
3步走方略——用Python为数据科学项目收集数据
每个数据科学项目都需要数据,因此我们使用网页爬取工具从网页中爬取数据并构建我们的数据集。
问题是,一个网页的数据可能并不齐全,无法满足我们所需,或者它可能有一些不一致性,导致我们只爬取了一部分数据。
当我从世界杯网页上爬取1930到2022的足球比赛时(https://medium.com/geekculture/web-scraping-football-matches-from-the-world-cups-1930-to-2022-with-python-d2a1d578f034),这种情况就发生在我身上了。我只爬取了部分数据,而不是全部。在这篇文章中,我们将使用Selenium从头开始爬取剩余的足球比赛数据,以便稍后在项目中使用这些数据(https://frank-andrade.medium.com/list/python-project-fifa-world-cup-2022-prediction-85426e7c421c)。如果你想了解更多关于数据科学的相关内容,可以阅读以下这些文章:
使用Python和R的五个简单快捷的技巧——让你成为高效数据科学家
数据工程——Scala与Python的区别
【Python-数据科学】Pandas Basics速查表(2023)
如何使用Python进行运动检测?
步骤1:安装Selenium
要安装Selenium,请打开一个终端并运行以下命令。
pip install selenium现在我们需要为我们的电脑下载正确版本的Chrome驱动。
- 检查你的Google Chrome版本(在Chrome上点击“…”,点击“帮助”,然后点击“about Google Chrome”)
- 在此处下载正确的Chrome驱动版本(https://chromedriver.chromium.org/downloads)(在Chrome更新后,你需要再次下载文件)
- 解压下载的文件,并将路径复制到你要保留的Chrome驱动文件的位置。
步骤2:爬取数据
要从网页中爬取数据,首先,我们必须导入所有要使用的库。
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
import time
import pandas as pd- Selenium:帮助我们收集数据的库
- Time:帮助我们添加自动化网页时的等待时间
- Pandas:帮助我们将爬取的数据组成数据帧
每次我们用Selenium爬取网页数据时,我们必须定义以下变量:
- 路径:你的Chrome驱动文件所在的位置
- 网页:我们要爬取的网页(我们将爬取此页面:https://en.wikipedia.org/wiki/1982_FIFA_World_Cup)
- 驱动:帮助我们爬取网页所需数据
path = # Write your path here
service = Service(executable_path=path)
driver = webdriver.Chrome(service=service)
web = 'https://en.wikipedia.org/wiki/1982_FIFA_World_Cup'现在打开Chrome驱动并转到目标网页,我们运行以下代码。
driver.get(web)系统将弹出一个新窗口,上面显示“Chrome is controlled by automated test software”
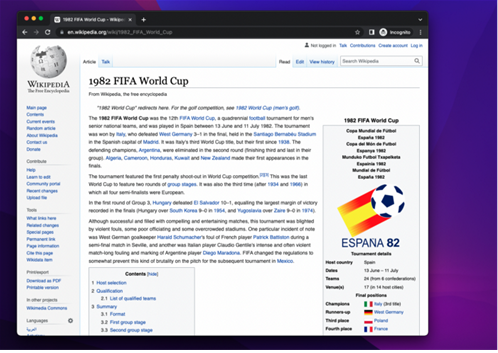
现在,我们必须查看我们希望爬取的元素隐藏的HTML代码。然后,我们向下滚动,直到找到足球比赛,然后右键单击并选择“Inspect”。
