
CS转行Data Science,这里是你需要的全部资源
如今每个人都想成为一名Data Scientist, 从博士生到Data Analysts, 再到在LinkedIn上给你留言让你带咖啡的大学室友。
如果你也有同样的想法,查找一些data science的职位,看看宣传的是关于什么。 也许你已经看到像Vicki Boykis的“Data Science现在有所不同”这样的文章:
显而易见的是,在宣传周期的后期阶段,Data Science逐渐接近Engineering,Data Scientists向前发展的技能更少用可视化和统计学,更符合传统计算机科学…
像单元测试和持续集成这样的概念变成了Data Scientist以及从事ML工程的数值科学家常用的术语和工具集。
或Tim Hopper的推文:
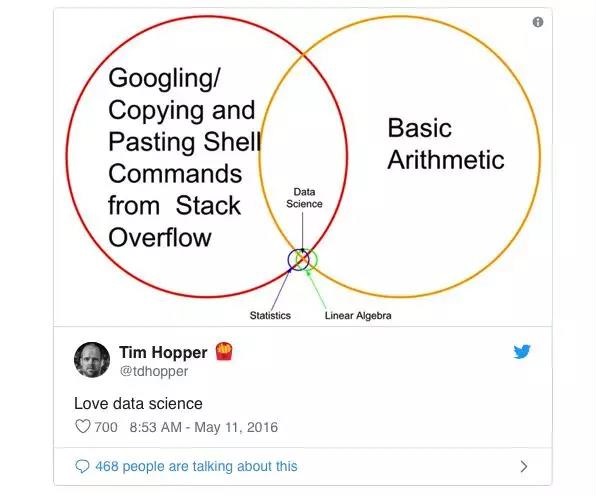
目前尚不清楚的是如何利用你作为软件工程师的经验进入Data Science的岗位。
你可能遇到的其他一些问题是:
· 我应该优先学习什么?
· 是否存在针对Data Scientists的最佳实践或工具
· 我目前的技能是否会延续到Data Science的角色? ?
本文将提供有关Data Scientist角色的背景知识,以及为什么你的背景可能非常适合Data Science,以及作为开发人员可以采取的切实步骤操作以加强数据科学。
Data Scientist versus Data Engineer
首先,我们应该区分两个互补的角色:Data Scientist与Data Engineer。虽然这两个角色都处理机器学习模型,但它们与这些模型的联系以及Data Scientists和Data Engineers的工作要求和性质差异很大。
Note:Data Engineer专门用于机器学习, 也可以在职位描述中表现为“Software Engineer,Machine Learning”或“Machine Learning Engineers”
作为Machine Learning工作流程的一部分,Data Scientist将执行所需的统计分析,以确定使用哪种机器学习方法,然后开始原型设计并构建这些模型。
Machine Learning Engineers经常在数据建模过程之前和之后与Data Scientists合作:
(1)构建Data Pipelines以将数据提供给这些模型;
(2)设计一个工程系统,为这些模型提供服务,以确保模型的持续有效。
下图描述了这种技能的连续统一性:
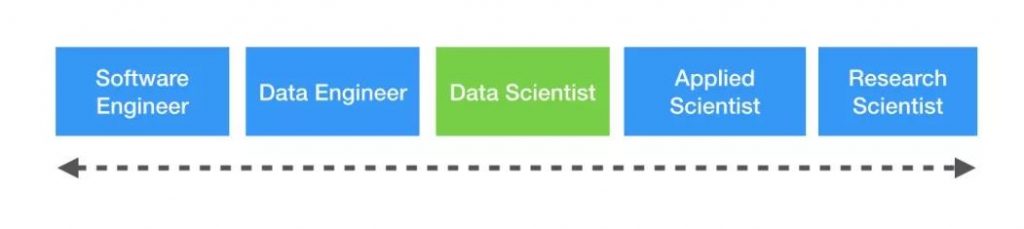
有关数据科学家和数据工程师之间差异的在线资源 – 请查阅:
Panoply:Data Engineer和Data Scientist之间有什么区别?
