
如果你的数据科学生涯只能用3个libraries,学这三个
数据科学库无处不在。从数据清理到可视化、机器学习模型的创建到超参数的调优,数据科学库都在发挥着重要作用。
每个库的目标都是简化并加快任务。然而,要学习数据科学生态系统中的所有库是不太可能的。
话虽如此,有些库你肯定非常好奇。我认为这些库如此受欢迎,而且广泛运用的两个主要原因有:
- 1. 涵盖大量常见和基本任务。
- 2. 提供易于使用且直观的语法。
因此,这些库非常值得学习。
如果你在数据科学领域工作,那么你一定已经猜到我要讲哪些库。但是,如果你正在学习数据科学或计划学习,我强烈建议你学习以下库:
- Pandas
- Seaborn
- Scikit-learn
这些都是 Python 库,学起来很简单,接下来让我一一为你介绍。如果你想了解更多数据分析相关内容,可以阅读以下这些文章:
5个鲜为人知的 Python 库!帮你的下一个NLP项目起航
从Marplotlib到Plotly: 教你入门Python数据可视化
如何征服数据科学面试中的Python编程考试
如何编写出优秀的 Python Class
Pandas
Pandas 是一个数据分析和操作库,其核心数据结构被称为 DataFrame,基本上就是一个带标签的行和列的表。
数据分析要用到大量表格数据,所以你一定希望掌握 Pandas。
Pandas 提供了许多用于清理、操作、分析、甚至绘制表格数据的功能,同时还具有处理文本数据、日期和时间的等特定功能。
我们通过以下示例,演示 Pandas 的一些功能。假设我们有一个名为 staff 的 DataFrame,如下所示:
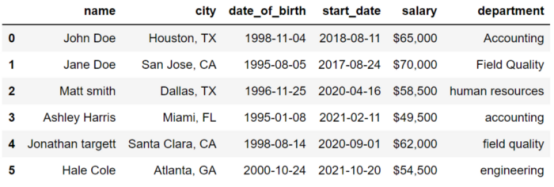
该表格包含有关公司员工的信息。
city列包含城市名和州名。我们通过提取州名称,创建一个名为 state 的新列。
我们可以通过提取 city 列中的最后两个字符,执行此任务:
import pandas as pd
staff["state"] = staff["city"].str[-2:]或者,我们可以用逗号拆分city列,并进行第二次拆分:
staff["state"] = staff["city"].str.split(",", expand=True)[1]
staff["state"]
# output
0 TX
1 CA
2 TX
3 FL
4 CA
5 GA
Name: state, dtype: object我们再看另一个数据集。我准备了一个销售数据集的样本,点击此处访问GitHub 下载:https://github.com/SonerYldrm/datasets。我们将使用名为“sample-sales-data.csv”的文件。
sales = pd.read_csv("Data/sample-sales-data.csv")
sales.head()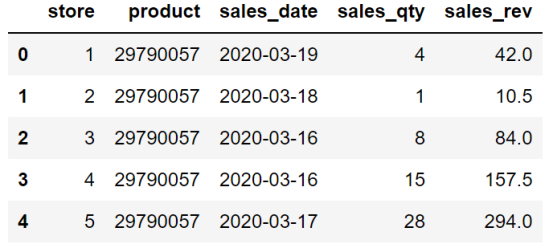
head 方法可以显示 DataFrame 的前 5 行。
我们可以使用 groupby 函数,计算每家商店的平均日销售额,如下所示:
sales.groupby("store")["sales_rev"].mean()
# output
store
1 60.468176
2 34.318355
3 35.008040
4 26.562408
5 31.970033
6 27.224161