然后,调试工具将被打开。我们单击“select button”(左侧的光标),然后找到包含足球比赛的那一行。
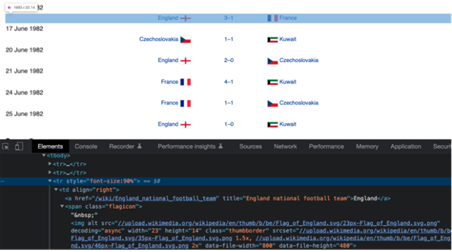
选定该行后,我们将获得其HTML元素。
<tr style="font-size:90%">现在,要使用Selenium定位该元素,我们必须创建它的XPath。下面是XPath的句法。

如果我们替换每个元素,我们会得到:
//tr[@style="font-size:90%"]一旦创建了XPath,我们就可以使用.find_elements通过Selenium来定位这样的元素。
matches = driver.find_elements(by='xpath', value='//tr[@style="font-size:90%"]')我们的变量matches包含网页上列出的48行/匹配项。如果我们循环浏览列表,我们可以获取所有的td元素,因为它们是我们之前创建的XPath的tr元素的子节点。
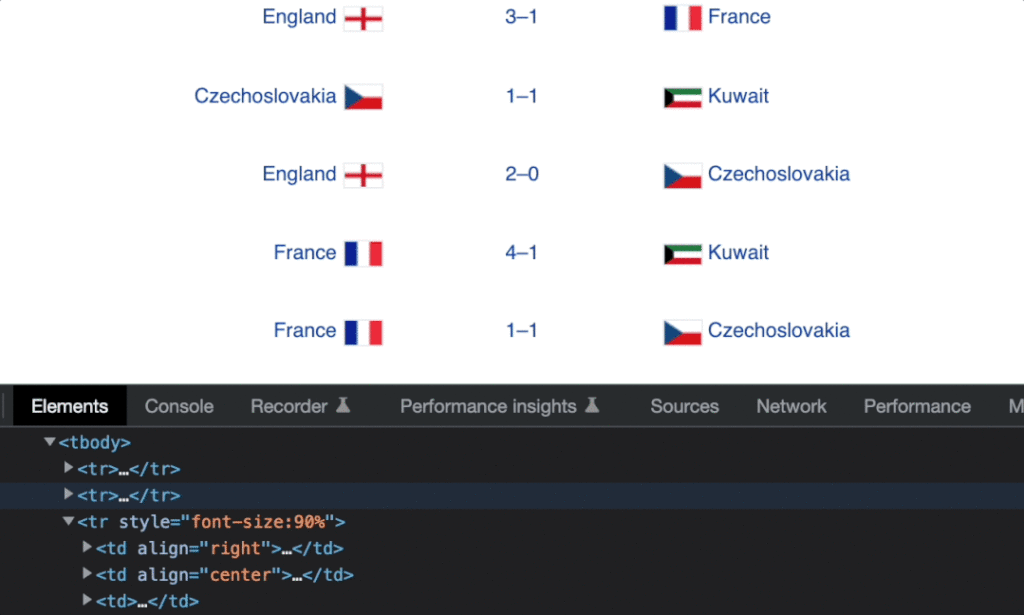
td元素包含home(主场球队)、score(比分)和away(客场球队)。我们可以通过以下XPath获得这些数据。
/td[1]:home team
/td[2]:score
/td[3]:away team让我们循环浏览matches,并将数据存储在我命名为home,score和away的空列表中。
home = []
score = []
away = []
for match in matches:
home.append(match.find_element(by='xpath', value='./td[1]').text)
score.append(match.find_element(by='xpath', value='./td[2]').text)
away.append(match.find_element(by='xpath', value='./td[3]').text)要注意,我在源XPath/td前加入了“.”,因为现在我们使用的不是driver.find_element而是match.find_element(“.”表示我们从匹配节点开始搜索)。
除此之外,我们还添加了text属性以获取节点内的文本(例如,英国3-1法国)。
最后,我们从home、score和away列表中创建一个数据帧。我们添加一个新的year 列,等待2秒(这是可选的),然后退出driver。
dict_football = {'home': home, 'score': score, 'away': away}
df_football = pd.DataFrame(dict_football)
df_football['year'] = 1982
time.sleep(2)
driver.quit()要导出数据帧,我们使用.to_csv.。
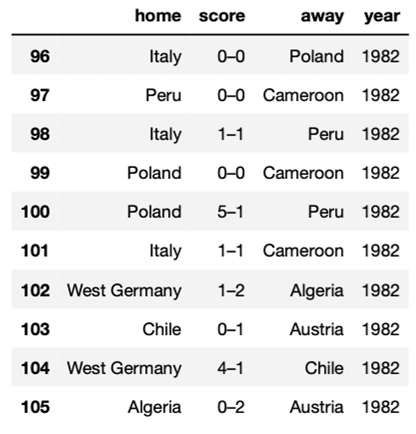
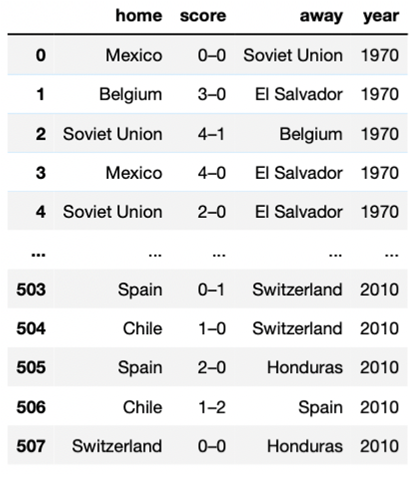
df_football.to_csv("fifa_worldcup_missing_data.csv", index=False)导出的数据应如下图所示,具有48行。
目前编写的代码可以在我的GitHub上找到(https://github.com/ifrankandrade/fifa-world-cup-2022-prediction)。现在,让我们稍微调整一下代码,试着爬取更多的网页页面。
步骤3:创建一个函数来爬取多个页面
