv("current.csv", index=False)
这些输入的值可以在每个流执行中指定。
加载CSV文件到Postgres表
下面的流程执行以下任务:
- getCurrentCSV:运行Python脚本在工作目录中创建CSV文件
- saveFiles:将CSV文件从工作目录发送到Kestra的内部存储
- saveToCurrentTable:将CSV文件加载到Postgres表中
iid: save-current-table
namespace: dev
tasks:
- id: wdir
type: io.kestra.core.tasks.flows.WorkingDirectory
tasks:
- id: getCurrentCSV
type: io.kestra.plugin.scripts.python.Script
beforeCommands:
- pip install pandas
script: |
import pandas as pd
data_url = "https://raw.githubusercontent.com/khuyentran1401/detect-data-drift-pipeline/main/data/bikeride.csv"
df = pd.read_csv(data_url, parse_dates=["dteday"])
df.to_csv("current.csv", index=False)
- id: saveFiles
type: io.kestra.core.tasks.storages.LocalFiles
outputs:
- current.csv
- id: saveToCurrentTable
type: io.kestra.plugin.jdbc.postgresql.CopyIn
url: jdbc:postgresql://host.docker.internal:5432/
username: "{{secret('POSTGRES_USERNAME')}}"
password: "{{secret('POSTGRES_PASSWORD')}}"
from: "{{outputs.saveFiles.uris['current.csv']}}"
table: current
format: CSV
header: true
delimiter: ","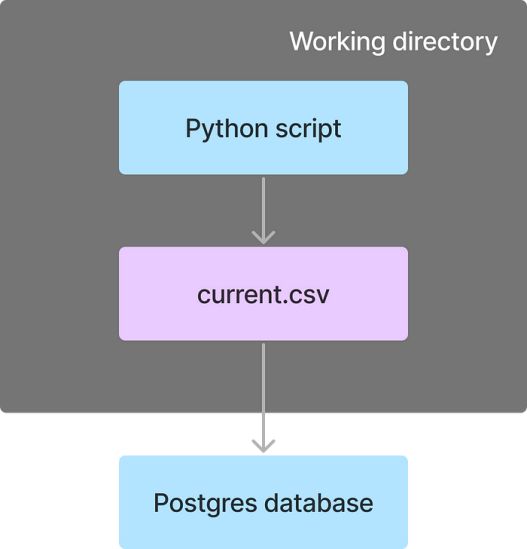
运行此流之后,你将在Postgres数据库中的“current”表中看到结果数据。
从GitHub存储库运行文件
该流程包括以下任务:
- cloneRepository:克隆一个公共GitHub存储库
- runPythonCommand:从命令行执行Python脚本
这两个任务将在同一个工作目录中运行。
id: clone-repository
namespace: dev
tasks:
- id: wdir
type: io.kestra.core.tasks.flows.WorkingDirectory
tasks:
- id: cloneRepository
type: io.kestra.plugin.git.Clone
url: https://github.com/khuyentran1401/detect-data-drift-pipeline
branch: main
- id: runPythonCommand
type: io.kestra.plugin.scripts.python.Commands
commands:
- python src/example.py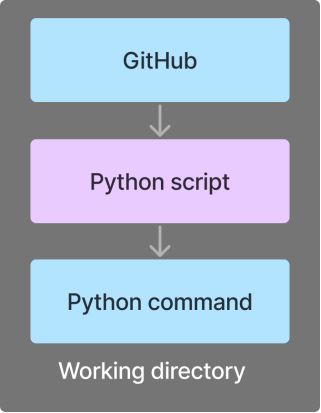
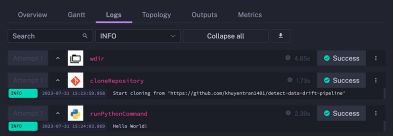
运行流程后,你将看到以下日志:
按计划运行流程
我们将创建另一个基于特定计划运行的流,以下流程在每周一上午11点运行。
id: triggered-flow
namespace: dev
tasks:
- id: hello
type: io.kestra.core.tasks.log.Log
message: Hello world
triggers:
- id: schedule
type: io.kestra.core.models.triggers.types.Schedule
cron: "0 11 * * MON"上传至S3
该流程包括以下任务:
- createPickle:用Python生成一个pickle文件
- savetoPickle:将pickle文件传输到Kestra的内部存储
