
数据分析如何助力业务增长?
尽管人工智能模型正在迅速改进,但企业如何利用这些创新创造价值并不总是显而易见的。
在本文中,我将介绍一个真实的用例,它帮助我更好地了解我的客户是谁以及他们为什么愿意付费。本文提供免费示例代码,并且可以轻松适配至其他业务场景。
客户细分是有效营销策略的关键部分。它涉及识别客户数据中的模式,以支持个性化营销、指导功能开发并优化用户体验。
虽然数字数据(如年龄、收入、性别)相对直观,但这些数据并不能全面反映客户行为。换句话说,它们不会告诉你“为什么”某人愿意为你的产品或服务买单。这种“为什么”通常只能从文本数据(如评论、调查回复、客户访谈)中提取。
传统上,从文本中提取这些信息通常需要手动阅读客户反馈,或编写严格的规则来提取关键属性。然而,如今我们有更高效的替代方案。
解决方案 1:ChatGPT
一个直接的解决方案是使用 ChatGPT(或类似的 AI 工具)。你只需上传一个包含调查数据的 .csv 文件,并要求模型生成细分。
虽然这是一个快速且简单的初步方法,但它存在两个主要限制:
ChatGPT 的上下文窗口有限,无法处理大量客户记录。
LLM 在处理数值数据方面较为薄弱,这可能会导致混合数值和文本数据时的误差。
解决方案 2:文本嵌入
为了克服上述限制,我们可以使用文本嵌入(text embeddings)。文本嵌入技术能够将文本数据转换为有意义的数值表示。
通过将文本转换为数值,我们可以应用传统的聚类技术,使其能够扩展至数千条甚至更多的记录。此外,这些嵌入还能无缝结合年龄、收入等数值特征。
4步客户细分流程:
- 导入调查数据:使用 Pandas 加载非结构化调查数据。
- 计算嵌入:使用 OpenAI API 将文本转换为数值嵌入。
- 聚类分析:利用 KMeans 对客户群进行分组。
- 可视化结果:使用 PCA 进行降维并绘制 2D 视图。
示例代码和数据可在 GitHub 公开存储库中获取。
示例代码:基于嵌入的客户细分
现在我们对用例有了基本的了解,让我们来看看一个具体的例子,使用我的AI训练营的真实调查结果。示例代码和数据可以在GitHub存储库中免费获得。
Imports
首先,我们需要导入一些Python库。关键是openai用于访问其嵌入模型和sklearn用于聚类。
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from sklearn.cluster import KMeans
import numpy as np
from openai import OpenAI
from top_secret import my_sk
client = OpenAI(api_key=my_sk)注意:此项目需要 OpenAI API 密钥,我从一个独立的 Python 脚本中导入。
步骤1:导入调查数据
接下来,我们使用Pandas导入调查数据。
# load data
df = pd.read_csv("data/survey.csv")调查数据包含两列:job_title(职位)和 join_reason(加入原因),均为开放式文本回复。
调查数据框架的负责人。图片来自作者。
一个问题是有几个记录缺少职位名称或加入原因(或两者都有)。我只是删除这些行,这样它们就不会使集群倾斜。
# drop rows with missing values
df = df.dropna()步骤2:计算嵌入
导入数据后,我们现在可以计算嵌入。OpenAI的嵌入API允许我们指定我们想要返回的嵌入维度的数量。在这里,我使用12个维度来表示职位名称,24个维度用于连接原因。
# define number of embedding dimensions
job_embedding_dim = 12
reason_embedding_dim = 24
# compute embeddings for job descriptions
job_response = client.embeddings.create(
input=df['job_title'],
model="text-embedding-3-small",
dimensions = job_embedding_dim
)
# compute embeddings for join reasons
reason_response = client.embeddings.create(
input=df['join_reason'],
model="text-embedding-3-small",
dimensions = reason_embedding_dim
)接下来,我从API响应中提取嵌入,并将它们存储在单个数据帧中。
# create list with all embeddings
embedding_list = [
job_response.data[i].embedding +
reason_response.data[i].embedding
for i in range(len(df))
]
# define column names
col_names = [
f"job_embedding-{i+1}"
for i in range(len(job_response.data[0].embedding))
] +
[
f"reason_embedding-{i+1}"
for i in range(len(reason_response.data[0].embedding))
]
# create df_embeddings
df_embeddings = pd.DataFrame(embedding_list, columns=col_names)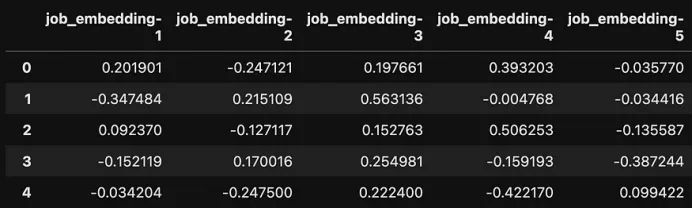
步骤3:聚类分析
有了数字格式的调查数据,我们现在可以应用聚类K-means对类似的回答进行分组。这是5组。
# KMeans
num_segments = 5
clustering = KMeans(n_clusters=num_segments, random_state=0).fit(df_embeddings)
# add segments to survey data
df["segment"] = clustering.labels_+1步骤4:可视化结果
最后,我们可以使用Matplotlib可视化聚类数据。然而,由于每个响应有36个数字,我们首先需要使用PCA将数据的维数从36降至2。
# use PCA to reduce dimensionality for visualization
X = PCA(n_components=2).fit_transform(df_embeddings)
# plot components for each segment
for label in range(num_segments):