网页爬取最酷的是,一旦我们爬取了一个页面,我们就可以从同一个网页爬取多个页面(只要它们具有相同的结构)。
下面是完成这项工作的函数。
def get_misssing_data(year):
web = f'https://en.wikipedia.org/wiki/{year}_FIFA_World_Cup'
driver.get(web)
matches = driver.find_elements(by='xpath', value='//tr[@style="font-size:90%"]')
home = []
score = []
away = []
for match in matches:
home.append(match.find_element(by='xpath', value='./td[1]').text)
score.append(match.find_element(by='xpath', value='./td[2]').text)
away.append(match.find_element(by='xpath', value='./td[3]').text)
dict_football = {'home': home, 'score': score, 'away': away}
df_football = pd.DataFrame(dict_football)
df_football['year'] = year
time.sleep(2)
return df_football请注意,此函数使用year作为输入。我把这个year变量放到web的链接和df_football[‘year’]列中。其余的保持不变。
如果我们运行get_misssing_data(1982),我们将得到与步骤2中相同的输出。
为了从多个页面中爬取数据,我们创建一个years列表,其中包含世界杯举办的所有年份。
years = [1930, 1934, 1938, 1950, 1954, 1958, 1962, 1966, 1970, 1974,
1978, 1982, 1986, 1990, 1994, 1998, 2002, 2006, 2010, 2014,
2018]现在,我们将使用列表推导来删除与每年相对应的页面,并将数据保存在名为fifa的列表中。我们将所有列表与.concat放在一起,最后将此数据导出为CSV。
fifa = [get_misssing_data(year) for year in years]
driver.quit()
df_fifa = pd.concat(fifa, ignore_index=True)
df_fifa.to_csv("fifa_worldcup_missing_data.csv", index=False)现在,我们的CSV文件应该有数百行,其中包含爬取的所有数据。
恭喜!现在你已经知道了如何使用Selenium构建数据集。你可以使用我们在此项目中爬取的数据集:https://frank-andrade.medium.com/list/python-project-fifa-world-cup-2022-prediction-85426e7c421c。你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Frank Andrade
翻译作者:高佑兮
美工编辑:过儿
校对审稿:Chuang
原文链接:https://medium.com/geekculture/how-to-collect-data-for-a-data-science-project-with-python-in-3-steps-40effa214aea