Name: sales_rev, dtype: float64我们也可以同时使用命名聚合以及groupby 函数,输出更具信息的结果:
sales.groupby("store").agg(
avg_sales = ("sales_rev","mean")
)
# output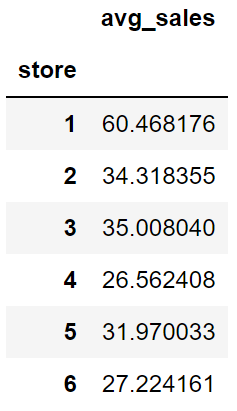
上面,我们运用Pandas成功执行了一些简单的操作,但 Pandas 也能够执行更复杂的任务。
Seaborn
数据可视化在数据科学中至关重要,不仅可以帮助我们了解、探索数据,还能评估机器学习模型、并交付结果。
精心设计的数据可视化告诉我们的不仅仅是简单的数字。因此,我们需要一个有效的工具,用于创建信息丰富且吸引人的可视化。
Seaborn 是 Python 的统计可视化库。有些其他库也很受人欢迎,例如 Matplotlib、Plotly 和 Altair,但我更喜欢 Seaborn,因为它的语法非常简单,可以用少数代码行,创建信息丰富的图表。
我们以有名的 iris 数据集为例。
import seaborn as sns
sns.set(style="darkgrid")
iris = sns.load_dataset("iris")
iris.head()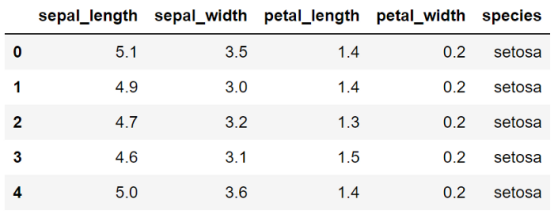
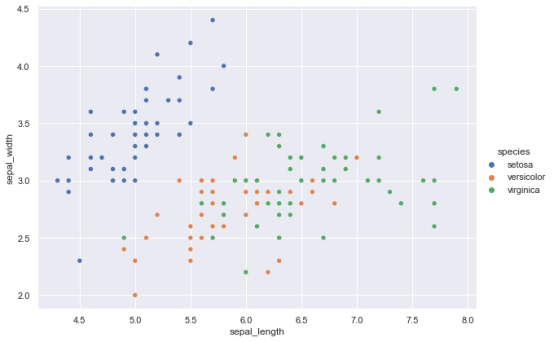
我们可以使用 relplot 函数,创建萼片长度和萼片宽度列的散点图。为了使其更具信息性,我们可以使用不同的颜色代表不同的物种。
sns.relplot(
data=iris,
x='sepal_length', y='sepal_width', hue="species",
kind='scatter',
height=5, aspect=1.2
)
Scikit-learn
Scikit-learn 是我们的首选的机器学习库。Scikit-learn不仅可以提供大量现成的算法,而且还具有推动机器学习工作流程中典型任务的功能。
有些算法需要数据以特定的格式显示。我们还需要对一些算法的数值数据进行规范化处理,并对分类数据进行编码。Scikit-learn 提供了特征预处理工具,可以轻松执行上述任务。
Scikit-learn还通过使用诸如方差阈值、递归特征消除等不同的技术,帮助我们进行特征选择。
我们也可以使用 Scikit-learn 完成一个稳健而深入的模型评估过程。同时,Scikit-learn还有机器学习中与众多指标相关的功能。
总的来说,Scikit-learn 是一个全面、实用、高效的机器学习库。
如果你打算成为一名数据科学家,你所需要的只是时间和动力。你可以找到大量免费资源,其中很大一部分是开源库。这些库在学习和执行数据科学方面发挥着关键作用。
我们在本文中介绍的库可以满足你在数据操作和分析、数据可视化和机器学习方面的大部分需求。以上就是本文的全部内容!感谢你的阅读。你还可以订阅我们的YouTube频道,观看大量数据科学相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Soner Yildinm
翻译作者:Lia
美工编辑:过儿
校对审稿:Jiawei Tong
原文链接:https://medium.com/@sonery/if-you-are-to-learn-only-3-libraries-for-data-science-learn-these-ce5ba62acf96