indexes = np.where(clustering.labels_ == label)[0]
plt.scatter(X[indexes,0], X[indexes,1], label=f"Segment {label+1}")
plt.legend(bbox_to_anchor=(1.05, 1), loc='upper left')
plt.xlabel("PC 1")
plt.ylabel("PC 2")
plt.show()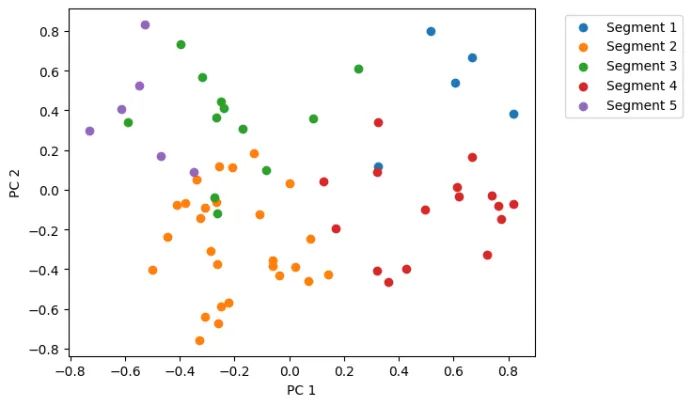
尽管我们已成功地将调查数据划分为五个部分,但目前获得的洞察仍然有限。为了进一步深入分析,我们可以利用 GPT-40-mini 对每个集群的典型响应进行合成,以提炼出更具价值的见解。
注意:对于较大的集群,可以采用更智能的分析方法,例如结合可解释的人口统计数据和关键绩效指标(KPI)来预测集群标签,从而提高洞察的准确性和可操作性。
回答如下。
Segment 1 | Size: 5
- **Job Title**: Founder
- **Desired Outcomes**: Acquire practical skills to build and fine-tune AI
applications independently.
- **Key Challenges**: Limited time and resources to fully engage with coding
examples and implement AI projects effectively.
-------------------------------------------------------------------------------
Segment 2 | Size: 27
- **Job Title**: Data Scientist
- **Desired Outcomes**: Gain practical skills and knowledge in AI to enhance
career opportunities and effectively contribute to AI projects.
- **Key Challenges**: Bridging knowledge gaps in AI concepts and practical
applications to confidently integrate AI into their current roles or transition to AI-focused careers.
-------------------------------------------------------------------------------
Segment 3 | Size: 12
- **Job Title**: Product Manager
- **Desired Outcomes**: Gain practical experience and knowledge in AI and LLMs
to effectively collaborate with engineers and implement AI-driven product
strategies.
- **Key Challenges**: Lack of technical coding skills and understanding of AI
concepts, making it difficult to engage with engineers and leverage AI
technologies effectively.
-------------------------------------------------------------------------------
Segment 4 | Size: 16
- **Job Title**: Founder
- **Desired Outcomes**: Build practical AI applications and tools to enhance
business operations and gain hands-on experience.
- **Key Challenges**: Need for practical knowledge and skills to effectively
implement and deploy AI solutions in their respective fields.
-------------------------------------------------------------------------------
Segment 5 | Size: 6
1. **Job Title**: Data Scientist
2. **Desired Outcomes**: Acquire technical skills and hands-on experience to
enhance their resume and build a portfolio.
3. **Key Challenges**: Balancing course participation with existing
commitments while taking the initiative to learn asynchronously.
-------------------------------------------------------------------------------由此,我们可以看到三种主要的客户概况:
- 技术(数据)专业人士:希望提升 AI 技能,以构建基于 LLM 的项目,并推动职业发展。
- 产品经理:希望更深入理解 AI,以便更有效地领导工程团队并制定 AI 相关产品战略。
- 创业者:专注于构建 AI 原生产品,以推动创新并优化业务运营。
结论
现代语言模型使得大规模、可扩展的文本数据分析与合成成为可能。在本案例中,我们展示了如何结合文本嵌入和传统聚类算法,将非结构化的调查数据转化为可解释的客户细分,从而提炼出更具价值的业务洞察。
感谢阅读!你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/。
如果你有任何问题,欢迎在评论区讨论!
原文作者:Shaw Talebi
翻译作者:过儿
美工编辑:过儿
校对审稿:Jason
原文链接:https://shawhin.medium.com/how-to-build-customer-segments-with-ai-f24178e2cf3b





