
手把手教你用Python创建SQL数据库!
会写SQL很重要,能高效地查询数据库被认为是数据分析师/科学家最基本的技能之一。
SQL不仅重要,而且非常常用。根据《2021年Stackoverflow开发者调查》,SQL是最常用的五种编程语言之一。所以,我们应该多投入时间来学习SQL。
但是有一个问题:如何在没有数据库的情况下练习数据库查询呢?
在今天的文章中,让我们一起来解决这个基本问题,学习如何从零开始创建自己的MySQL数据库。在Python和一些外部库的帮助下,我们将创建一个简单的脚本,可以自动创建并使用随机生成的数据,填充我们的表格。
但是,在讨论实现细节之前,我们首先需要讨论一些先决条件。如果你想了解更多数据分析相关内容,可以阅读以下这些文章:
5个鲜为人知的 Python 库!帮你的下一个NLP项目起航
从Marplotlib到Plotly: 教你入门Python数据可视化
如何征服数据科学面试中的Python编程考试
如何编写出优秀的 Python Class
注意:当然还有其他方法可以获取用于实践的SQL数据库(例如直接找资源下载),但使用Python和一些外部库可以为我们提供额外且有价值的实践机会。
先决条件
我们先从最基本的开始。
首先,需要安装MySQL Workbench并连接服务,接下来就可以开始建立数据库:
CREATE DATABASE IF NOT EXISTS your_database_name;现在,我们只需要安装必要的python库,基本的设置就完成了。我们将要使用的库如下所示,可以通过终端轻松安装。
- 1. NumPy: pip install numpy
- 2. Sqlalchemy: pip install sqlalchemy
- 3. Faker: pip install faker
创建脚本
完成基本设置后,我们可以开始编写python脚本了。
先用一些样板代码创建一个类,为我们提供一个蓝图,指导我们完成其余的实现。
import numpy as npimport sqlalchemyfrom faker import Fakerfrom sqlalchemy import Table, Column, Integer, String, MetaData, Date,class SQLData:def __init__(self, server:str, db:str, uid:str, pwd:str) -> None:self.__fake = Faker()self.__server = serverself.__db = dbself.__uid = uidself.__pwd = pwdself.__tables = dict()def connect(self) -> None:passdef drop_all_tables(self) -> None:passdef create_tables(self) -> None:passdef populate_tables(self) -> None:pass
目前我们还没用特别高级的语法。我们基本上只是创建了一个类,存储了数据库凭据供以后使用,导入了库,并定义了一些方法。
建立连接
我们要完成的第一件事是创建一个数据库连接。
幸运的是,我们可以利用python库sqlalchemy来完成大部分工作。
class SQLData:#...def connect(self) -> None:self.__engine = sqlalchemy.create_engine(f"mysql+pymysql://{self.__uid}:{self.__pwd}@{self.__server}/{self.__db}")self.__conn = self.__engine.connect()self.__meta = MetaData(bind=self.__engine)
这个方法可以创建并存储3个对象作为实例属性。
首先,我们创建一个连接,作为sqlalchemy应用程序的起点,描述如何与特定类型的数据库/ DBAPI组合进行对话。
在我们的例子中,我们指定一个MySQL数据库并传入我们的凭据。
接下来,创建一个连接,它可以让我们执行SQL语句和一个元数据对象(一个容器),将数据库的不同功能放在一起,让我们关联和访问数据库表。
创建表格
现在,我们需要创建数据库表。
class SQLData:#...def create_tables(self) -> None:self.__tables['jobs'] = Table ('jobs', self.__meta,Column('job_id', Integer, primary_key=True, autoincrement=True, nullable=False),Column('description', String(255)))self.__tables['companies'] = Table('companies', self.__meta,Column('company_id', Integer, primary_key=True, autoincrement=True, nullable=False),Column('name', String(255), nullable=False),Column('phrase', String(255)),Column('address', String(255)),Column('country', String(255)),Column('est_date', Date))self.__tables['persons'] = Table('persons', self.__meta,Column('person_id', Integer, primary_key=True, autoincrement=True, nullable=False),Column('job_id', Integer, ForeignKey('jobs.job_id'), nullable=False),Column('company_id', Integer, ForeignKey('companies.company_id'), nullable=False),Column('last_name', String(255), nullable=False),Column('first_name', String(255)),Column('date_of_birth', Date),Column('address', String(255)),Column('country', String(255)),Column('zipcode', String(10)),Column('salary', Integer))self.__meta.create_all()