- upload:上传pickle文件到S3存储桶中
id: upload-to-S3
namespace: dev
tasks:
- id: wdir
type: io.kestra.core.tasks.flows.WorkingDirectory
tasks:
- id: createPickle
type: io.kestra.plugin.scripts.python.Script
script: |
import pickle
data = [1, 2, 3]
with open('data.pkl', 'wb') as f:
pickle.dump(data, f)
- id: saveToPickle
type: io.kestra.core.tasks.storages.LocalFiles
outputs:
- data.pkl
- id: upload
type: io.kestra.plugin.aws.s3.Upload
accessKeyId: "{{secret('AWS_ACCESS_KEY_ID')}}"
secretKeyId: "{{secret('AWS_SECRET_ACCESS_KEY_ID')}}"
region: us-east-2
from: '{{outputs.saveToPickle.uris["data.pkl"]}}'
bucket: bike-sharing
key: data.pkl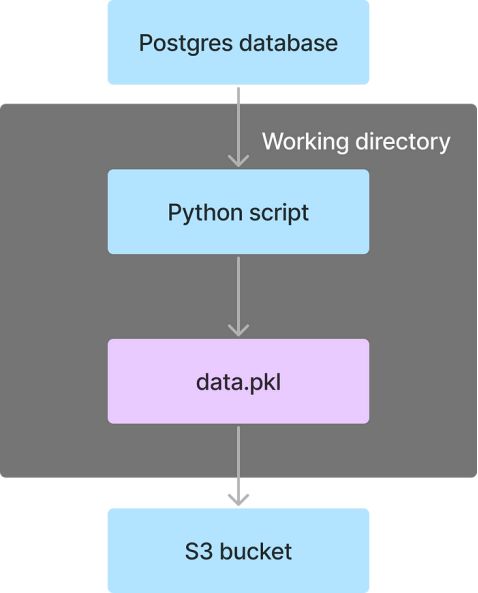
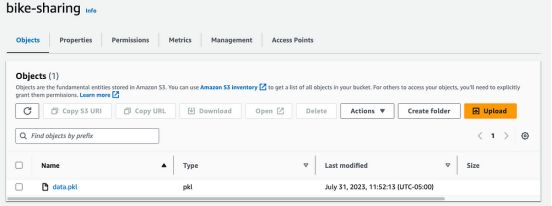
运行此流之后,data.pkl文件将被上传到“bike-sharing”存储桶中。
把所有东西放在一起
构建一个流来检测数据漂移
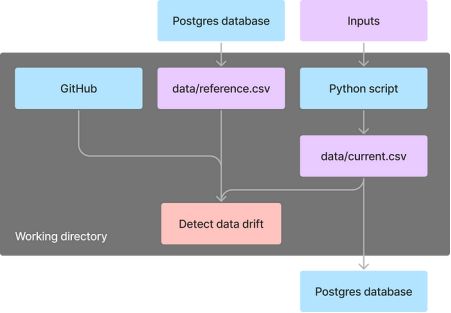
现在,让我们结合所学创建一个流来检测数据漂移,每周一上午11:00此流执行以下任务:
- 从Postgres数据库中获取引用数据
- 运行Python脚本从web获取当前的生产数据
- 克隆包含漂移检测代码的GitHub存储库
- 运行一个Python脚本,通过比较引用数据和当前数据来进行数据漂移
- 将当前数据追加到现有的Postgres数据库中
id: detect-data-drift
namespace: dev
inputs:
- name: startDate
type: STRING
defaults: "2011-03-01"
- name: endDate
type: STRING
defaults: "2011-03-31"
- name: data_url
type: STRING
defaults: "https://raw.githubusercontent.com/khuyentran1401/detect-data-drift-pipeline/main/data/bikeride.csv"
tasks:
- id: getReferenceTable
type: io.kestra.plugin.jdbc.postgresql.CopyOut
url: jdbc:postgresql://host.docker.internal:5432/
username: "{{secret('POSTGRES_USERNAME')}}"
password: "{{secret('POSTGRES_PASSWORD')}}"
format: CSV
sql: SELECT * FROM reference
header: true
- id: wdir
type: io.kestra.core.tasks.flows.WorkingDirectory
tasks:
- id: cloneRepository
type: io.kestra.plugin.git.Clone
url: https://github.com/khuyentran1401/detect-data-drift-pipeline
branch: main
- id: saveReferenceToCSV
type: io.kestra.core.tasks.storages.LocalFiles
inputs:
data/reference.csv: "{{outputs.getReferenceTable.uri}}"
- id: getCurrentCSV
type: io.kestra.plugin.scripts.python.Script
beforeCommands:
- pip install pandas
