
32首歌曲小样本举例:如何评估无监督机器学习?
目前为止,在该系列博文中,我们已经看到了如何通过仅基于歌曲音频特征的聚类分析来建立自动化的播放列表。
之前,我们用32首歌的小样本展示了HAC算法是怎样自动创建由相似歌曲构成的子集的。我们还使用了关于这些歌曲的已知信息来验证聚类结果。
但如果我们没有这样的先验知识怎么办呢?如果数据甚至连标签都没有怎么办呢(许多真实生活中的聚类分析案例就是这样)?
又如果,这些标签最开始对我们来说根本没有意义该怎么办?世上有许多我根本没听说过的音乐家,并且如果我们要给成千上万的歌曲分组,那么显然人工检验每个簇类是不现实的。
为了探讨如果解决这个问题,我们再次回到Spotify的API上面来。假设我们从以下四个截然不同的播放列表里面选取歌曲:
- Rap UK
- Smooth Jazz
- Classical Essentials
- Essential K-Pop
如果把他们合并为一个数据集,无监督机器学习算法应该可以把这些歌分成四组,且一定程度上与原始的四个播放列表相似。
我们开始之前,有必要先检查一下我们的假设,即各个播放列表中选出的歌曲确实是“不同的”。当然,在一幅图里同时展示两个以上的特征十分困难。但是如果我们给所有特征做一个散点矩阵——颜色代表播放列表——的话,就能看到有大量的变量对都在反应着各曲类鲜明的特点。

用Scikit-Learn运行聚类算法非常简单:

我们之前也了解了HAC的三种“关联标准”——算法对各簇类进行反复合并的方法:
- Ward(默认项):选取两个簇类进行合并,使得所有簇类间的方差增长最小。总体上,该方法会使各个簇类的大小相当。
- Average:将所有点间的平均距离最小的两个簇合并。
- Complete(又叫‘最大关联’):将各个点间的最大距离最小的两个簇合并。
让我们看看这些关联标准都是如何处理该播放列表数据集的。结果展示用矩阵进行,表示各个播放列表的歌曲有多少百分比被分进了各个簇类(以ABCD命名)。
当然,如果聚类过程完美无缺的话,我们预期矩阵内每行每列都会包含一个数值为100%的单元格——不一定是在对角线上,因为簇类名是随便起的。
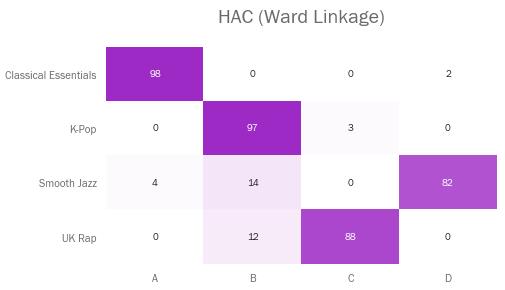
默认的‘Ward’关联法会尝试让簇类内的方差最小化,它在四个类型上表现都不错,只不过有一部分歌曲漏到了簇类B里面。
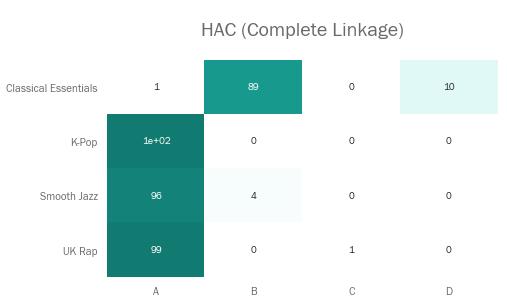
显然‘Complete’关联法效果不好。它把大部分歌曲都分到簇类A里去了,而簇类C只包含了一首歌。
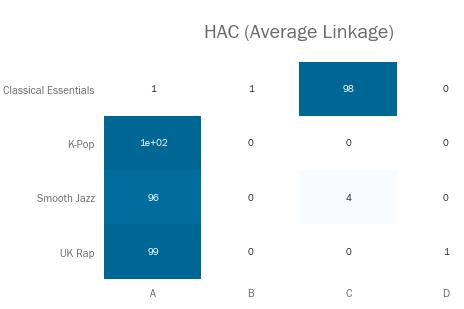
而‘Average’关联法与上一个有着类似的问题。大量歌曲被划入同一簇类,同时有两个簇仅仅只有一首歌。
值得一提的是,另一种常用聚类方法K-Means,其工作原理有点不同。HAC会通过合并来反复削减簇类数量,而K-Means会始终保持一定数量的簇类(顾名思义,K个),但是会反复改变每个簇里面的成员。
在Python中执行K-Means也很简单:

使用K-Means对该数据集聚类,结果如下:
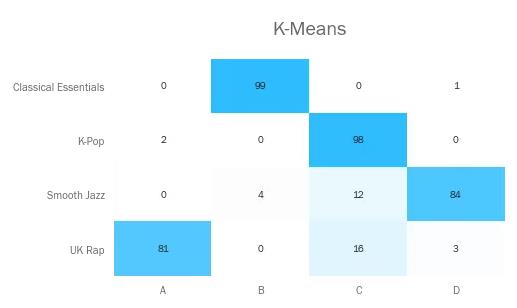
和使用‘Ward’方法的HAC一样,K-Means效果也不错。但还是有部分Jazz和Rap歌曲被错误分到了K-Pop簇。
虽然这些矩阵很适合肉眼观察我们的结果,但它们在数学上并不严谨。我们要考虑一些指标,用数值来表示我们的聚类质量。