https://blog.panoply.io/what-is-the-difference-between-a-data-engineer-and-a-data-scientist
Springboard:Machine Learning Engineer vs Data Scientist
O’Reilly:Data engineers vs. data scientists
你作为开发人员的优势
围绕Machine Learning的课程,如“Python中的Data Science 入门”或Andrew Ng的Coursera课程,都不包括软件工程的概念和最佳实践,如单元测试,编写模块化可重用代码,CI / CD或版本控制,这对每个人来说都不好。甚至一些最先进的Machine Learning 团队仍然没有将这些实践用于他们的Machine Learning代码,导致令人不安的趋势……
Pete Warden将这一趋势描述为“Machine Learning 再生性危机”:
当我们从scratch开始跟踪变化和重建模型时,我们仍然处于黑暗时代。有时感觉就像我们在没有源代码控制的情况下编码时那样退缩,这种情况太糟糕了。
虽然你可能没有看到Data Scientist的职位描述中明确规定的这些“软件工程”技能,但掌握这些技能作为一部分背景知识将有助于你成为Data Scientist。此外,当你在Data Science面试中回答这些编程问题时,这些背景知识也将很有用。
对于另一方面的一些有趣的观点,请查看Trey Causey的“Data Scientists的软件开发技能”https://medium.com/@treycausey。 他建议Data Scientists应该学习“编写更好的代码,与软件开发人员更好地交互,最终节省你的时间”
加快Data Science的发展
拥有良好的软件工程背景基础是非常出色的,但是成为Data Scientist的下一步是什么? Josh Will关于Data Scientist 定义的简短推文非常准确:
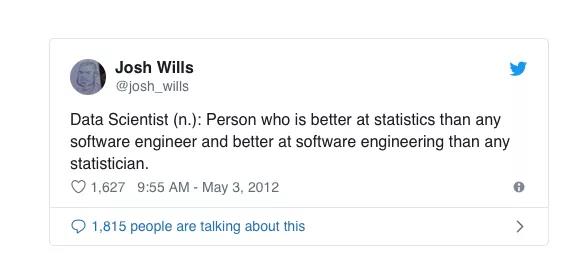
如果你有兴趣成为Data Scientist,那么它暗示了你应该关注的主题之一:统计数据。 在下一节中,我们将介绍以下方面的资源:
· 建立ML特定的知识
· 建立行业知识
· ML堆栈中的工具
· 技能和资格
建立ML特定的知识
最有效的是建立围绕概率和统计学理论基础,以及应用技能例如Data Wrangling或在GPU /分布计算上的训练模型。
构建知识的一种方法是在Machine Learning工作流程中引用它。
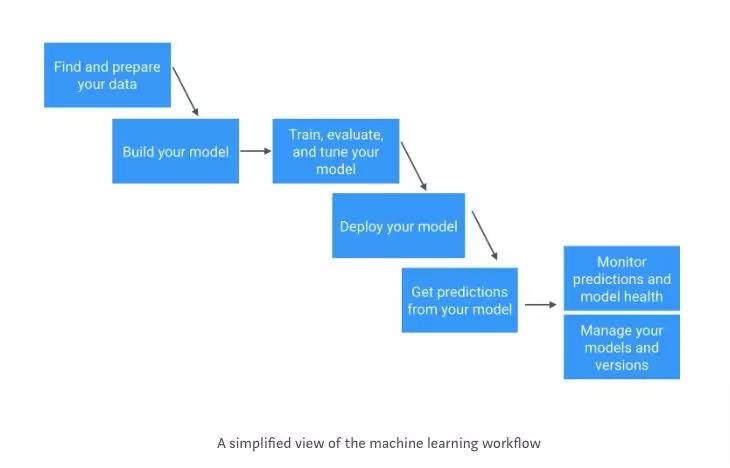
更详细的工作流程请参阅Skymind AI
https://skymind.ai/wiki/machine-learning-workflow
在这里,我们列出了一些有关Machine Learning的学习资源。考虑到我们无法提供一个完全详尽的清单和节省空间(和阅读时间)的目的,我们没有列出非常受欢迎的资源,如Andrew Ng的Coursera课程或Kaggle。
Courses:
· Fast.ai MOOC (免费课程,教授使用技能包括实用Deep Learning,Cutting Edge Deep Learning,计算线性代数和Machine Learning学习简介)
· Khan Academy
· 3Blue1Brown 和mathematicalmonk的youtube频道
https://www.youtube.com/channel/UCYO_jab_esuFRV4b17AJtAw
https://www.youtube.com/channel/UCcAtD_VYwcYwVbTdvArsm7w
· Udacity courses (包括Python中Machine Learning的预处理)
https://www.datacamp.com/courses/preprocessing-for-machine-learning-in-python
· Springboard AI/ML-specific track
Textbooks:
· Probabilistic Programming & Bayesian Methods for Hackers
http://camdavidsonpilon.github.io/Probabilistic-Programming-and-Bayesian-Methods-for-Hackers/
· Probability and Random Processes