script: |
import pandas as pd
df = pd.read_csv("{{inputs.data_url}}", parse_dates=["dteday"])
print(f"Getting data from {{inputs.startDate}} to {{inputs.endDate}}")
df = df.loc[df.dteday.between("{{inputs.startDate}}", "{{inputs.endDate}}")]
df.to_csv("data/current.csv", index=False)
- id: detectDataDrift
type: io.kestra.plugin.scripts.python.Commands
beforeCommands:
- pip install -r src/detect/requirements.txt
commands:
- python src/detect/detect_data_drift.py
- id: saveFileInStorage
type: io.kestra.core.tasks.storages.LocalFiles
outputs:
- data/current.csv
- id: saveToCurrentTable
type: io.kestra.plugin.jdbc.postgresql.CopyIn
url: jdbc:postgresql://host.docker.internal:5432/
username: "{{secret('POSTGRES_USERNAME')}}"
password: "{{secret('POSTGRES_PASSWORD')}}"
from: "{{outputs.saveFileInStorage.uris['data/current.csv']}}"
table: current
format: CSV
header: true
delimiter: ","
triggers:
- id: schedule
type: io.kestra.core.models.triggers.types.Schedule
cron: "0 11 * * MON"建立一个发送Slack消息的流程
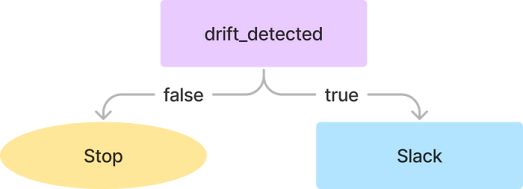
接下来,我们将创建一个流,当detect-data-drift流中的detectDataDrift任务返回drift_detected=true时,通过Slack Webhook URL发送Slack消息。
id: send-slack-message
namespace: dev
tasks:
- id: send
type: io.kestra.plugin.notifications.slack.SlackExecution
url: "{{secret('SLACK_WEBHOOK')}}"
customMessage: Detect data drift
triggers:
- id: listen
type: io.kestra.core.models.triggers.types.Flow
conditions:
- type: io.kestra.core.models.conditions.types.ExecutionFlowCondition
namespace: dev
flowId: detect-data-drift
- type: io.kestra.core.models.conditions.types.VariableCondition
expression: "{{outputs.detectDataDrift.vars.drift_detected}} == true"在运行detect-data-drift流之后,send- Slack -message流将在Slack上发送一条消息。
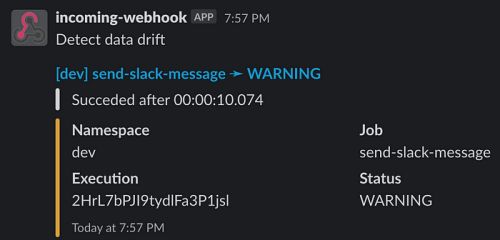
构建流来重新训练模型
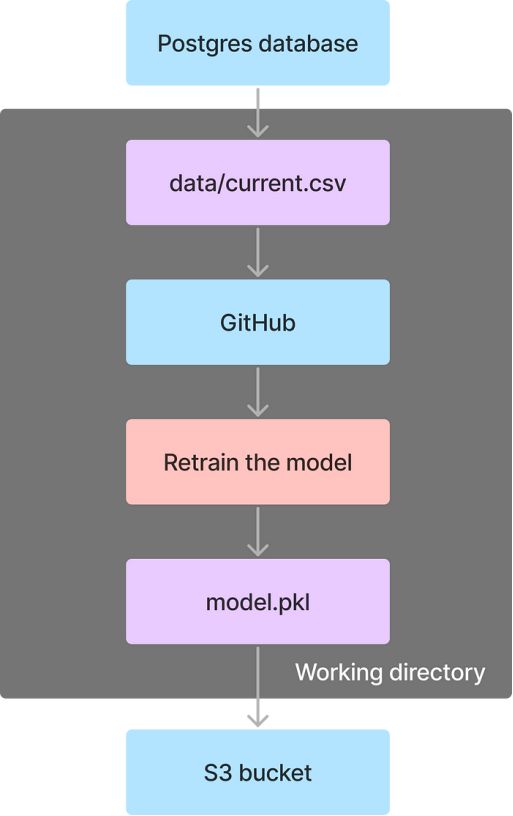
最后,我们将创建一个流来重新训练模型。该流程执行以下任务:
- 从Postgres数据库中的当前表导出CSV文件
- 克隆包含模型训练代码的GitHub存储库
- 运行一个Python脚本来训练模型并生成一个pickle文件
- 将pickle文件上传到S3
id: train-model
namespace: dev
tasks:
- id: getCurrentTable