我们创建了3个表,并将它们存储在一个字典中,以供以后参考。
在sqlalchemy中创建表也非常简单。我们只需实例化一个新的表,提供表名、元数据对象,并指定不同的列。
在本例中,我们创建了一个job表、一个company表和一个person表。person表还通过了foreign kkey链接了其他表,这使数据库在实践SQL连接方面更加有趣。
定义了所有表格之后,我们只需调用MetaData对象的create_all()方法就好了。
生成一些随机数据
虽然我们创建了数据库表,但仍然没有任何数据可用。因此,我们需要生成一些随机数据并将其插入到表中。
class SQLData:#...def populate_tables(self) -> None:jobs_ins = list()companies_ins = list()persons_ins = list()for _ in range(100):record = dict()record['description'] = self.__fake.job()jobs_ins.append(record)for _ in range(100):record = dict()record['name'] = self.__fake.company()record['phrase'] = self.__fake.catch_phrase()record['address'] = self.__fake.street_address()record['country'] = self.__fake.country()record['est_date'] = self.__fake.date_of_birth()companies_ins.append(record)for _ in range(500):record = dict()record['job_id'] = np.random.randint(1, 100)record['company_id'] = np.random.randint(1, 100)record['last_name'] = self.__fake.last_name()record['first_name'] = self.__fake.first_name()record['date_of_birth'] = self.__fake.date_of_birth()record['address'] = self.__fake.street_address()record['country'] = self.__fake.country()record['zipcode'] = self.__fake.zipcode()record['salary'] = np.random.randint(60000, 150000)persons_ins.append(record)self.__conn.execute(self.__tables['jobs'].insert(), jobs_ins)self.__conn.execute(self.__tables['companies'].insert(), companies_ins)self.__conn.execute(self.__tables['persons'].insert(), persons_ins)
现在,我们可以利用Faker库来生成随机数据。
我们只需在for循环中使用随机生成的数据,创建一个由字典表示的新记录。然后将单个记录追加到可用于(多个)insert语句的列表中。
接下来,从连接对象中调用execute()方法,并将字典列表作为参数传递。
就是这样!我们成功实现了类—只需要把类实例化,并调用相关函数来创建数据库。
if __name__ == '__main__':sql = SQLData('localhost','yourdatabase','root','yourpassword')sql.connect()sql.create_tables()sql.populate_tables()
试着做一个查询
剩下的唯一一件事是——需要验证我们的数据库是否已经启动和运行,是否确实包含一些数据。
从基本的查询开始:
SELECT *FROM jobsLIMIT 10;
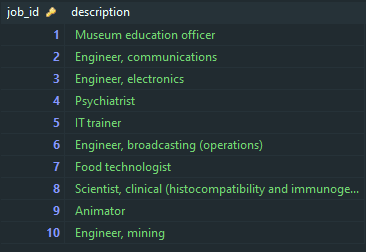
看起来我们的脚本成功了,我们有一个包含实际数据的数据库。
现在,尝试一个更复杂的SQL语句:
SELECTp.first_name,p.last_name,p.salary,j.descriptionFROMpersons AS pJOINjobs AS j ONp.job_id = j.job_idWHEREp.salary > 130000ORDER BYp.salary DESC;
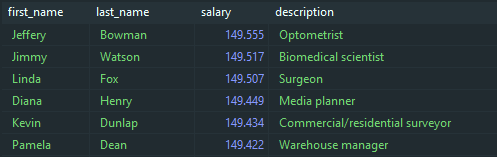
这个结果看起来很靠谱 – 可以说我们的数据库在正常运行。
结论
在本文中,我们学习了如何利用Python和一些外部库来用随机生成的数据创建我们自己的实践数据库。
虽然可以很容易地下载现有的数据库来开始练习SQL,但使用Python从头创建自己的数据库提供了额外的学习机会。由于SQL和Python经常紧密联系在一起,所以这些学习机会可能会特别有用。
你可以随意调整代码,创建一个更大、更好、更复杂的数据库。以上就是本文的全部内容,欢迎关注我们的公众号,了解更多数据科学相关内容!你还可以订阅我们的YouTube频道,观看大量数据科学相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Marvin Lanhenke
翻译作者:过儿
美工编辑:过儿
校对审稿:Jiawei Tong
原文链接:https://towardsdatascience.com/how-to-create-a-sql-practice-database-with-python-d320908e1faf