https://www.amazon.com/Probability-Random-Processes-Geoffrey-Grimmett/dp/0198572220/
· Elements of Statistic Learning
https://web.stanford.edu/~hastie/Papers/ESLII.pdf
· Linear Algebra Done Right
http://148.206.53.84/tesiuami/S_pdfs/Linear%20Algebra%20Done%20Right.pdf
· Introduction to Linear Algebra
http://math.mit.edu/~gs/linearalgebra/
· Algorithm Design
http://www.cs.sjtu.edu.cn/~jiangli/teaching/CS222/files/materials/Algorithm%20Design.pdf
Guides:
· Google Developers Machine Learning Guide
https://developers.google.com/machine-learning/guides/rules-of-ml/
· Machine Learning Mastery Guides (可以看Machine Learning的python学习微课程作为开始)
· Pyimagesearch (电脑版)
Meetups: 主要基于纽约市
· Papers We Love
· NYC Artificial Intelligence & Machine Learning
· DataCouncil.ai
· NY Artificial Intelligence

作为一个很好的开始,请查阅Will Wolf的“开源Machine Learning大师”,了解如何在学习特定主题的过程中协调时间,并开展项目以在低成本的远程位置展示专业知识。
建立行业特定的知识
如果你想进入一个特定的行业,如医疗保健,金融服务,消费品,零售等……,那么了解该行业的痛点和该行业发展是必不可少的,因为他与数据和Machine Learning都有关联。
一个要点 = 你可以查看特定的AI初创公司的网站,看看他们如何定位他们的价值主张以及Machine Learning发挥作用的地方。这将为你提供有关学习Machine Learning的特定领域的想法,以及展示你的工作的项目主题。
我们可以举一个例子:假设我对医疗保健工作很感兴趣。
1、通过谷歌搜索“Machine Learning Healthcare”,我在Healthcareweekly.com上找到了“2019年值得关注的最佳医疗初创公司”的清单
你还可以使用“Healthcare”作为关键字在Crunchbase或AngelList上进行搜索
https://www.crunchbase.com/hub/health-care-startups#section-leaderboard
https://angel.co/jobs#find/f!%7B%22keywords%22%3A%5B%22Healthcare%22%5D%7D
2、让我们以列表中的一家公司BenevolentAI为例
3、BenevolentAI的网站声明:
我们是一家具有从早期药物发现到后期临床开发的端到端能力的AI公司。 BenevolentAI将计算医学和开放系统和云计算的AI功能相结合,以改变药物的设计,开发,测试和推向市场的方式。
我们建立了Benevolent平台,以便更好地了解疾病,并从大量生物医学信息中设计新的,改进现有的治疗方法。我们坚信我们的技术使科学家能够更快更有效地开发药物。
新的研究论文可以每30秒发布一篇,但科学家目前只使用一小部分知识来了解疾病的原因并提出新的治疗方法。我们的平台对书面文档,数据库和实验结果中的大量信息进行提取,读取和背景化。它能够在这些不同的、复杂的数据源上进行无限多的推论和推断,识别和创建人类不可能独自完成的关系,趋势和模式。
4.你可以立即看到BenevolentAI正在使用自然语言处理(NLP)。如果他们正在识别疾病与治疗研究之间的关系,他们可能会使用一些知识图表。
5.如果你查看BenevolentAI的求职界面,你可以看到他们正在招聘Senior Machine Learning Researcher。这是一个高级岗位,所以这不是一个完美的例子,但我们看看下面要求的技能和资格:
Note:
· 自然语言处理,知识图推理,主动学习和生化建模
· 结构化和非结构化数据源
· 贝叶斯模型方法
· ML知识和应用工具
这应该为你提供下一步的方法:
· 处理结构化数据
· 处理非结构化数据
· 在知识图中对关系进行分类
· 学习贝叶斯概率和建模方法
· 进行NLP项目的实践(文本数据)
我们不建议你申请通过搜索找到的公司,而是看看他们如何描述客户的痛点,他们公司的价值主张,以及他们在工作描述中列出的工作技能。
ML堆栈中的工具
在BenevolentAI的Senior Machine Learning Researcher职位描述中,他们要求“了解ML的知识和应用工具,例如Tensorflow,PyTorch等……”
学习这些ML的现代工具似乎令人生畏,因为空间总是在变化。要将学习过程分解为可掌控的部分,记住将你的思路与上面的Machine Learning工作流程相关联 ——“什么工具可以帮助我完成工作流程的这一部分?”
要看该机器学习工作流程的每个步骤中用到哪些工具,请查看Roger Huang的“机器学习堆栈简介”,其中介绍了Docker,Comet.ml和dask-ml等工具。
https://hackernoon.com/introduction-to-the-machine-learning-stack-f5b64bba7602
通常来说,Python和R是data scientists使用的最常见的编程语言,同时也有为Data Science应用设计的附加包,如NumPy,SciPy,以及Matplotlib。这些语言被解释而不是编译,使Data Scientist可以专注于解决问题而不是语言的细微差别。面向对象的编程来理解数据结构作为类的实现值得时间学习。
要了解像Tensorflow,Keras和PyTorch这样的ML框架,请务必转到他们的文档并尝试端到端地实现他们的教程。
在一天结束时,你需要确保构建项目,展示用于Data Collection和Wrangling,Machine Learning实验管理和建模的工具。
有关你项目的一些灵感,可参阅Edouard Harris关于“冷启动问题:如何构建Machine Learning”的文章
技能和资格
我们将此部分作为最后一部分,因为它汇总了前面部分的大部分信息,但是专门针对Data Science面试准备。Data Scientist面试有六个主题:
· Coding
· 产品
· SQL
· A / B test
· Machine Learning
· 概率(和统计的对比
https://www3.cs.stonybrook.edu/~skiena/jaialai/excerpts/node12.html)
你会注意到其中一个主题与其他主题不同(产品)。对于Data Science职位,关于技术概念和结果以及业务指标和影响的沟通至关重要。
https://medium.com/comet-ml/a-data-scientists-guide-to-communicating-results-c79a5ef3e9f1
Data science面试问题汇总:
·https://github.com/kojino/120-Data-Science-Interview-Questions
·https://github.com/iamtodor/data-science-interview-questions-and-answers
·https://hookedondata.org/red-flags-in-data-science-interviews/
·https://medium.com/@XiaohanZeng/i-interviewed-at-five-top-companies-in-silicon-valley-in-five-days-and-luckily-got-five-job-offers-25178cf74e0f
你会注意到这里包含了“Red Flags in Data Science Interviews”,当你面试时,你会遇到仍在构建数据基础架构的公司,或者可能没有更好的理解data science团队如何适合更大的公司价值。
这些公司可能仍在攀升以下的这种需求层次。
对于Data Science面试的更多内容,建议阅读Tim Hopper的文章“对很多Data Science工作被拒绝的一些反思”。
https://tdhopper.com/blog/some-reflections-on-being-turned-down-for-a-lot-of-data-science-jobs/
感谢阅读! 我们希望本指南可以帮助你了解data science是否是你应该考虑的职业以及如何开始这一职业旅程!
原文作者:Cecelia Shao
翻译作者:Yishuo Dong
美工编辑:过儿
校对审稿:冬冬