type: io.kestra.plugin.jdbc.postgresql.CopyOut
url: jdbc:postgresql://host.docker.internal:5432/
username: "{{secret('POSTGRES_USERNAME')}}"
password: "{{secret('POSTGRES_PASSWORD')}}"
format: CSV
sql: SELECT * FROM current
header: true
- id: wdir
type: io.kestra.core.tasks.flows.WorkingDirectory
tasks:
- id: cloneRepository
type: io.kestra.plugin.git.Clone
url: https://github.com/khuyentran1401/detect-data-drift-pipeline
branch: main
- id: saveCurrentToCSV
type: io.kestra.core.tasks.storages.LocalFiles
inputs:
data/current.csv: "{{outputs.getCurrentTable.uri}}"
- id: trainModel
type: io.kestra.plugin.scripts.python.Commands
beforeCommands:
- pip install -r src/train/requirements.txt
commands:
- python src/train/train_model.py
- id: saveToPickle
type: io.kestra.core.tasks.storages.LocalFiles
outputs:
- model.pkl
- id: upload
type: io.kestra.plugin.aws.s3.Upload
accessKeyId: "{{secret('AWS_ACCESS_KEY_ID')}}"
secretKeyId: "{{secret('AWS_SECRET_ACCESS_KEY_ID')}}"
region: us-east-2
from: '{{outputs.saveToPickle.uris["model.pkl"]}}'
bucket: bike-sharing
key: model.pkl
triggers:
- id: listenFlow
type: io.kestra.core.models.triggers.types.Flow
conditions:
- type: io.kestra.core.models.conditions.types.ExecutionFlowCondition
namespace: dev
flowId: detect-data-drift
- type: io.kestra.core.models.conditions.types.VariableCondition
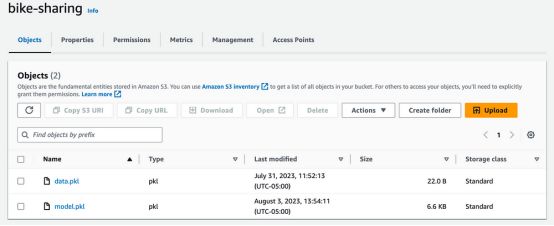
expression: "{{outputs.detectDataDrift.vars.drift_detected}} == true"After running this flow, the model.pkl file will be uploaded to the "bike-sharing" bucket.运行此流之后,model.pkl文件将被上传到“bike-sharing”存储桶中。
扩展此工作流程的想法
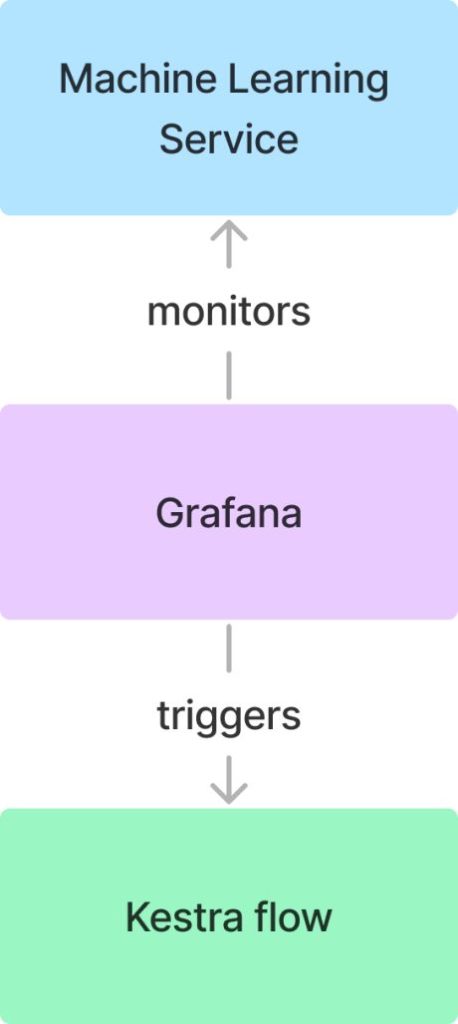
我们可以利用Grafana的传出webhook和Kestra的传入webhook来建立实时数据监控,并在数据发生漂移时立即触发数据流,而不是依赖于预定的数据提取来识别数据漂移。这种方法可以在数据漂移发生时立即进行检测,从而无需等待计划脚本运行。
请在评论中告诉我,你认为这个工作流可以如何扩展,以及你希望在未来的内容中看到哪些其他用例。你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Khuyen Tran
翻译作者:过儿
美工编辑:过儿
校对审稿:Chuang
原文链接:https://towardsdatascience.com/how-to-build-a-fully-automated-data-drift-detection-pipeline-e9278584e58d