调整兰德系数是经典兰德系数的一个变种,其尝试表述簇类中有多少比例是‘正确的’。其通过计算属性一致的样本对——即两个样本的真实标签和预测表签都相同,或者二者的真实标签和预测表签都不同——的数量与样本对总数的比值,再经过随机性修正,来比较不同聚类算法结果间的相似性。

调整兰德系数取值在-1和1之间。接近1则聚类效果好,接近-1则相反。
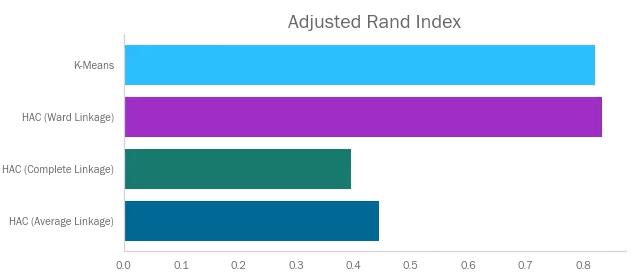
可以看到K-Means和Ward法分数较高,与我们之前的观察一致。

Fowlkes Mallows指数比较类似,它表示样本聚类分组的‘正确’程度。它计算查准率和查全率的几何平均值,取值在0和1之间,值越高越好。

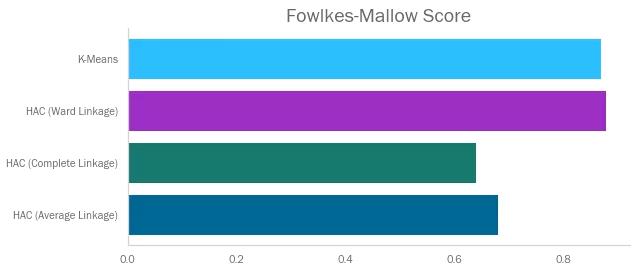
和预期一样,排名和调整兰德系数相似,毕竟两个指标都在回答同一个问题。
我们必须知道样本的真实标签才能计算这两个指标,这就给其价值打了折扣。因为无监督学习的一项主要应用就是处理无标签数据,所以我们需要其它不用真实标签就可以评估聚类结果的指标。
假设我们有下列三种不同聚类分析的结果。
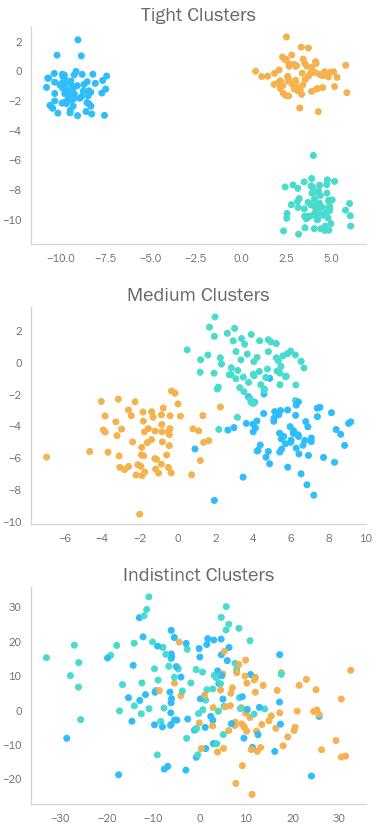

轮廓指数试图描述一个数据点——相对于与和不同簇类的数据点——与和它同簇类的其它数据点有多相似(该指标是所有数据点的汇总,以描述整体聚类结果)。换句话说,它考虑的是各个簇类在空间中有多独特,其实用任意距离测度都可以计算该指标。
它取值在-1和1之间。接近-1则表示错误聚类,接近1表示每个簇类都非常稠密。

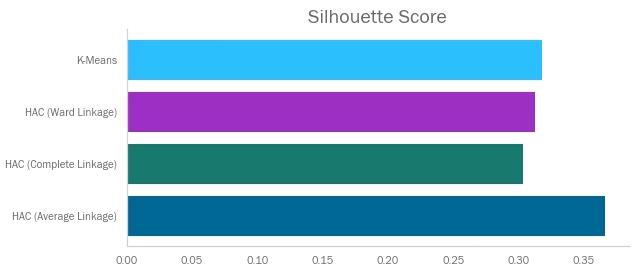
可以看见以上几种聚类的轮廓指数都不太高。有趣的是,Average关联聚类得分最高。但是回忆一下,该算法产生了两个只包含单个数据点的簇类,这在现实情境下不太可能是个好结果。由此可见,不要只依赖单个指标来判断算法的质量!

Calinski Harabaz指数是簇间协方差与簇内协方差的比值。因为我们希望前者高、后者低,所以CH指数越高越好。和其它几个指标不同,CH指数取值没有限制。

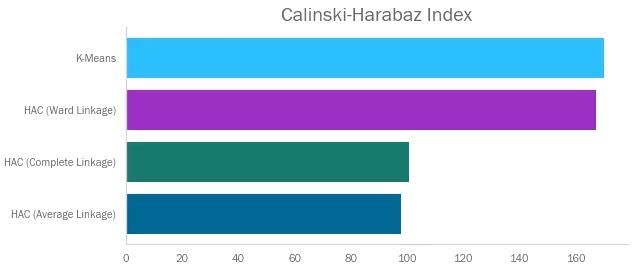
可见K-Means和Ward关联法的分数很高。另两个算法因含有较大簇类而受到惩罚——即较大的内方差。
原文作者:Callum Ballard
翻译作者:Siyu Hao
美工编辑:过儿
校对审稿:Dongdong
原文链接:https://towardsdatascience.com/how-to-evaluate-unsupervised-learning-models-3aa85bd98aa2





